







一 序:
- 集合,或者叫容器,是一个包含多个元素的对象;
- 集合可以对数据进行存储,检索,操作。
JDK提供了大量的集合实现供开发者使用,在java.util包下面。
1. 接口 2. 抽象类 3. 实际使用中的类

1. 最基本的是Collection接口
2. 然后是Set,List,SortedSet接口,继承于Collection接口
3. 两外的Map和SortedMap接口,其实准确而言是映射,而不是集合
二 collection主要方法:
boolean add(Object o)添加对象到集合
boolean remove(Object o)删除指定的对象
int size()返回当前集合中元素的数量
boolean contains(Object o)查找集合中是否有指定的对象
boolean isEmpty()判断集合是否为空
Iterator iterator()返回一个迭代器
boolean containsAll(Collection c)查找集合中是否有集合c中的元素
boolean addAll(Collection c)将集合c中所有的元素添加给该集合
void clear()删除集合中所有元素
void removeAll(Collection c)从集合中删除c集合中也有的元素
void retainAll(Collection c)从集合中删除集合c中不包含的元素
当然jdk1.8开始,新增了两个接口:stream(),parallelStream()。
这里补充下对应的知识点。它与 java.io 包里的 InputStream 和 OutputStream 是完全不同的概念.这里的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。
Oracle 官网的地址:https://docs.oracle.com/javase/tutorial/collections/streams/index.html
三 补充Stream
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。而和迭代器又不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。
1流使用过程
获取一个数据源(source)→ 数据转换→执行操作获取想要的结果,每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道,如下图所示。
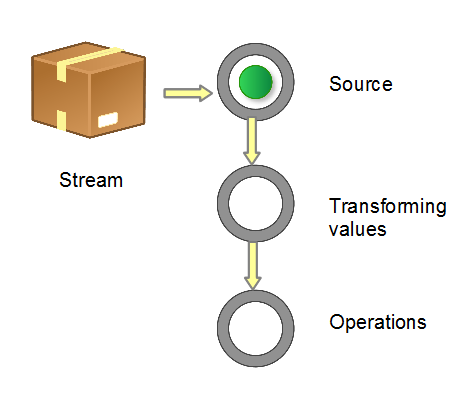
构建Stream Source有多种方式:
- 从 Collection 和数组 Collection.stream() Collection.parallelStream() Arrays.stream(T array) or Stream.of()
- 从 BufferedReader java.io.BufferedReader.lines()
- 静态工厂 java.util.stream.IntStream.range() java.nio.file.Files.walk()
2. 流的转换
构造流的几种常见方法
// 1. Individual values
Stream stream = Stream.of("a", "b", "c");
// 2. Arrays
String [] strArray = new String[] {"a", "b", "c"};
stream = Stream.of(strArray);
stream = Arrays.stream(strArray);
// 3. Collections
List<
String
> list = Arrays.asList(strArray);
stream = list.stream();
流转换为其它数据结构
// 1. Array
String[] strArray1 = stream.toArray(String[]::new);
// 2. Collection
List<
String
> list1 = stream.collect(Collectors.toList());
List<
String
> list2 = stream.collect(Collectors.toCollection(ArrayList::new));
Set set1 = stream.collect(Collectors.toSet());
Stack stack1 = stream.collect(Collectors.toCollection(Stack::new));
// 3. String
String str = stream.collect(Collectors.joining()).toString();
3 流的操作
- Intermediate:(打开操作)
map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
- Terminal:(结束操作)
forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
- Short-circuiting:(过滤返回有限结果)
anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
map
它的作用就是把 input Stream 的每一个元素,映射成 output Stream 的另外一个元素。
调出文章的单词长度>0的。
List<
String
> output = wordList.stream().
map(String::toUpperCase).
collect(Collectors.toList());
转换大写
filter
filter 对原始 Stream 进行某项测试,通过测试的元素被留下来生成一个新 Stream。
List<
String
> output = reader.lines().
flatMap(line -> Stream.of(line.split(REGEXP))).
filter(word -> word.length() > 0).
collect(Collectors.toList());
forEach
forEach 方法接收一个 Lambda 表达式,然后在 Stream 的每一个元素上执行该表达式。
tradeOrderList.stream().filter(tradeOrder -> tradeOrder.getId() != null).forEach(tradeOrder -> {
// 处理订单
dealTradeOrder(tradeOrder);
});
风格与传统的for不同。forEach 是 terminal 操作,因此它执行后,Stream 的元素就被“消费”掉了,你无法对一个 Stream 进行两次 terminal 运算。另外,不能使用break,return 提前结束循环。
findFirst
这是一个 termimal 兼 short-circuiting 操作,它总是返回 Stream 的第一个元素,或者空。这里比较重点的是它的返回值类型:Optional。通常与 orElse一起使用。
limit/skip
limit 返回 Stream 的前面 n 个元素;skip 则是扔掉前 n 个元素
sorted
对 Stream 的排序通过 sorted 进行,它比数组的排序更强之处在于你可以首先对 Stream 进行各类 map、filter、limit、skip 甚至 distinct 来减少元素数量后,再排序,这能帮助程序明显缩短执行时间。
min/max/distinct
min 和 max 的功能也可以通过对 Stream 元素先排序,再 findFirst 来实现,但前者的性能会更好,为 O(n),而 sorted 的成本是 O(n log n)。同时它们作为特殊的 reduce 方法被独立出来也是因为求最大最小值是很常见的操作。
Match
Stream 有三个 match 方法,从语义上说:
- allMatch:Stream 中全部元素符合传入的 predicate,返回 true
- anyMatch:Stream 中只要有一个元素符合传入的 predicate,返回 true
- noneMatch:Stream 中没有一个元素符合传入的 predicate,返回 true
参考:
https://www.ibm.com/developerworks/cn/java/j-lo-java8streamapi/



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











