







前面已经写过一个c++多线程调用cuda优化的文章,但是根据那种方式,在项目上尝试,发现仍然不行,其中一个库是外部库,看不到里面实现了什么,怀疑库里面有大量的cudaMemcpy,所以才会导致效果不明显,所以这个文章再整理下库中包含cudaMemcpy的情况,也是边尝试,边整理。
1. 模拟库中存在cudaMemcpy情况:
1.1. 代码段
cmake_minimum_required(VERSION 3.16)
project(demo)
find_package(CUDA REQUIRED)
set(_SRCS
main.cpp)
include_directories(include)
link_directories(F:/cudaso/build/Debug)
cuda_add_executable(demo ${_SRCS})
target_link_libraries(demo cudaso)
#include <iostream>
#include "TimeConsume.h"
#include "cudasoSrc.h"
#include <vector>
#include <thread>
int main()
{
const int arraySize = 1024;
std::vector<int> a(arraySize, 0);
std::vector<int> b(arraySize, 0);
std::vector<int> c(arraySize, 0);
for (int i = 0; i < arraySize; ++i)
{
a[i] = i;
b[i] = i;
}
std::thread th_0 = std::thread(Fun, a.data(), b.data(), c.data(), arraySize, "Thread 0");
std::thread th_1 = std::thread(Fun, a.data(), b.data(), c.data(), arraySize, "Thread 1");
th_0.join();
th_1.join();
return 0;
}cmake_minimum_required(VERSION 3.16)
project(cudaso)
find_package(CUDA REQUIRED)
# set(
# CUDA_NVCC_FLAGS ${CUDA_NVCC_FLAGS}; --default-stream per-thread
# )
add_definitions(-DCUDA_API_PER_THREAD_DEFAULT_STREAM)
set(_CUSOSRC
TimeConsume.h
cudasoSrc.h
cudasoSrc.cu
)
add_definitions(-DMYDLL)
cuda_add_library(cudaso STATIC ${_CUSOSRC})#include "cudasoSrc.h"
#include "TimeConsume.h"
#include <vector>
#include <assert.h>
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size, int *testCpy, int iTestCpYlEN);
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
for (int i = 0; i < 100000; ++i)
{
c[i] = a[i] % (b[i] + 1);
c[i] = atanf(a[i]);
}
}
void Fun(int *c, int *a, int *b, int arraySize, const char* strName)
{
int i_count = 0;
while (i_count++ < 5)
{
TimeConsume ts_loop(strName);
std::vector<int> v_test_data(1024 * 1024 * 100, 0);
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize, v_test_data.data(), v_test_data.size());
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "addWithCuda failed!");
return;
}
}
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size, int *testCpy, int testCpyLen)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
int *dev_cpy = 0;
cudaMalloc((void**)&dev_cpy, testCpyLen * sizeof(int));
cudaStatus = cudaMemcpy(dev_cpy, testCpy, testCpyLen * sizeof(int), cudaMemcpyHostToDevice);
assert(cudaSuccess == cudaStatus);
cudaFree(dev_cpy);
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
// cudaThreadSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaThreadSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}上述代码中,Fun是线程调用的主函数,其中分配了100M内存,并在addWithCuda中往显卡中拷贝:
1.2. 耗时情况:
上面代码片段已经开启CUDA_API_PER_THREAD_DEFAULT_STREAM宏定义

可以看到这个耗时,比前面一篇文章耗时大很多,使用nvvp查看:

上面标记出来的是核函数实际执行的情况,是并行执行的,但是cudaMemcpy本身,两个线程之间是串行的。
上面是两个线程,那一个线程的时间是多少呢?(下面是单个线程处理时间)


这个问题怎么解决?,最起码多个线程的耗时能优化到和单个线程齐平!!
2. 尝试优化
2.1. 提前申请显存
将现存的申请放在外部进行,且只申请一次,会发现耗时小了一些,但是仍然不满足要求


2.2. 多流异步拷贝
外围创建了2个流,并使用异步拷贝
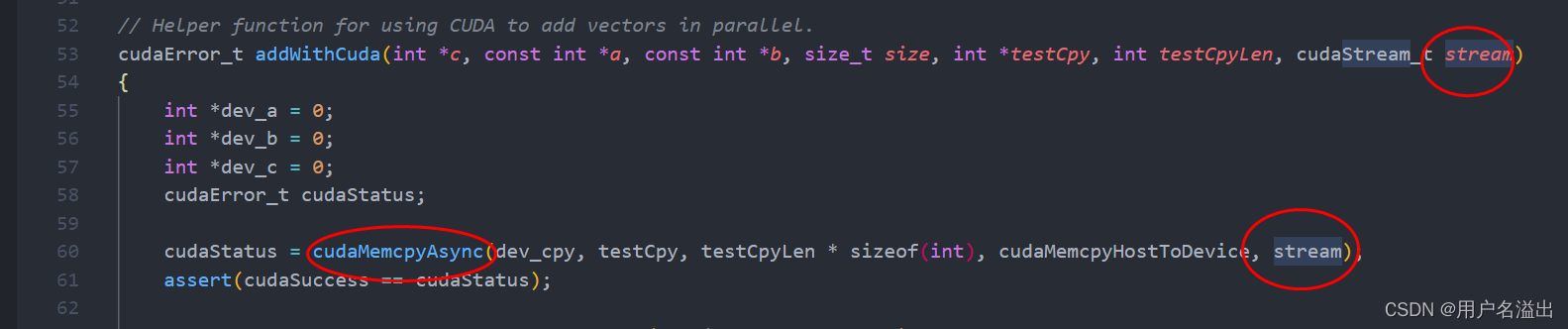
感觉没有啥用呀。。。?
可以看到nvvp中总共是4个流,那是因为核函数的执行,是默认编译选项控制的2个流,尝试将核函数的执行流放到拷贝同样的流中:

然并卵...
2.3. 使用Pinned Host Memory
这个有点惊喜
只是将外部提前申请现存的方式从cudaMalloc修改为了cudaMallocHost,且拷贝的时候,仍然是cudaMemcpy的方式
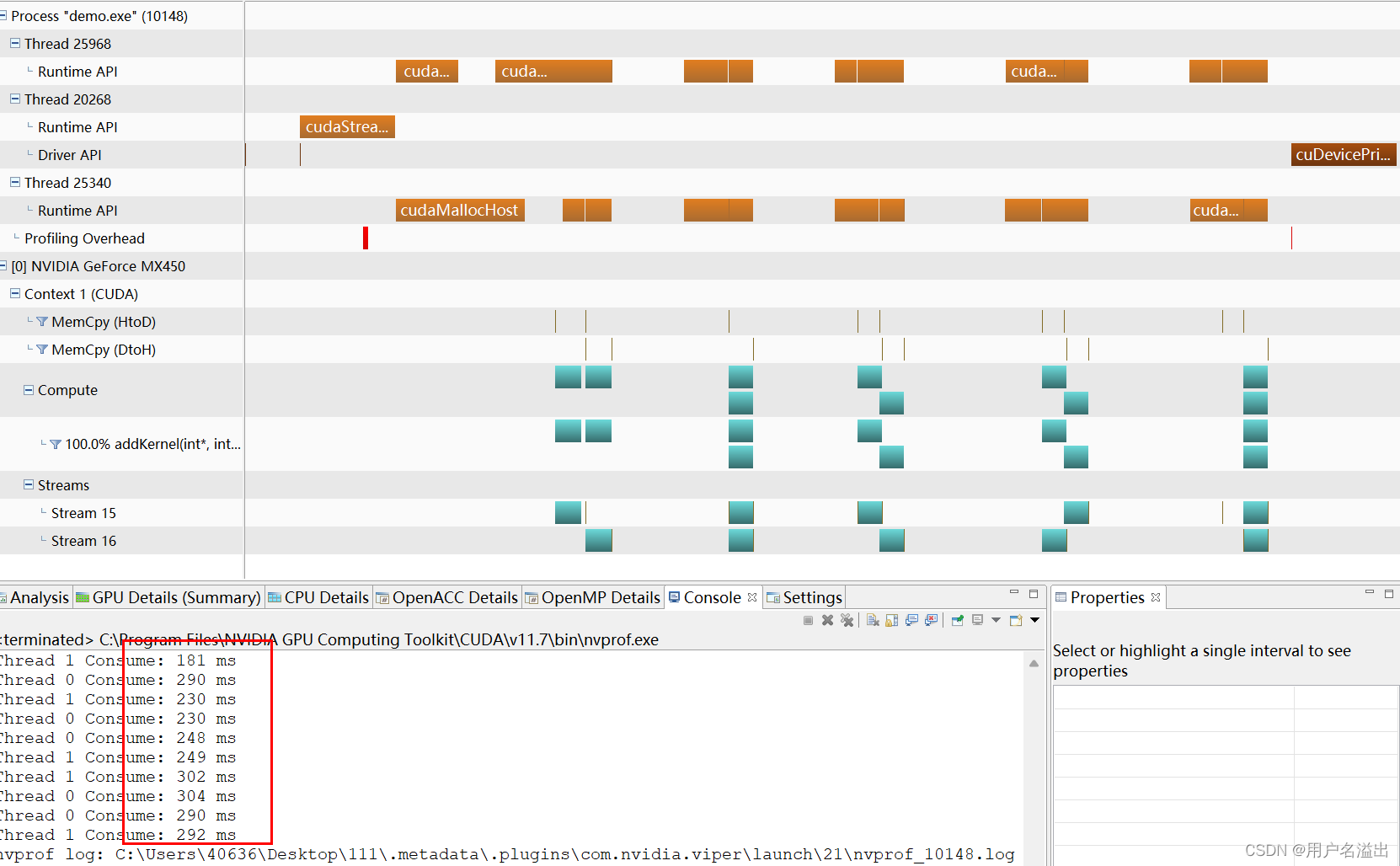
这难道就是解决之道?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









