



1. 为什么要学习YOLOV4?
- 通过学习YOLOV3这个很重要的算法, 可以学习到作者重新设计DarkNet的思想。
- YOLO系列一贯的做法是把当时在市面上比较新的东西融合进来
- 这里通过学习YOLOV4可以学习当时新增的trick
- 输入端改进: Monsaic的数据增强
- BackBone的改进: CSPDarkNet53, 这里会学习CSP思想
- Neck的改进: SSP, PANET
- 激活函数: L1/L2 是如何到IOU 再到DIOU CIOU
- 激活函数: Mish
- 样本的匹配: 如何改进了YOLOV3的正负样本匹配
2. Mosaic数据增强
2.1 Mosaic数据增强的流程
Mosaic数据增强通过随机选择4张图片并将它们拼接在一起来创建一个新的合成图像,然后对这个新的合成图像进行数据增强操作,包括翻转、缩放和色彩增强等,以增加训练集的多样性和鲁棒性。在拼接图片时,每张图片的边缘会有一定重叠,这使得模型可以学习到不同图片之间的平滑过渡。
推理时并不需要进行Mosaic数据增强操作,因为Mosaic数据增强只是一种训练技巧,旨在增加训练数据的多样性和鲁棒性。在推理阶段,模型会直接对输入图像进行预测,并输出检测结果。
Mosaic数据增强的操作流程:
- 首先随机取4张图片
- 分别对4张图片进行数据增广操作,并分别粘贴至与最终输出图像大小相等掩模的对应位置。
- 进行图片的组合和框的组合
注意:数据增广包括:翻转、缩放以及色域变化(明亮度、饱和度、色调)等操作。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NVeRtkhA-1679467701748)(null)]
2.2 马赛克数据增强的优点
- 丰富数据集:随机使用 4 张图像,随机缩放,再随机分布进行拼接,大大丰富了目标检测的数据集,特别是随机缩放增加了很多小目标,让网络模型对于小目标的稳健性变得更好。
- 减少 GPU 的使用:Mosaic 增强训练时,可以在单图像尺度的情况下直接计算 4 张图像的数据,使得 Mini-batch Size 并不需要很大,即使用 1 个 GPU 就可以达到比较好的收敛效果。
3. 激活函数的改进
越来越平滑
3.1 ReLU
ReLU(Rectified Linear Unit)是一种常用的激活函数,它的定义为f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x),即将输入信号小于0的部分设置为0,大于等于0的部分保持不变。ReLU具有简单、高效的特点,并且在深度神经网络中表现出了出色的性能,成为了目前最常用的激活函数之一。
3.2 Leakly ReLU
Leaky ReLU是对ReLU的改进,它在负半轴上引入一个较小的斜率,定义为f(x)=max(αx,x)f(x) = \max(\alpha x, x)f(x)=max(αx,x),其中α\alphaα为小于1的超参数,通常取0.1。Leaky ReLU的主要目的是解决ReLU在负半轴上的“死亡区域”问题,即在负半轴上,ReLU函数的梯度为0,导致神经元的更新停滞,影响模型的收敛性和泛化能力。
改善了模型的鲁棒性。由于Leaky ReLU在负半轴上有梯度,使得模型对于输入的微小扰动具有一定的稳定性,从而提高了模型的鲁棒性。

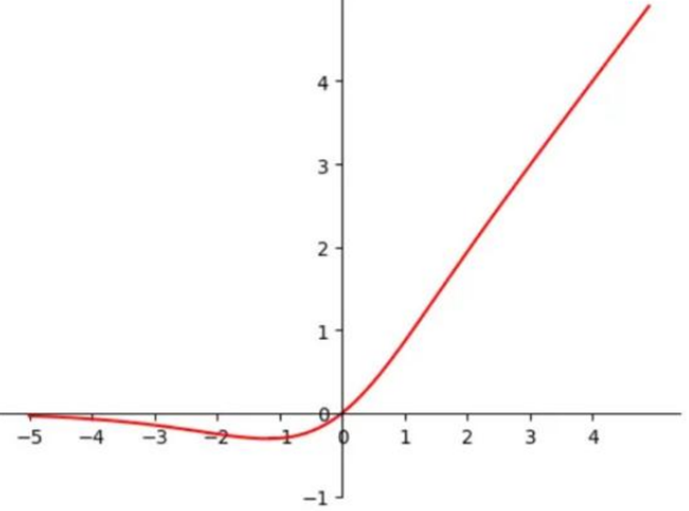
3.3 Mish
Mish是一种近年来提出的激活函数,它被认为比ReLU和Leaky ReLU表现更好。Mish的定义为f(x)=x⋅tanh(ln(1+exp(x)))f(x) = x \cdot \tanh(\ln(1+\exp(x)))f(x)=x⋅tanh(ln(1+exp(x))),它的形状类似于Softplus函数,但具有更平滑的曲线,使得它可以在激活函数中保持较好的梯度传播,从而有助于提高模型的收敛速度和泛化能力。
Mish函数和ReLU函数一样,在正半轴上都没有上限,这使得神经元可以接收更强的信号,避免了梯度饱和问题。同时,Mish函数是光滑的,有助于优化器更好地进行参数更新,提高模型的收敛速度和泛化能力。
与此同时,Mish函数的计算复杂度确实比ReLU函数要高,这也是需要注意的一个问题。在计算资源受限的情况下,可以考虑使用LeakyReLU等其他激活函数代替Mish函数,以平衡计算效率和模型性能。
4. Backbone改进的其思想
4.1 梯度流
梯度流(Gradient Flow)指的是神经网络中参数更新的梯度信息在网络中的流动过程。在神经网络中,通常使用反向传播算法来计算损失函数对网络参数的梯度信息,然后使用梯度下降等优化算法来更新网络参数。在更新参数的过程中,梯度信息通过网络的连接和计算,从输出层向输入层进行反向传播,从而更新各层的参数。
具体来说,神经网络中每个神经元的输出都会被传递到下一层的神经元中,通过计算和激活函数等操作,生成下一层的输出。在反向传播算法中,损失函数对于每个神经元的输出都有一个梯度值,该梯度值代表着该神经元对于损失函数的贡献程度。这些梯度值在反向传播过程中,会根据网络连接和计算的规则,向上一层的神经元传递,最终到达输入层,从而得到各层参数的梯度信息,用于更新参数。
梯度流的流动过程是神经网络中非常重要的一部分,它直接影响了神经网络的训练效果和收敛速度。在神经网络的设计和优化过程中,通常需要考虑如何优化梯度流的流动,以获得更好的训练效果和更快的收敛速度。
我的理解梯度分割流就是让卷积提取不同feature map的特征 因为卷积也是会反向传播传递梯度,这里传递的梯度是不同层次的
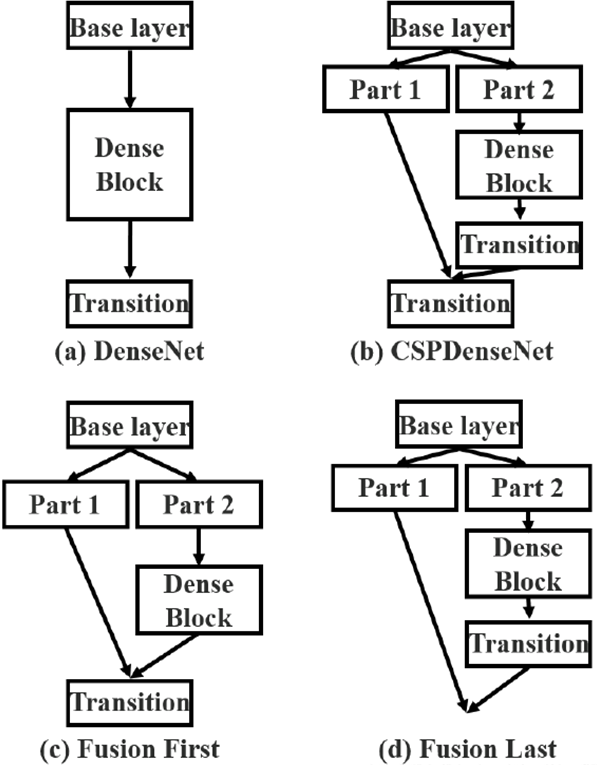
4.2 DenseNet
跟ResNet都是残差的结构, 但是实现方法是可以充分利用前面曾的特征图。相似点是将网络分为多个阶段(Stage),每个阶段由多个密集块(Dense Block)组成。
最后使用的是Avgpooling + softmax做分类
4.3 CSPDenseNet
- 设计CSPNet的主要目的是使该架构能够实现更丰富的梯度组合,同时减少计算量。这个目的是通过将基础层的特征图分割成两部分,然后通过提出的跨阶段分层(cross-stage hierarchy)结构进行合并来实现的。注意, 这里是通过Concat结合的
- 主要概念是通过分割梯度流,使梯度流在不同路径中传播。通过这种方式传播的梯度信息更加丰富。此外,CSPNet可以大大减少计算量,提高推理速度以及精度。
- 因为卷积参数共享(不同位置用同样的参数), 使用了分割流之后,中间的卷积核甚至可以提取到不同Feature Map的特征,这是为什么速度快精度还快的原因
- CSPDensetNet就是很厉害的使用了密集连接(Dense Connection)和ResNet的残差块(Residual Block),梯度分割流达到了理想的效果
- 设计Partial Transition 层的目的是使梯度组合的差异最大。Partial Transition 层是一种层次化的特征融合机制,它利用梯度流的聚合策略来防止不同的层学习重复的梯度信息。最后是通过concat完成的
- 在YOLOv4中,Transion层是由一个1x1的卷积层和一个2x2的步幅为2的平均池化层组成的。该层通过卷积操作来减少特征图中的通道数,并通过池化操作来缩小特征图的尺寸。这种方式可以有效地控制特征图的尺寸和深度,并使得模型更加轻量化和高效。
4.5 CSPDenseNet变体: Fusion First 和 Fusion Last
- Fusion First 方式,先将2个部分进行 Concat,然后再进行输入到 Transion 层中,采用这种做法会使得大量梯度信息被重用,有利于网络学习;
- Fusion Last 的方式,先将部分特征输入 Transition层,然后再进行Concat,这样梯度信息将被截断,损失了部分的梯度重用,但是由于 Transition 的输入维度比©图少,相对来说也可以减少计算复杂度。
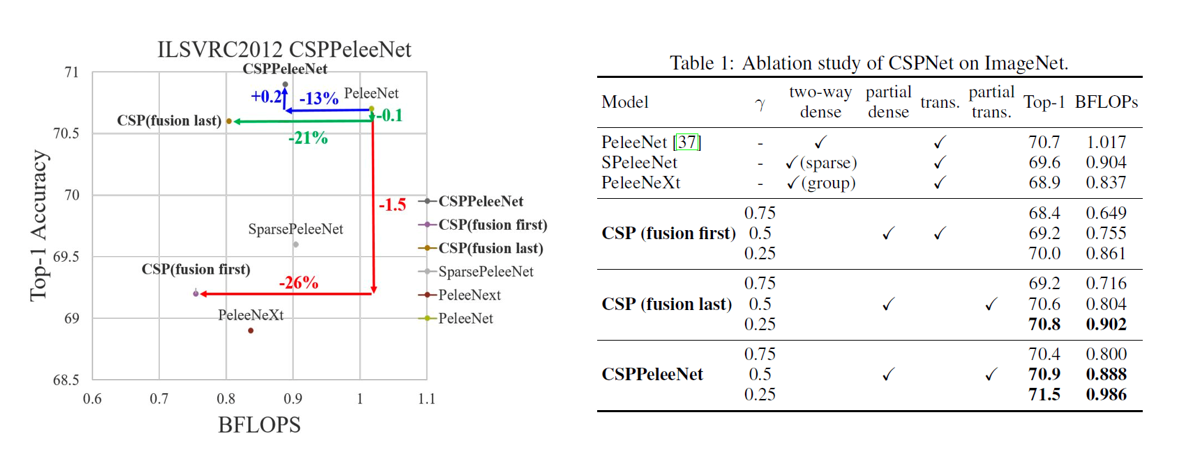
4.6 CSPNET的gamma分类
-
这里就是拿CSPNet去改进PeleeNet, 通过分配不同比例的gamma, 也就是Part1的比例
-
不同的分配会有不同的参数量和精度, 作者建议自己的实用场景去做
-
下图肯定是Part1分配的越多精度越差但是速度越快
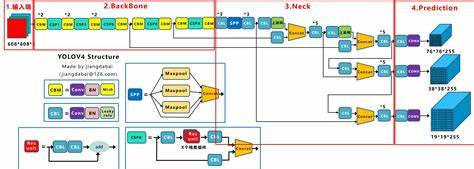
5. YOLOV4中的Backbone: CSPDarkNet中的Bottleneck
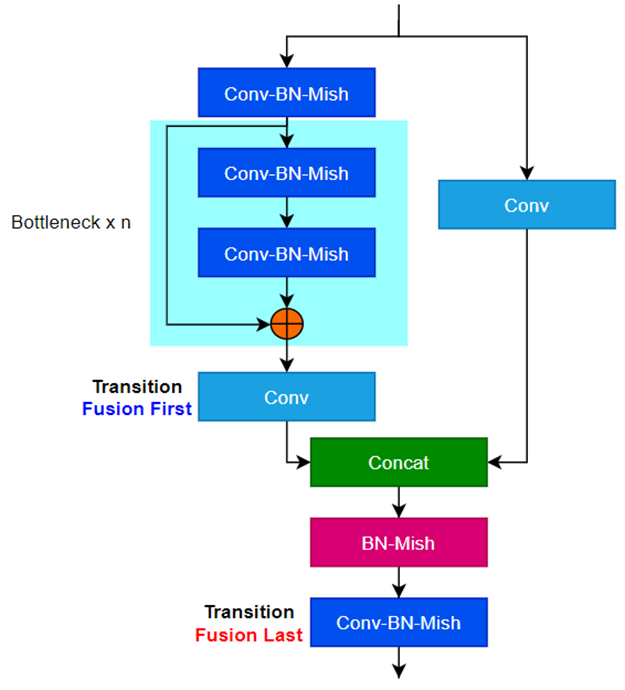
-
SPDarkNet同时使用了Fusion Last和Fusion First, 基于这种思想做出来了上面这个基本的组件
-
从这个结构图来看, 这个基本的组件还是CBA, conv + BN + Activation(Mish)
-
上面是一个Block,可以看出来上面先分割一半特征是先transition再Concat, 图是错的,last, First写反了
-
下面是先Concat再去做transition
6. 基于这个Block的Backbone
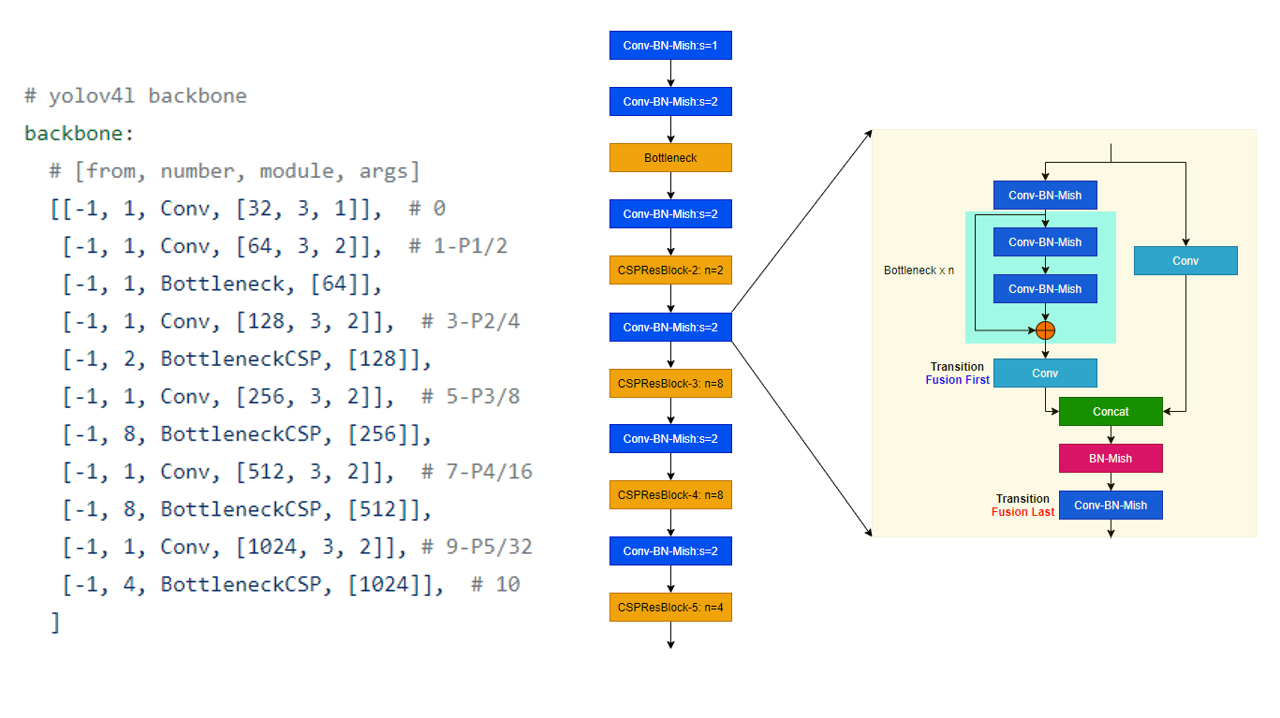
- 每一个Sstage分别是: 1, 2, 8, 8, 4分别对应2, 4, 8, 16, 32倍下采样
7. SSP结构
- 在江大白的结构图中,他被放到了Neck的开始但是在这边我们放他到backbone的末尾。因为他的作用是用来取代Backbone的最后的maxpooling。简单说就是让他接收不同尺度的特征图
- 放在backbone的最后一层其实是没有影响的。
- 由于对输入图像的不同纵横比和不同尺寸,SPP同样可以处理,所以提高了图像的尺度不变和降低了过拟合
- 实验表明训练图像尺寸的多样性比单一尺寸的训练图像更容易使得网络收敛
- 不仅可以用于图像分类而且可以用来目标检测;
因此,YOLOv4借鉴了SPP的思想,在Backbone尾部使用了SPP结构实现了局部特征和全局特征的融合,扩大了感受野,丰富最终特征图的表达能力,进而提高 mAP。
8. PAN-FPN结构
- YOLOV3中的FPN结构通过从上面往下做特征融合可以很好的改善分类,因为我们知道在大的特征图里面对分类不友好但是对定位是有好的
- 我们现在做的事情就是在FPN层后面加上了PAN层,从下往上走, 这样也把更好的定位信息共享给更高层次(更小的)特征图
9. 正负样本匹配
-
V4最多可以产生9个正样本但是V3只能最多3个,每个尺度一个正样本 三个层就是说8倍下采样, 16倍下采样, 32倍速下采样
-
只要大于IoU阈值的anchor box,都统统视作正样本,换言之,那些原本在YOLOv3中会被忽略掉的样本,在YOLOv4中则统统成为了正样本
10. 损失函数
- L1/L2smoothing -> IOU -> DIOU -> CIOU
- 一开始的损失大家都是拿L1/L2,后面发现还是直接上IOU好了
10.1 L1
L1损失(也称为绝对误差)是将预测值与真实值之间的差值(即误差)取绝对值后求和得到的。数学公式为:L1=∑i=1n∣yi−yi^∣L1 = \sum_{i=1}^{n} |y_i - \hat{y_i}|L1=∑i=1n∣yi−yi^∣,其中yiy_iyi是真实值,yi^\hat{y_i}yi^是模型预测值,n是数据样本的数量。L1损失对于异常值(outlier)比较敏感,容易受到离群点的影响。
10.2 l2
L2损失(也称为均方误差)是将预测值与真实值之间的差值平方后求和得到的。数学公式为:L2=∑i=1n(yi−yi^)2L2 = \sum_{i=1}^{n} (y_i - \hat{y_i})^2L2=∑i=1n(yi−yi^)2,其中yiy_iyi是真实值,yi^\hat{y_i}yi^是模型预测值,n是数据样本的数量。与L1损失相比,L2损失对于异常值不太敏感。
11. IOU的背景
- 本文试图让您明白IOU和一些扩展复现出来加深您的理解
- IOU的发展史: L1Loss/L2Loss -> SmoothL1Loss -> IoULoss -> GIoULoss -> CIoU/DIoULoss
SmoothL1
- 最早我们使用L1loss或者L2Loss来做做boundingbox误差回归的loss函数
Faster-Rcnn作者发现
- 当误差比较大时,L2Loss容易出现梯度爆炸(平方)造成训练的不稳定,原因有可能是脏数据
- 当误差比较小时,L1Loss的梯度是常量值1,本身已经接近真值,梯度为1太- 大,容易出现在0点周围震荡
- 而误差大时,使用L1Loss梯度为1,能够稳定训练过程。误差小时,L2Loss的梯度为2x,随着误差变小而变小,接近真值时梯度也很小,更适合使用L2Loss针对误差小的情况
- 结合二者,其结果就是SmoothL1Loss干的事情
- Loss定义为:
相关公式
- loss(x,y)=1n∑izi loss(x, y) = \frac{1}{n}\sum_{i} {z_i} loss(x,y)=n1i∑zi
- 这里的ZiZ_iZi取值为:
zi={0.5(xi−yi)2,if ∣xi−yi∣<1∣xi−yi∣−0.5,otherwise z_{i} = \begin{cases} 0.5 (x_i - y_i)^2, & \text{if } |x_i - y_i| < 1 \\ |x_i - y_i| - 0.5, & \text{otherwise } \end{cases} zi={0.5(xi−yi)2,∣xi−yi∣−0.5,if ∣xi−yi∣<1otherwise
- 后面大家发现直接算IOU Loss来的更加直接,后面搞出GIOU, CIOU
python 魔术方法的回顾
add(self, other) 定义加法的行为:+
sub(self, other) 定义减法的行为:-
mul(self, other) 定义乘法的行为:*
truediv(self, other) 定义真除法的行为:/
floordiv(self, other) 定义整数除法的行为://
mod(self, other) 定义取模算法的行为:%
divmod(self, other) 定义当被 divmod() 调用时的行为
pow(self, other[, modulo]) 定义当被 power() 调用或 ** 运算时的行为
lshift(self, other) 定义按位左移位的行为:<<
rshift(self, other) 定义按位右移位的行为:>>
and(self, other) 定义按位与操作的行为:&
xor(self, other) 定义按位异或操作的行为:^
or(self, other) 定义按位或操作的行为:|
boundingbox python 代码 (by Hope)
import math
def euclidean_distance(p1, p2):
'''
计算两个点的欧式距离
'''
x1, y1 = p1
x2, y2 = p2
return math.sqrt((x2 - x1) ** 2 + (y2 - y1) ** 2)
class BBox:
def __init__(self, x, y, r, b):
self.x, self.y, self.r, self.b = x, y, r, b
def __xor__(self, other):
'''
计算box和other的IoU
'''
cross = self & other
union = self | other
return cross / (union + 1e-6)
def __or__(self, other):
'''
计算box和other的并集
'''
cross = self & other
union = self.area + other.area - cross
return union
def __and__(self, other):
'''
计算box和other的交集
'''
xmax = min(self.r, other.r)
ymax = min(self.b, other.b)
xmin = max(self.x, other.x)
ymin = max(self.y, other.y)
return BBox(xmin, ymin, xmax, ymax).area
def boundof(self, other):
'''
计算box和other的边缘外包框,使得2个box都在框内的最小矩形
'''
xmin = min(self.x, other.x)
ymin = min(self.y, other.y)
xmax = max(self.r, other.r)
ymax = max(self.b, other.b)
return BBox(xmin, ymin, xmax, ymax)
def center_distance(self, other):
'''
计算两个box的中心点距离
'''
return euclidean_distance(self.center, other.center)
def bound_diagonal_distance(self, other):
'''
计算两个box的bound的对角线距离
'''
bound = self.boundof(other)
return euclidean_distance((bound.x, bound.y), (bound.r, bound.b))
@property
def center(self):
return (self.x + self.r) / 2, (self.y + self.b) / 2
@property
def area(self):
return self.width * self.height
@property
def width(self):
return self.r - self.x
@property
def height(self):
return self.b - self.y
def __repr__(self):
return f"{self.x}, {self.y}, {self.r}, {self.b}"
IOU实现
- IOU(交并比)是指预测边界框与真实边界框相交部分与预测边界框与真实边界框并集的比例。这是一种常用于目标检测的度量,值接近1表示预测边界框与真实边界框有较好的重叠。

def IoU(a, b):
return a ^ b
a = BBox(10, 10, 100, 200)
b = BBox(50, 50, 150, 180)
IoU(a, b)
实现GIOU
GIoU(广义交并比)是IOU的扩展,它还考虑了预测边界框和真实边界框并集以外的区域。这有助于提高度量的准确性,当边界框的大小或形状显着不同时。

def GIoU(a, b):
bound_area = a.boundof(b).area
union_area = a | b
return IoU(a, b) - (bound_area - union_area) / bound_area
GIoU(a, b)
实现DIOU
- DIoU(距离交并比)类似于IOU,但它还考虑了预测边界框和真实边界框的中心点之间的距离。当边界框远离时,这有助于提高度量的准确性。

def DIoU(a, b):
d = a.center_distance(b)
c = a.bound_diagonal_distance(b)
return IoU(a, b) - (d ** 2) / (c ** 2)
DIoU(a, b)
实现CIOU
- (完整交并比)是IOU的扩展,它还考虑了边界框的大小和形状。它旨在对边界框的尺度和宽高比变化更加稳健。

def CIoU(a, b):
v = 4 / (math.pi ** 2) * (math.atan(a.width / a.height) - math.atan(b.width / b.height)) ** 2
iou = IoU(a, b)
alpha = v / (1 - iou + v)
return DIoU(a, b) - alpha * v
CIoU(a, b)
总的来说,这些度量有助于评估目标检测算法的性能,并且可以用于比较不同目标检测方法的结果。


















 7005
7005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









