




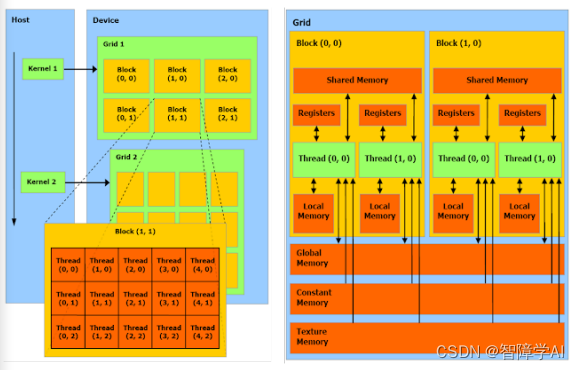
1. CUDA中的grid和block基本的理解
-
Kernel: Kernel不是CPU,而是在GPU上运行的特殊函数。你可以把Kernel想象成GPU上并行执行的任务。当你从主机(CPU)调用Kernel时,它在GPU上启动,并在许多线程上并行运行。
-
Grid: 当你启动Kernel时,你会定义一个网格(grid)。网格是一维、二维或三维的,代表了block的集合。
-
Block: 每个block内部包含了许多线程。block也可以是一维、二维或三维的。
-
Thread: 每个线程是Kernel的单个执行实例。在一个block中的所有线程可以共享一些资源,并能够相互通信。
你正确地指出,grid、block和thread这些概念在硬件级别上并没有直接对应的实体,它们是抽象的概念,用于组织和管理GPU上的并行执行。然而,GPU硬件是专门设计来支持这种并行计算模型的,所以虽然线程在物理硬件上可能不是独立存在的,但是它们通过硬件架构和调度机制得到了有效的支持。
另外,对于线程的管理和调度,GPU硬件有特定的线程调度单元,如NVIDIA的warp概念。线程被组织成更小的集合,称为warps(在NVIDIA硬件上),并且这些warps被调度到硬件上以供执行。
所以,虽然这些概念是逻辑和抽象的,但它们与硬件的实际执行密切相关,并由硬件特性和架构直接支持。
一般来说:
• 一个kernel对应一个grid
• 一个grid可以有多个block,一维~三维
• 一个block可以有多个thread,一维~三维
1.1. 1D traverse
void print_one_dim(){
int inputSize = 8;
int blockDim = 4;
int gridDim = inputSize / blockDim; // 2
// 定义block和grid的维度
dim3 block(blockDim); // 说明一个block有多少个threads
dim3 grid(gridDim); // 说明一个grid里面有多少个block
/* 这里建议大家吧每一函数都试一遍*/
print_idx_kernel<<<grid, block>>>();
// print_dim_kernel<<<grid, block>>>();
// print_thread_idx_per_block_kernel<<<grid, block>>>();
// print_thread_idx_per_grid_kernel<<<grid, block>>>();
cudaDeviceSynchronize();
}
我觉得重点在这两行
-
dim3 block(blockDim);: 这一行创建了一个三维向量block,用来定义每个block的大小。在这个例子中,blockDim是一个整数值4,所以每个block包含4个线程。dim3数据类型是CUDA中的一个特殊数据类型,用于表示三维向量。在这个情况下,你传递了一个整数值,所以block的其余维度将被默认设置为1。这意味着你将有一个包含4个线程的一维block。 -
dim3 grid(gridDim);: 这一行创建了一个三维向量grid,用来定义grid的大小。gridDim的计算基于输入大小(inputSize)和每个block的大小(blockDim)。在这个例子中,inputSize是8,blockDim是4,所以gridDim会是2。这意味着整个grid将包含2个block。与block一样,你传递了一个整数值给grid,所以其余维度将被默认设置为1,得到一个一维grid。
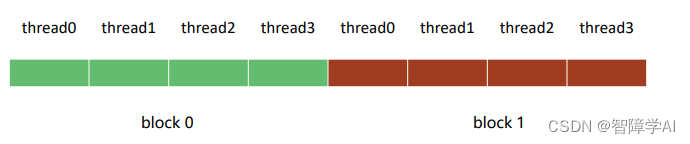
总体来说,这两行代码定义了内核的执行配置,将整个计算空间划分为2个block,每个block包含4个线程。你可以想象这个配置如下:
- Block 0: 线程0, 线程1, 线程2, 线程3
- Block 1: 线程4, 线程5, 线程6, 线程7
然后,当你调用内核时,这些线程将被用来执行你的代码。每个线程可以通过其线程索引和block索引来访问自己在整个grid中的唯一位置。这些索引用于确定每个线程应处理的数据部分。
block idx: 1, thread idx in block: 0, thread idx: 4
block idx: 1, thread idx in block: 1, thread idx: 5
block idx: 1, thread idx in block: 2, thread idx: 6
block idx: 1, thread idx in block: 3, thread idx: 7
block idx: 0, thread idx in block: 0, thread idx: 0
block idx: 0, thread idx in block: 1, thread idx: 1
block idx: 0, thread idx in block: 2, thread idx: 2
block idx: 0, thread idx in block: 3, thread idx: 3
1.2 2D打印
// 8个线程被分成了两个
void print_two_dim(){
int inputWidth = 4;
int blockDim = 2;
int gridDim = inputWidth / blockDim;
dim3 block(blockDim, blockDim);
dim3 grid(gridDim, gridDim);
/* 这里建议大家吧每一函数都试一遍*/
// print_idx_kernel<<<grid, block>>>();
// print_dim_kernel<<<grid, block>>>();
// print_thread_idx_per_block_kernel<<<grid, block>>>();
print_thread_idx_per_grid_kernel<<<grid, block>>>();
cudaDeviceSynchronize();
}
-
dim3 block(blockDim, blockDim);: 这里创建了一个二维的block,每个维度的大小都是blockDim,在这个例子中是2。因此,每个block都是2x2的,包含4个线程。由于dim3定义了一个三维向量,没有指定的第三维度会默认为1。 -
dim3 grid(gridDim, gridDim);: 同样,grid也被定义为二维的,每个维度的大小都是gridDim。由于inputWidth是4,并且blockDim是2,所以gridDim会是2。因此,整个grid是2x2的,包括4个block。第三维度同样默认为1。
因此,整个执行配置定义了2x2的grid,其中包括4个2x2的block,总共16个线程。你可以将整个grid可视化如下:
-
Block (0,0):
- 线程(0,0), 线程(0,1)
- 线程(1,0), 线程(1,1)
-
Block (0,1):
- 线程(2,0), 线程(2,1)
- 线程(3,0), 线程(3,1)
-
Block (1,0):
- 线程(4,0), 线程(4,1)
- 线程(5,0), 线程(5,1)
-
Block (1,1):
- 线程(6,0), 线程(6,1)
- 线程(7,0), 线程(7,1)
输出中的“block idx”是整个grid中block的线性索引,而“thread idx in block”是block内线程的线性索引。最后的“thread idx”是整个grid中线程的线性索引。
请注意,执行的顺序仍然是不确定的。你看到的输出顺序可能在不同的运行或不同的硬件上有所不同。
block idx: 3, thread idx in block: 0, thread idx: 12
block idx: 3, thread idx in block: 1, thread idx: 13
block idx: 3, thread idx in block: 2, thread idx: 14
block idx: 3, thread idx in block: 3, thread idx: 15
block idx: 2, thread idx in block: 0, thread idx: 8
block idx: 2, thread idx in block: 1, thread idx: 9
block idx: 2, thread idx in block: 2, thread idx: 10
block idx: 2, thread idx in block: 3, thread idx: 11
block idx: 1, thread idx in block: 0, thread idx: 4
block idx: 1, thread idx in block: 1, thread idx: 5
block idx: 1, thread idx in block: 2, thread idx: 6
block idx: 1, thread idx in block: 3, thread idx: 7
block idx: 0, thread idx in block: 0, thread idx: 0
block idx: 0, thread idx in block: 1, thread idx: 1
block idx: 0, thread idx in block: 2, thread idx: 2
block idx: 0, thread idx in block: 3, thread idx: 3
1.3 3D grid
dim3 block(3, 4, 2);
dim3 grid(2, 2, 2);
-
Block布局 (
dim3 block(3, 4, 2)):- 这定义了每个block的大小为3x4x2,所以每个block包含24个线程。
- 你可以将block视为三维数组,其中
x方向有3个元素,y方向有4个元素,z方向有2个元素。
-
Grid布局 (
dim3 grid(2, 2, 2)):- 这定义了grid的大小为2x2x2,所以整个grid包含8个block。
- 你可以将grid视为三维数组,其中
x方向有2个元素,y方向有2个元素,z方向有2个元素。 - 由于每个block包括24个线程,所以整个grid将包括192个线程。
整体布局可以视为8个3x4x2的block,排列为2x2x2的grid。
如果我们想用文字来表示整个结构,可能会是这样的:
- Grid[0][0][0]:
- Block(3, 4, 2) – 24个线程
- Grid[0][0][1]:
- Block(3, 4, 2) – 24个线程
- Grid[0][1][0]:
- Block(3, 4, 2) – 24个线程
- Grid[0][1][1]:
- Block(3, 4, 2) – 24个线程
- Grid[1][0][0]:
- Block(3, 4, 2) – 24个线程
- Grid[1][0][1]:
- Block(3, 4, 2) – 24个线程
- Grid[1][1][0]:
- Block(3, 4, 2) – 24个线程
- Grid[1][1][1]:
- Block(3, 4, 2) – 24个线程
这种三维结构允许在物理空间中进行非常自然的映射,尤其是当你的问题本身就具有三维的特性时。例如,在处理三维物理模拟或体素数据时,这种映射可能非常有用。
5. 通过维度打印出来对应的thread

比较推荐的打印方式
__global__ void print_cord_kernel(){
int index = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
printf("block idx: (%3d, %3d, %3d), thread idx: %3d, cord: (%3d, %3d)\n",
blockIdx.z, blockIdx.y, blockIdx.x,
index, x, y);
}
index是线程索引的问题,首先,考虑z维度。对于每一层z,都有blockDim.x * blockDim.y个线程。所以threadIdx.z乘以该数量给出了前面层中的线程总数,从图上看也就是越过了多少个方块
然后,考虑y维度。对于每一行y,都有blockDim.x个线程。所以threadIdx.y乘以该数量给出了当前层中前面行的线程数,也就是在当前方块的xy面我们走了几个y, 几行
最后加上thread x完成索引的坐标
void print_cord(){
int inputWidth = 4;
int blockDim = 2;
int gridDim = inputWidth / blockDim;
dim3 block(blockDim, blockDim);
dim3 grid(gridDim, gridDim);
print_cord_kernel<<<grid, block>>>();
// print_thread_idx_per_grid_kernel<<<grid, block>>>();
cudaDeviceSynchronize();
}
block idx: ( 0, 1, 0), thread idx: 0, cord: ( 0, 2)
block idx: ( 0, 1, 0), thread idx: 1, cord: ( 1, 2)
block idx: ( 0, 1, 0), thread idx: 2, cord: ( 0, 3)
block idx: ( 0, 1, 0), thread idx: 3, cord: ( 1, 3)
block idx: ( 0, 1, 1), thread idx: 0, cord: ( 2, 2)
block idx: ( 0, 1, 1), thread idx: 1, cord: ( 3, 2)
block idx: ( 0, 1, 1), thread idx: 2, cord: ( 2, 3)
block idx: ( 0, 1, 1), thread idx: 3, cord: ( 3, 3)
block idx: ( 0, 0, 1), thread idx: 0, cord: ( 2, 0)
block idx: ( 0, 0, 1), thread idx: 1, cord: ( 3, 0)
block idx: ( 0, 0, 1), thread idx: 2, cord: ( 2, 1)
block idx: ( 0, 0, 1), thread idx: 3, cord: ( 3, 1)
block idx: ( 0, 0, 0), thread idx: 0, cord: ( 0, 0)
block idx: ( 0, 0, 0), thread idx: 1, cord: ( 1, 0)
block idx: ( 0, 0, 0), thread idx: 2, cord: ( 0, 1)
block idx: ( 0, 0, 0), thread idx: 3, cord: ( 1, 1)
跟之前2D的一样, 同样看起来有点乱,是因为是异步执行的
1.4 最后看一个多个grid的案例
void print_coordinates() {
dim3 block(3, 4, 2);
dim3 grid(2, 2, 2);
print_cord_kernel<<<grid, block>>>();
cudaDeviceSynchronize(); // 确保内核完成后才继续执行主机代码
}
block idx: ( 0, 1, 0), thread idx: 0, cord: ( 0, 4)
block idx: ( 0, 1, 0), thread idx: 1, cord: ( 1, 4)
block idx: ( 0, 1, 0), thread idx: 2, cord: ( 2, 4)
block idx: ( 0, 1, 0), thread idx: 3, cord: ( 0, 5)
block idx: ( 0, 1, 0), thread idx: 4, cord: ( 1, 5)
block idx: ( 0, 1, 0), thread idx: 5, cord: ( 2, 5)
block idx: ( 0, 1, 0), thread idx: 6, cord: ( 0, 6)
block idx: ( 0, 1, 0), thread idx: 7, cord: ( 1, 6)
block idx: ( 0, 1, 0), thread idx: 8, cord: ( 2, 6)
block idx: ( 0, 1, 0), thread idx: 9, cord: ( 0, 7)
block idx: ( 0, 1, 0), thread idx: 10, cord: ( 1, 7)
block idx: ( 0, 1, 0), thread idx: 11, cord: ( 2, 7)
block idx: ( 0, 1, 0), thread idx: 12, cord: ( 0, 4)
block idx: ( 0, 1, 0), thread idx: 13, cord: ( 1, 4)
block idx: ( 0, 1, 0), thread idx: 14, cord: ( 2, 4)
block idx: ( 0, 1, 0), thread idx: 15, cord: ( 0, 5)
block idx: ( 0, 1, 0), thread idx: 16, cord: ( 1, 5)
block idx: ( 0, 1, 0), thread idx: 17, cord: ( 2, 5)
block idx: ( 0, 1, 0), thread idx: 18, cord: ( 0, 6)
block idx: ( 0, 1, 0), thread idx: 19, cord: ( 1, 6)
block idx: ( 0, 1, 0), thread idx: 20, cord: ( 2, 6)
block idx: ( 0, 1, 0), thread idx: 21, cord: ( 0, 7)
block idx: ( 0, 1, 0), thread idx: 22, cord: ( 1, 7)
block idx: ( 0, 1, 0), thread idx: 23, cord: ( 2, 7)
block idx: ( 1, 1, 1), thread idx: 0, cord: ( 3, 4)
block idx: ( 1, 1, 1), thread idx: 1, cord: ( 4, 4)
block idx: ( 1, 1, 1), thread idx: 2, cord: ( 5, 4)
block idx: ( 1, 1, 1), thread idx: 3, cord: ( 3, 5)
block idx: ( 1, 1, 1), thread idx: 4, cord: ( 4, 5)
block idx: ( 1, 1, 1), thread idx: 5, cord: ( 5, 5)
block idx: ( 1, 1, 1), thread idx: 6, cord: ( 3, 6)
block idx: ( 1, 1, 1), thread idx: 7, cord: ( 4, 6)
block idx: ( 1, 1, 1), thread idx: 8, cord: ( 5, 6)
block idx:  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









