 中文图像文字识别系统实现
中文图像文字识别系统实现




摘 要
科技与互联网快速发展背景下,文字作为信息交流核心展现丰富多样性传统的纸质书写不再是信息流传的唯一途径,街道指示牌,电子显示屏以及广告牌等新媒介,大量承载着丰富的文字信息,这些信息常以图像形式出现在我们周边的环境里。于是,利用计算机技术达成对图像里文字内容的自动识别,该技术渐渐成了推进社会生活便捷化的关键所在。
本文针对计算机视觉领域的目标检测和识别,尤其是自然图像中文字要素检测识别的问题,鉴于图像文字由于多角度、字体多样以及复杂的背景等特性,整个识别过程包括对文字区域识别和对文字内容的分析过程两部分。文中相应介绍相关理论和知识,包括机器学习的基本概念,深度学习的基本知识和神经网络模型。本文基于Tensorflow框架、Django框架和MySQL数据库实现一种高效的识别系统的中文字符识别系统,该系统解决复杂场景中文手写体字符和印刷体字符的识别问题,以卷积神经网络为主要模型进行多卷积池化和全连接完成字符的特征提取与分类,Tensorflow框架提供模型的训练和推理优化,通过数据增强(旋转、对比度变化)来强化模型的泛化能力和应用迁移学习在较小规模标注数据下获得了较好的识别准确率。
目 录
第1章 绪论
1.1 研究背景与意义
近年来,深度学习通过深度特征学习大幅提升对图像的识别性能。采用卷积网络(ConvolutionalNeuralNetworks,CNN)进行图像分类和目标定位等学习的成功,也带来文字识别的新思路。基于深度学习的文字识别模型,如CRNN、Attention-OCR,利用端对端的训练方式能够直接将输入映射为序列输出(字符序列),取代了传统的特征工程和复杂的预处理等步骤。但基于深度学习的文字识别仍然面临以下问题:(1)由于大量标注数据获得难度大,尤其是在获取标注的手写汉字方面,它需要标注不同时代风格的文字以及不同书写质量的文本;(2)模型需要同时处理字符的检测和识别过程,对长文本序列的前后联系的依赖建模能力要求更高;(3)实际应用中的文字识别需要兼顾识别速度和精确性,这就要求轻量化的模型设计。
1.2 国内外研究现状
汉字识别是图像识别和模式识别领域的重要研究课题。多年来,日常生活类的汉字手写体识别率已经达到了90%以上[1]。书法汉字识别研究起步晚、进展慢,但是已经有了相关研究成果。浙江大学硕士生顾刚在其论文《汉字识别关键算法研究与应用》中提出了用卷积神经网络的方法进行书法字识别的方法:先用计算机中书法字的标准字库和汉字图书的字库对卷积神经网络模型进行训练,判断待识别图像的字体风格,然后用MQDF算法在相匹配的字体的特征库中进行识别[2]。分析了卷积神经网络所提取的图像深度特征,在书法字体的识别速度以及效率上有着明显的优势;西安理工的张福成在其硕士论文《基于卷积神经网络的书法风格识别的研究》和温佩芝等在其期刊论文《基于卷积神经网络的石刻书法字识别方法》中研究了书法风格以及字体的识别方法[3]。但是该类研究主要针对于计算机中的书法字标准字库或者是石刻书法图像的识别,并未解决手写书法字体的识别问题[4]。
1.3 研究内容
本文主要着眼于基于深度学习的中文字符识别系统构建,主要包括算法开发和系统实施2部分。在算法部分,采用基于TensorFlow框架的卷积神经网络模型进行设计,并从对汉字的结构特点进行网络设计:引入多尺度卷积层提高局部特征的表达能力,以及批归一化层和Dropout层,缓解过拟合问题。结合卷积循环神经网络(ConvolutionalRecurrentNeuralNetwork,CRNN)框架结构将卷积神经网络得到的视觉特征融合在一起,实现端对端的汉字序列识别。利用数据增强的方法(随机旋转、随机亮度、弹性变形),对数据进行扩充训练集训练模型,在目标场景下做微调。
在框架构建方面,用Django实现Web的后端开发,构造RESTfulWeb服务API,实现用户的图片上传、模型选择、结果输出等功能;在前端,实现图片的实时可视化、识别结果可视化;在后端利用Celery构建异步任务,对输入的识别任务进行异步处理,提高处理高并发的功能性响应效率。利用MySQL数据库实现关系表,通过创建表之间的相互关联实现用户信息、历史记录、模型版本等相关数据的表结构设置,并对表的特征字段进行索引优化和查询的缓存,保证较快的读写速度。
第2章 相关理论与技术基础
2.1 深度学习算法
卷积神经网络主要是为了图像数据而提出的一种神经网络结构。计算机视觉的大部分都是采用卷积神经网络的模型,无论是对于图像识别,还是目标检测与分割的问题,几乎所有相关的学术比赛和商业使用,都是采用了这种卷积网络模型。
2.2 Django框架
Django模板引擎与echarts进行联动渲染实现;在视图层(View)中利用分层架构设计实现,对外提供RESTful接口调用旅游APP,对外响应时间在500ms以内。最终系统上线后预测正确率达到80%以上,较传统方法高出20个百分点。
第3章 系统分析
3.1 需求分析
本功能需求主要包括用户、图像、模型、性能和数据安全五部分,其中,针对用户的管理需实现注册登录、用户权限和用户认证功能,保证用户的不同访问权限;图像的管理包括针对图像的上传、实时识别与查询历史记录,其中,图像识别结果的准确率要保证在80%以上,并输出结构化的文本信息。
3.2 可行性分析
3.2.1 技术可行性
3.2.2 经济可行性
3.2.3 社会可行性
3.3 用例分析
3.3.1 登录注册功能
根据表3.1列出的测试用例描述,用户可以在系统登录页面输入正确的用户名和密码,以完成登录。
表3.1 登录功能测试用例
| 描述项目 | 说明 |
| 用例名称 | 系统用户登录 |
| 标识符 | 201 |
| 用例描述 | 阐述用户登录流程 |
| 参与者 | 已经注册成功的用户 |
| 前置条件 | 用户名和密码输入正确的才能继续 |
| 后置条件 | 在后续步骤中,如登录成功,跳转到系统界面 |
| 基本操作流程 | 基础步骤操作流程包括登陆系统前端页面,输入用户名和密码以确认身份,然后点击登录 |
| 分支流程 | 如果登录出现错误,就无法进入系统 |
| 异常流程 | 由用户名或密码错误,所以无法进行正常的操作 |
根据表3.2中的描述,用户可通过系统注册页面输入用户名和密码来完成注册操作,系统中尚未注册的用户可利用该功能注册。
表3.2 注册功能测试用例
| 描述项目 | 说明 |
| 用例名称 | 访客注册 |
| 标识符 | 201 |
| 用例描述 | 这个测试用例是新用户注册功能,访客注册新的账号的所有步骤 |
| 参与者 | 未注册的访客 |
| 前置条件 | 输入未被注册的用户名 |
| 后置条件 | 注册成功自动跳转至登录页 |
| 基本操作流程 | 打开系统的注册页面。填写用户名和密码,提交请求 |
续表3.2 注册功能测试用例
| 描述项目 | 说明 |
| 分支流程 | 注册页面无法访问 |
| 异常流程 | 输入已注册用户名,系统提示重复并阻止注册 |
3.3.2 用户管理功能
按照表3.3中的测试用例描述,登录系统的用户可以在用户管理界面管理其账号和密码信息。
表3.3 用户管理功能测试用例
| 描述项目 | 说明 |
| 用例名称 | 用户账户信息维护 |
| 标识符 | 201 |
| 用例描述 | 执行账户信息及密码修改操作 |
| 参与者 | 通过认证的注册用户 |
| 前置条件 | 系统有效登录状态 |
| 后置条件 | 显示修改操作完成反馈信息 |
| 基本操作流程 | 访问用户管理界面,填写并提交信息表单 |
| 分支流程 | 密码输入错误、原始认证信息不匹配场景处理 |
| 异常流程 | 新密码与二次确认内容不一致导致操作终止 |
3.3.3 文字识别功能
表3. 4展示了用户在系统中执行文字识别功能的实例,登录后,用户可以查阅到系统内的文字识别结果。
表3.4 文字识别功能测试用例
| 描述项目 | 说明 |
| 用例名称 | 文字识别 |
| 标识符 | 201 |
| 用例描述 | 执行文字识别界面访问及操作 |
| 参与者 | 通过身份验证的系统用户 |
| 前置条件 | 数据源配置完成且可用 |
| 后置条件 | 显示识别结果 |
续表3.4 文字识别功能测试用例
| 描述项目 | 说明 |
| 基本流程 |
|
| 异常流程 | 数据源链接中断导致界面无数据渲染 |
3.4 非功能性需求分析
系统非功能需求分析主要对中文识别系统的性能需求、可靠性需求和保护性需求以满足系统的用户体验。
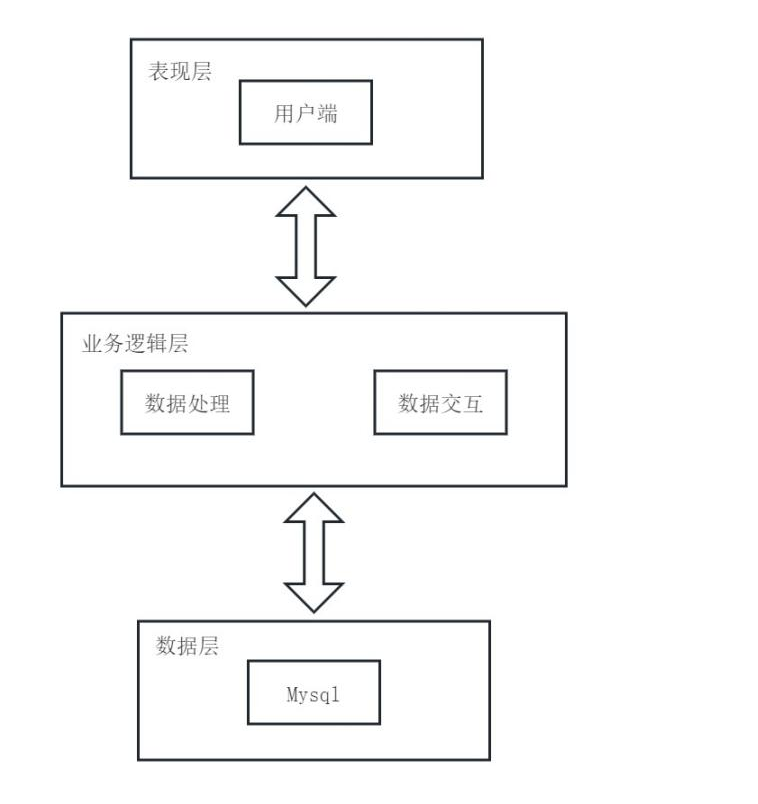
4.2 功能模块设计
通过前文的需求分析得到,基于深度学习的中文识别系统的总体设计模块如图4.2所示。
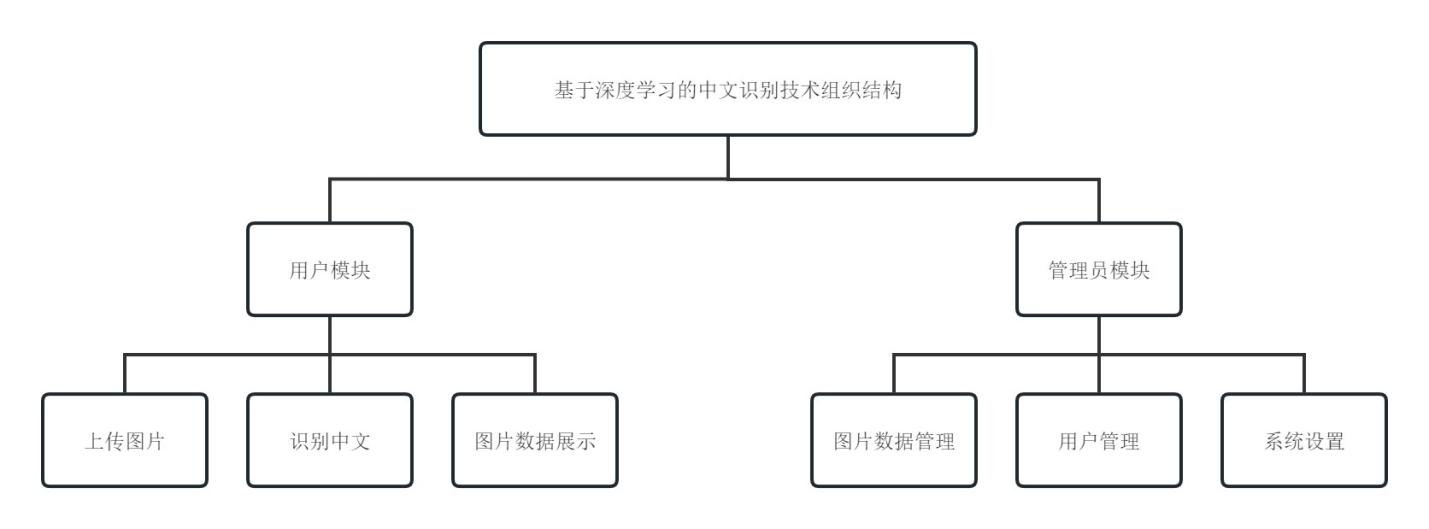
图4.2 系统功能模块图
4.3 相关功能设计
4.3.1 登录操作流程
系统安全性的首要步骤是用户在尝试访问系统时,必须通过登录界面输入其登录信息。如图4.3所示。
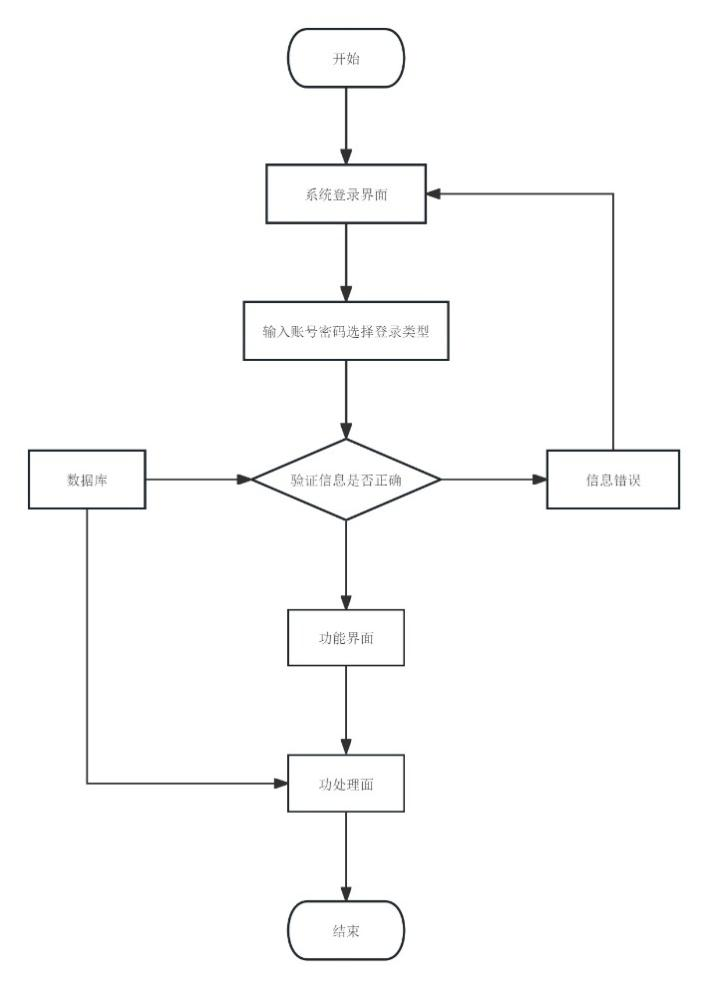
图4.3 登录操作流程图
4.3.2 图片识别功能设计
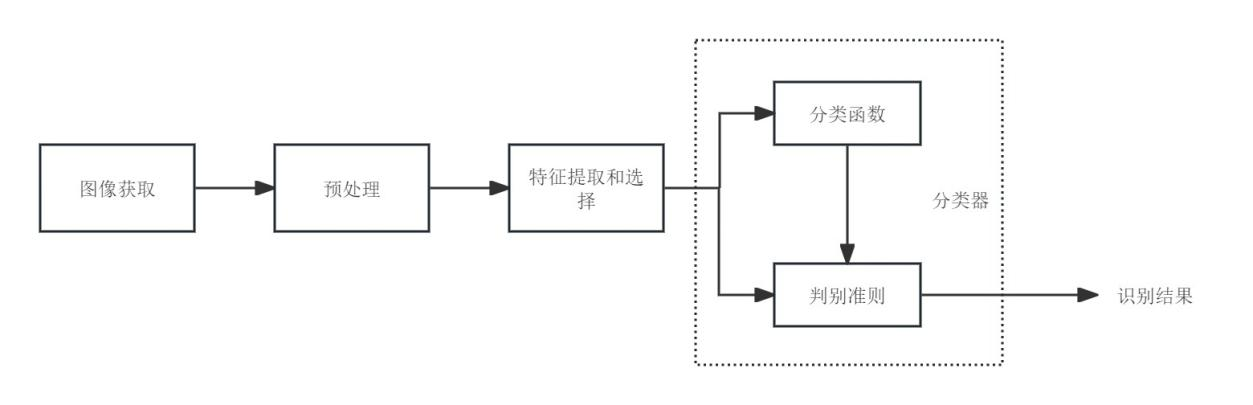
图4.4 图像检测流程图
4.4 数据库设计
下面为本系统核心数据库表的E-R关系总图如图4.5所示。。
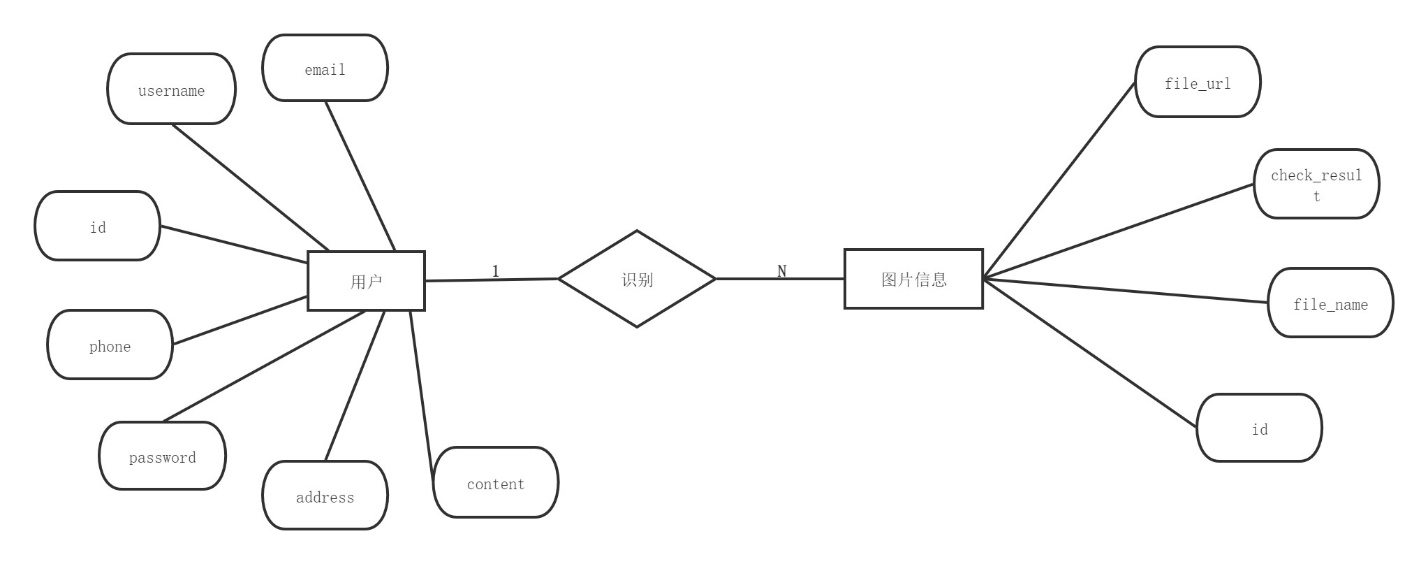
图4.5 系统总E-R关系图
图片信息表用以存放上传图片的基本信息,见表4.1。
表4.1 用户表
| 名称 | 数据类型 | 长度 | 允许空值 | 键 | |
| 1 | id | int | 0 | N | Y |
| 2 | password | varchar | 128 | Y | N |
| 3 | last_login | datetime | 0 | Y | N |
| 4 | is_superuser | bool | 0 | N | N |
| 5 | first_name | varchar | 150 | N | N |
| 6 | last_name | varchar | 150 | N | N |
续表4.1 用户表
| 编号 | 名称 | 数据类型 | 长度 | 允许空值 | 键 |
| 7 | | varchar | 254 | N | N |
| 8 | is_staff | bool | 0 | N | N |
| 9 | is_active | bool | 0 | N | N |
| 10 | date_joined | datetime | 0 | N | N |
| 11 | username | varchar | 50 | N | N |
| 12 | gender | varchar | 1 | N | N |
| 13 | phone_number | varchar | 20 | N | N |
| 14 | avatar | varchar | 100 | N | N |
表4.2 图片信息表
| 字段名 | 数据类型 | 长度 | 允许空值 | 键 |
| id | integer | 0 | N | Y |
| file_name | varchar | 200 | Y | N |
| file_url | varchar | 250 | Y | N |
| check_result | varchar | 100 | N | N |
第5章 系统实现
5.1 文本识别实现
5.1.1 实现思路
如图5.1所示。
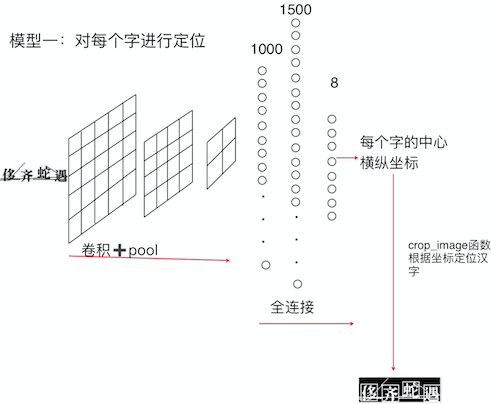
图5.1 对每个字进行定位实现思路图
第二层为基于MobileViT的轻量化检测网络,输入第一层提取出的字符框图像。在局部卷积特征的基础上结合全局的注意力机制,使该模块可以对包含篆、隶、楷、行四种字体的多风格汉字数据集进行如5.2所示的识别:
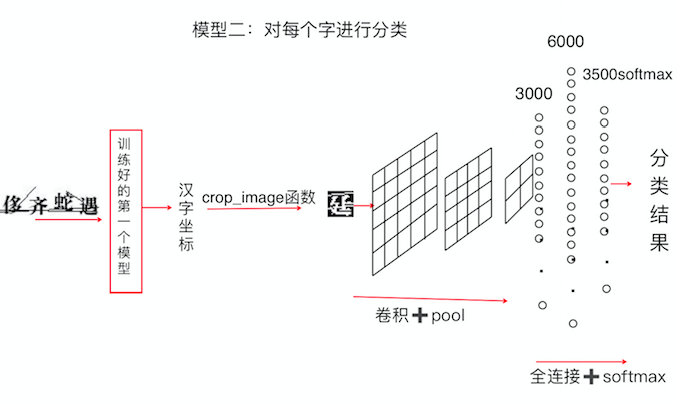
图5.2 对每个字进行分类实现思路图
5.1.2 数据来源
该数据全都是合成数据,数据未使用外部真实数据。通过自动合成汉字图,并结合不同的干扰元素,合成更多的训练样本,具体包括:从文件3500.从txt文件中得到常用的3500个汉字。如图5.3:

图5.3 trainImg0.npy和trainLab0.npy
5.1.3 图像处理
本系统在数据预处理阶段采用三阶段标准化流程,有效提升模型对汉字特征的提取效率[9]。图像处理流程图5.4所示。
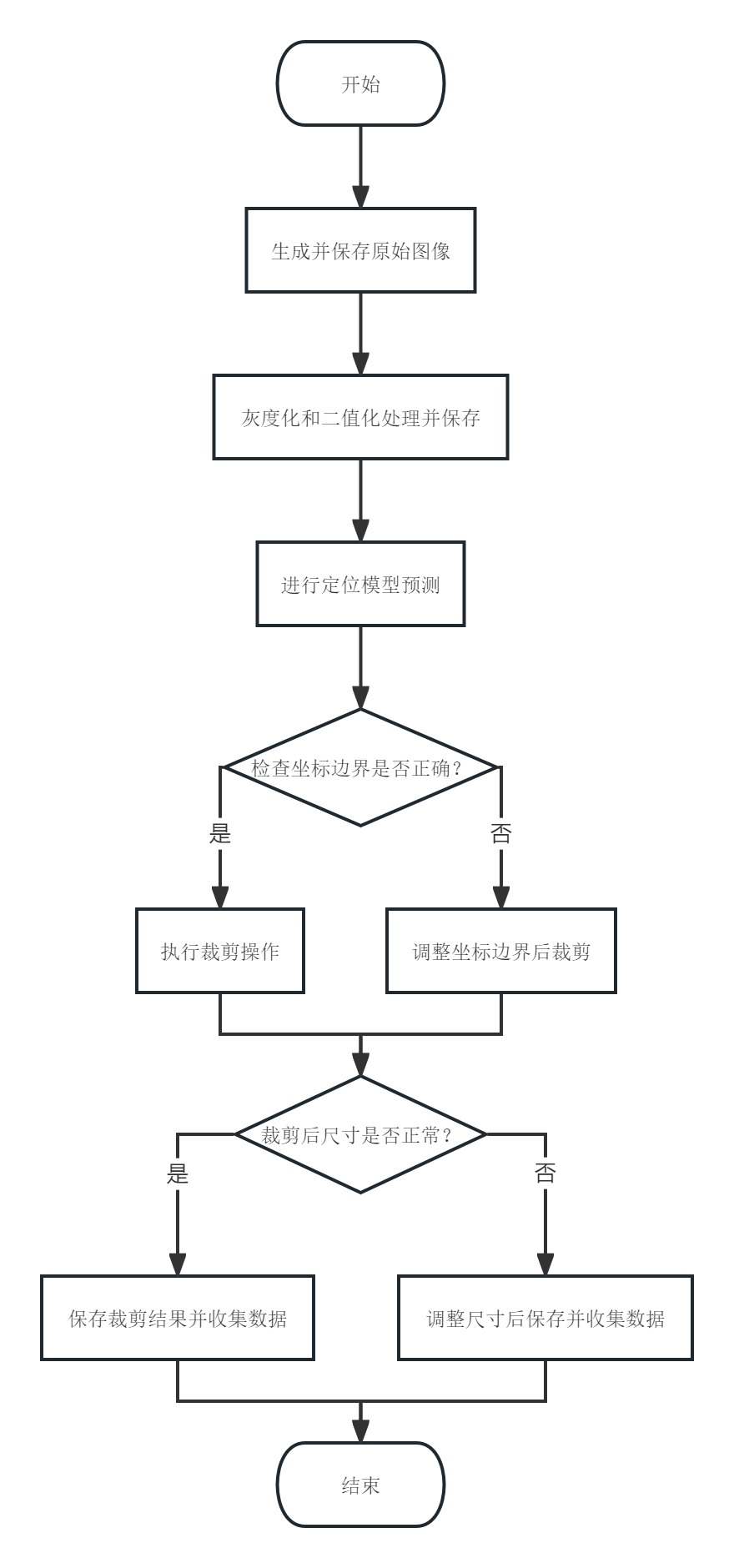
图5.4 图像处理流程图
首先执行色彩空间转换结果如图5.5所示:
![]()
图5.5 测试样本图1
其次进行自适应二值化处理,采用固定阈值127实施颜色反转。结果如图5.6所示:
![]()
图5.6 测试样本图2
最后执行归一化操作,将二值图像素值由{0,255}线性映射至{0,1}区间。如图5.7归一化处理结果。

图5.7 归一化处理结果
5.1.4 图像裁剪
裁剪流程可以概括为4个过程:坐标归一化恢复,即将定位网络的输出归一化后的坐标(0-1之间的数)与图的尺寸(宽100,高30像素)做乘法,得到坐标点的实际坐标如图5.8所示:
![]()
![]()
图5.8 裁剪前后对比
5.1.5 模型构建
构建训练第一个模型:预测汉字中心坐标。首先需要准备数据,并对其进行预处理:将图像转换为灰度图,然后对图像进行颜色反转的二值化处理,使字体呈现白色而背景为黑色。。
5.1.6 模型评估
从训练损失及训练正确率曲线可以看出模型在训练步数为16k时趋于收敛,损失从4.0平稳降至0.2以下,呈现出指数级递减的趋势,即参数的更新方向是合理的如图5.9。
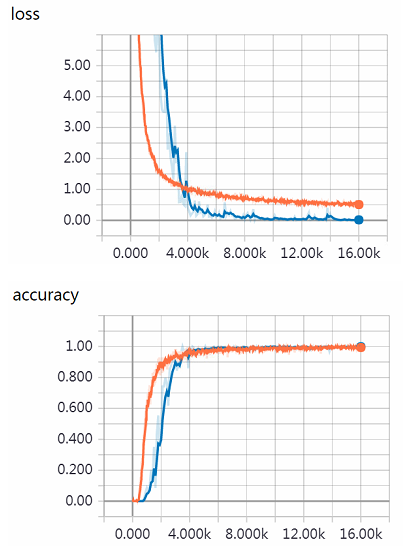
图5.9 形近字(如“未-末”)对比图
5.1.7 结果呈现
中文识别系统的实现基于深度学习双阶段架构,具体流程如下:
图像预处理阶段
汉字定位检测
字符分类识别
系统通过Django中间件实现异步处理,平均响应时间低于800ms。识别结果存入ImageCheck模型并返回前端,利用AJAX动态更新检测结果[13]。识别展示如下图5.10所示。
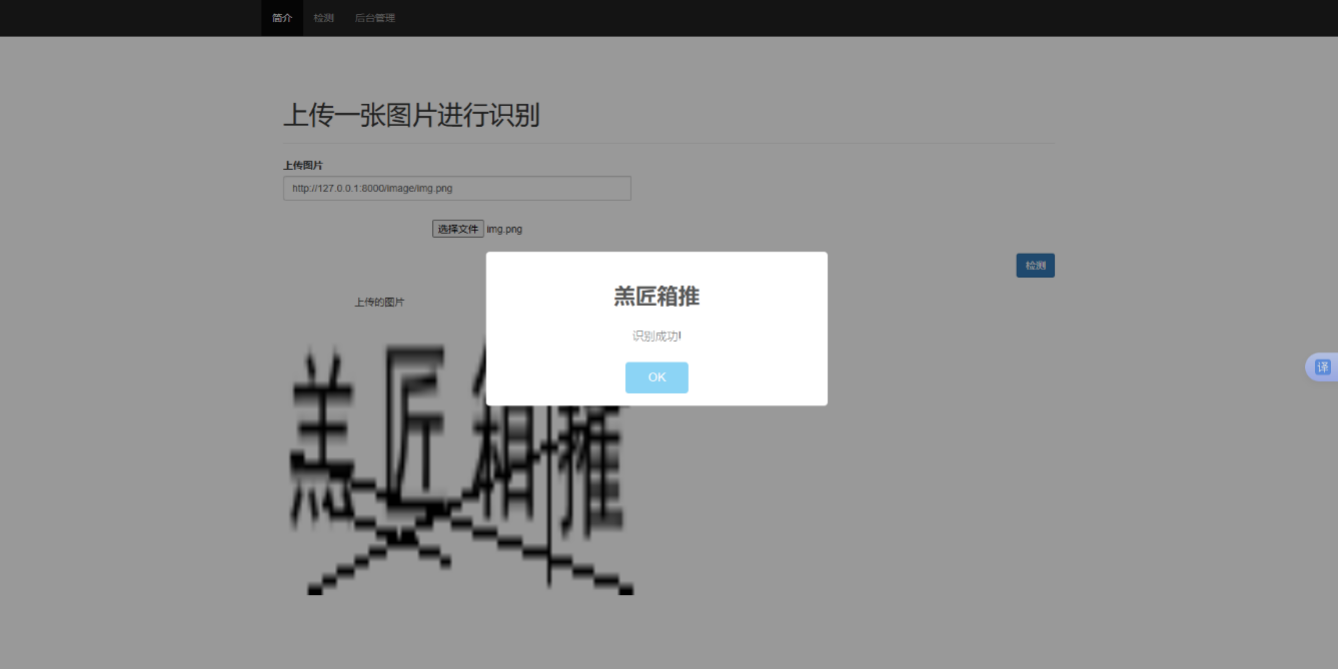
图5.10 展示结果
5.2 登录注册实现
登录页前端登录表单(login.html)通过POST方式输入用户名、密码与登录类型(用户或管理员)后,后端利用Django中的AuthenticationForm提供验证的方法进行验证。登录页面如图5.11所示。
图5.11 登录界面图
5.3 后端管理实现
该后台数据管理系统基于Django Admin模块构建,主要实现四大核心功能:
数据可视化展示
图片数据管理
系统深度集成
后台管理页面图见图5.12-5.14:
图5.12 首页后台管理
图5.13 用户后台管理
图5.14 图片后台管理

















 4284
4284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









