




 本文详细介绍了基于深度学习的自然场景文本检测方法,包括基于回归和基于分割的两种主要技术路线。从早期的两阶段检测方法如Faster R-CNN的改进,到单阶段方法如YOLO和SSD的适应性应用,再到EAST和TextSnake等模型对任意形状文本的检测,展现了深度学习在文本检测领域的不断进步和挑战。文章还探讨了如何通过预测文本几何属性、利用循环神经网络增强上下文信息等手段提高检测精度。
本文详细介绍了基于深度学习的自然场景文本检测方法,包括基于回归和基于分割的两种主要技术路线。从早期的两阶段检测方法如Faster R-CNN的改进,到单阶段方法如YOLO和SSD的适应性应用,再到EAST和TextSnake等模型对任意形状文本的检测,展现了深度学习在文本检测领域的不断进步和挑战。文章还探讨了如何通过预测文本几何属性、利用循环神经网络增强上下文信息等手段提高检测精度。
点击领取AI产品100元体验金:https://www.textin.com/coupon_redemption/index.html https://www.textin.com/coupon_redemption/index.html
https://www.textin.com/coupon_redemption/index.html

# 3.常用的文本检测与识别方法
## 3.1文本检测方法
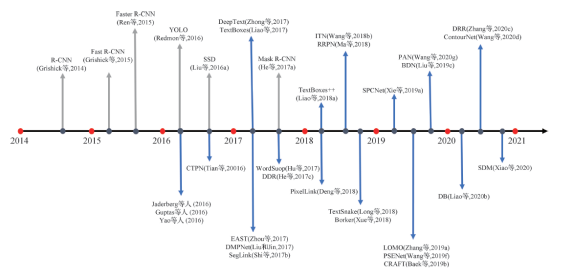
随着深度学习的快速发展,图像分类、目标检测、语义分割以及实例分割都取得了突破性的进展,这些方法成为自然场景文本检测的基础。基于深度学习的自然场景文本检测方法在检测精度和泛化性能上远优于传统方法,逐渐成为了主流。图1 列举了文本检测方法近几年来的发展历程。
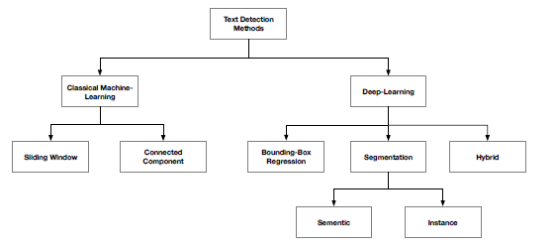
目前,根据检测文本对象的不同可以将基于深度学习的方法划分为基于回归的文本检测方法和基于分割的文本检测方法两大类,不同类别方法的流程如图所示。
### 3.1.1 基于回归的场景文本检测方法
基于回归的自然场景文本检测方法主要是基于以深度学习为基础的目标检测技术或者实例分割技术,它将文本视为一种通用目标然后直接检测出整个文本实例。此类方法通常是直接回归出水平矩形或者多方向的任意形状多边形以解决文本检测的问题。
早期的这类文本检测方法基于传统滑动窗口方法的思想,只是在对滑窗进行文本和非文本分类的时候使用CNN 提取的特征而不是人工设计的特征(Wang 等,2012;Jaderberg 等,2014)。
虽然能提高分类性能,但计算量大以及适用范围窄(大部分只能处理水平方向文本)的问题依旧没有解决。在基于深度学习的目标检测和分割等技术的突破性进展的同时,这些方法也为自然场景文本检测提供了新的思路。
基于深度学习的基于回归的自然场景文本检测方法可分为**两阶段**和**单阶段**的方法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









