






 该博客介绍了如何利用Scrapy爬虫框架抓取腾讯直聘网站的职位信息。首先,分析了页面请求为AJAX,并以JSON格式返回。接着,重写了start_requests方法,循环获取不同页码的URL。每条职位信息被解析并存储到字典中,包括职位名称、ID、地点等。随后,通过职位ID拼接详情页URL,进一步解析详情页的JSON数据以获取职位要求。最后,定义了一个Scrapy管道,将抓取的数据存储到MySQL数据库中。
该博客介绍了如何利用Scrapy爬虫框架抓取腾讯直聘网站的职位信息。首先,分析了页面请求为AJAX,并以JSON格式返回。接着,重写了start_requests方法,循环获取不同页码的URL。每条职位信息被解析并存储到字典中,包括职位名称、ID、地点等。随后,通过职位ID拼接详情页URL,进一步解析详情页的JSON数据以获取职位要求。最后,定义了一个Scrapy管道,将抓取的数据存储到MySQL数据库中。
1.对腾讯直聘的页面进行分析
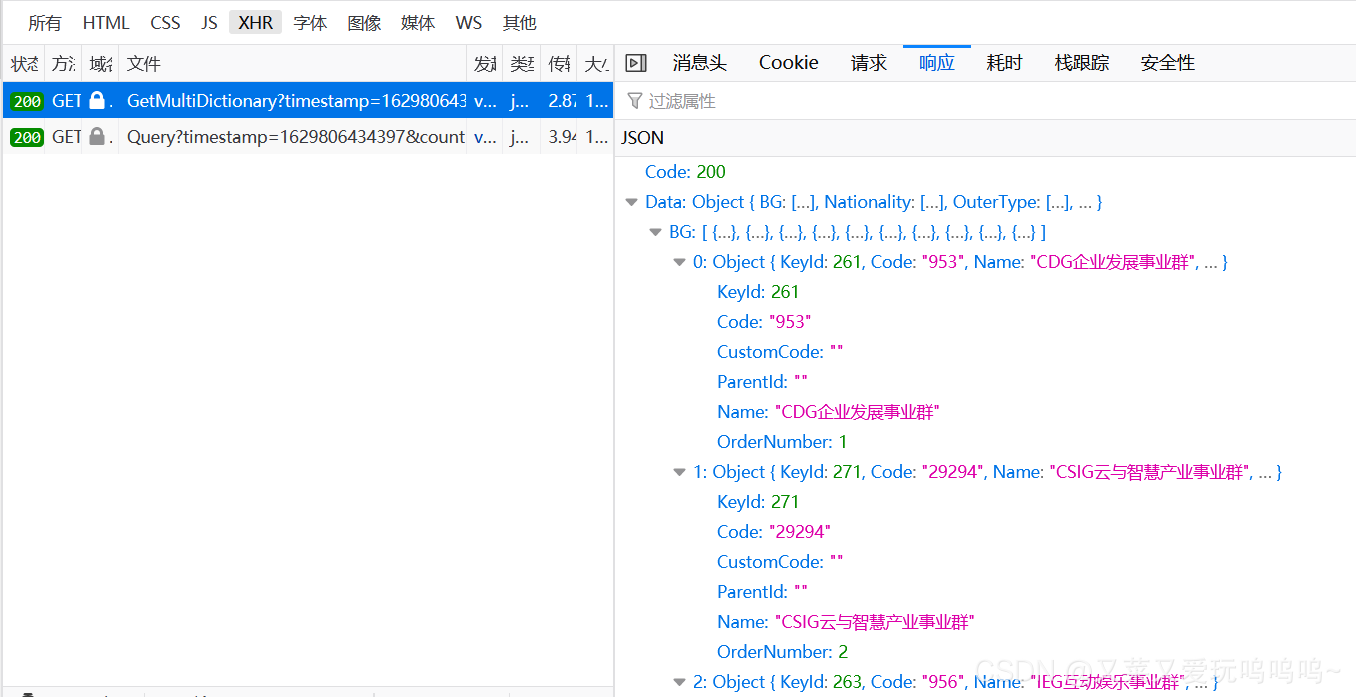
最后发现首页面是AJAx请求,所以我们返回应该是一个JSON包的形式
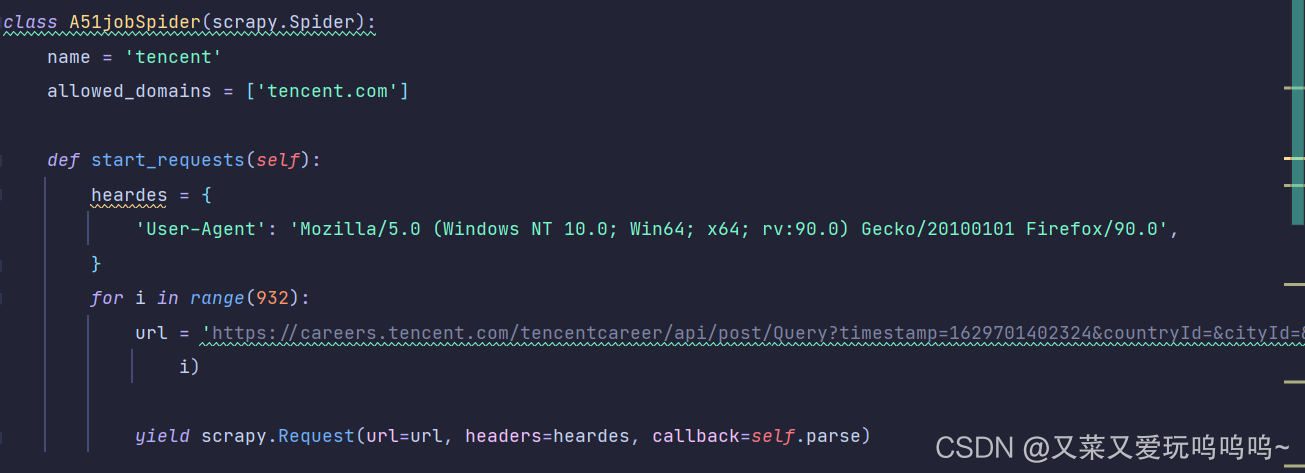
2.重写爬虫start_request方法
3.接受JSON包并设定字典储存数据
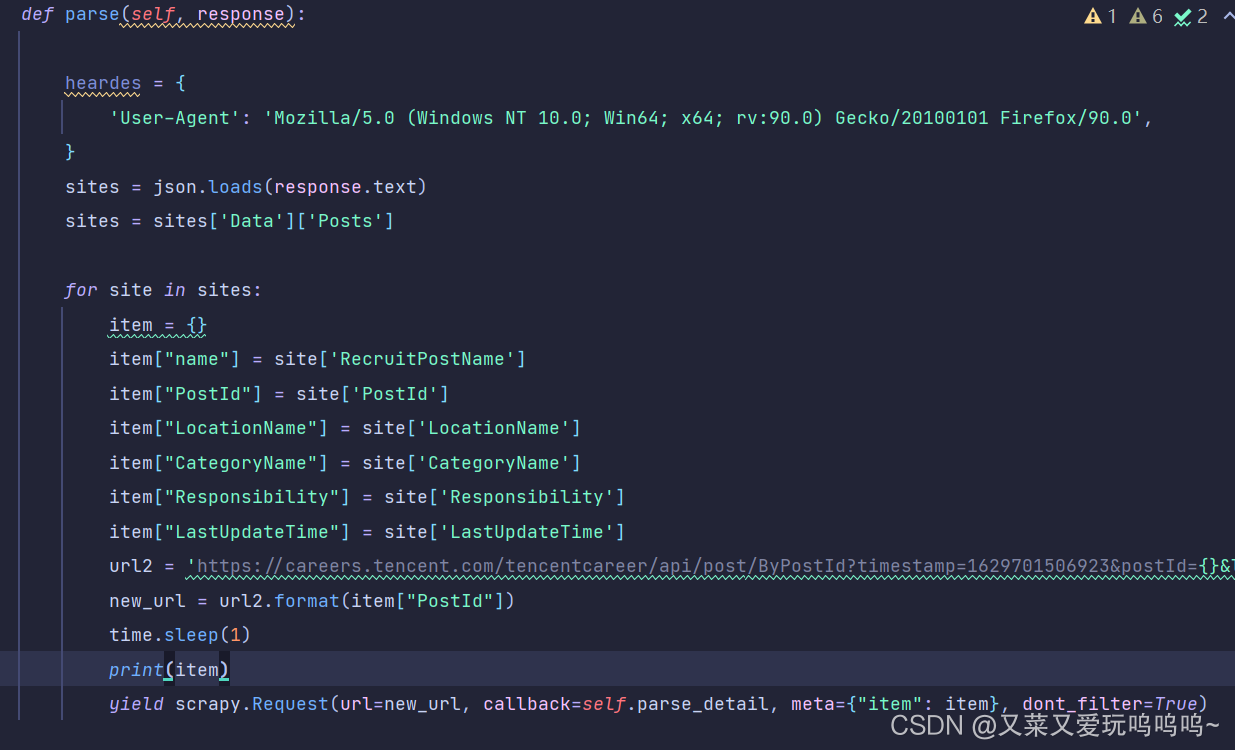
4.根据POSTID,拼接详情页url, 并将详情页添加进字典
1.拼接url并传递连接到详情页 2.对详情页的JSON包进行解析
2.对详情页的JSON包进行解析
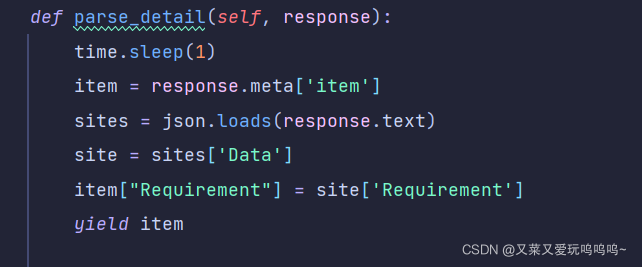
5.在管道内进行存储, 将数据存入数据库中
6.源代码
1.爬虫页面源代码
import scrapy
import json
import time
class A51jobSpider(scrapy.Spider):
name = 'tencent'
allowed_domains = ['tencent.com']
def start_requests(self):
heardes = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0',
}
for i in range(932):
url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1629701402324&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'.format(
i)
yield scrapy.Request(url=url, headers=heardes, callback=self.parse)
def parse(self, response):
heardes = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0',
}
sites = json.loads(response.text)
sites = sites['Data']['Posts']
for site in sites:
item = {}
item["name"] = site['RecruitPostName']
item["PostId"] = site['PostId']
item["LocationName"] = site['LocationName']
item["CategoryName"] = site['CategoryName']
item["Responsibility"] = site['Responsibility']
item["LastUpdateTime"] = site['LastUpdateTime']
url2 = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1629701506923&postId={}&language=zh-cn'
new_url = url2.format(item["PostId"])
time.sleep(1)
print(item)
yield scrapy.Request(url=new_url, callback=self.parse_detail, meta={"item": item}, dont_filter=True)
def parse_detail(self, response):
time.sleep(1)
item = response.meta['item']
sites = json.loads(response.text)
site = sites['Data']
item["Requirement"] = site['Requirement']
yield item
2.开启管道,seeting中解除如下代码的注释
ITEM_PIPELINES = {
'wuyijob.pipelines.WuyijobPipeline': 300,
}
3.pipelines内储存信息到数据库
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
def dbHandle():
conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='root', db='test', charset='utf8',
use_unicode=False)
return conn
class WuyijobPipeline:
def process_item(self, item, spider):
db = dbHandle()
cursor = db.cursor()
sql = 'INSERT INTO tencent (work_name,LocationName,CategoryName, Responsibility, LastUpdateTime, Requirement) VALUES(%s,%s,%s,%s,%s,%s)'
try:
cursor.execute(sql,
(item['name'], item['LocationName'], item['CategoryName'], item['Responsibility'],
item['LastUpdateTime'], item['Requirement']))
cursor.connection.commit()
except BaseException as e:
print(e)
db.rollback()
return item

















 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









