scrapy中parse之间传递不通
最新推荐文章于 2022-08-12 17:08:01 发布







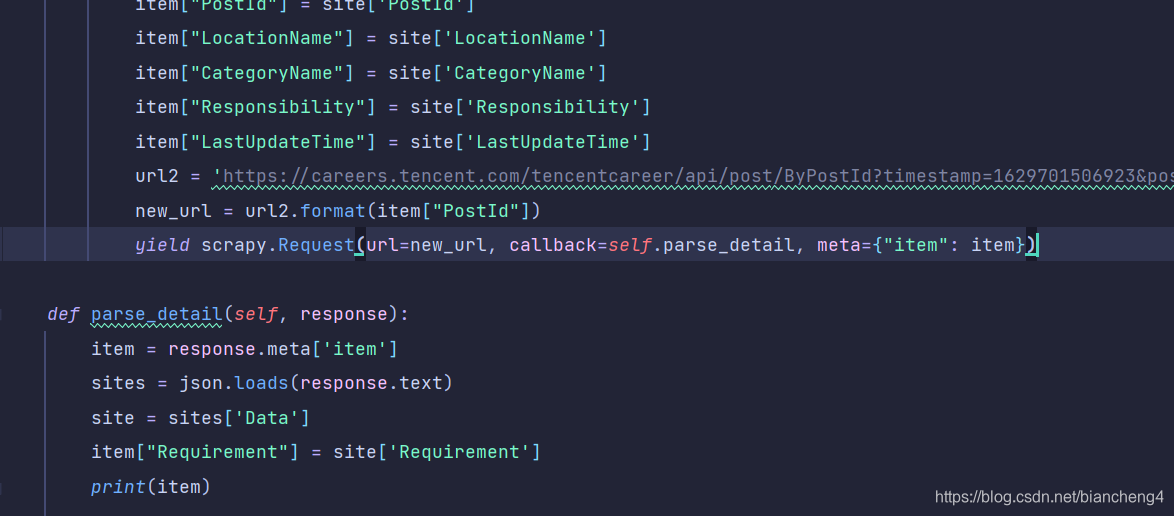
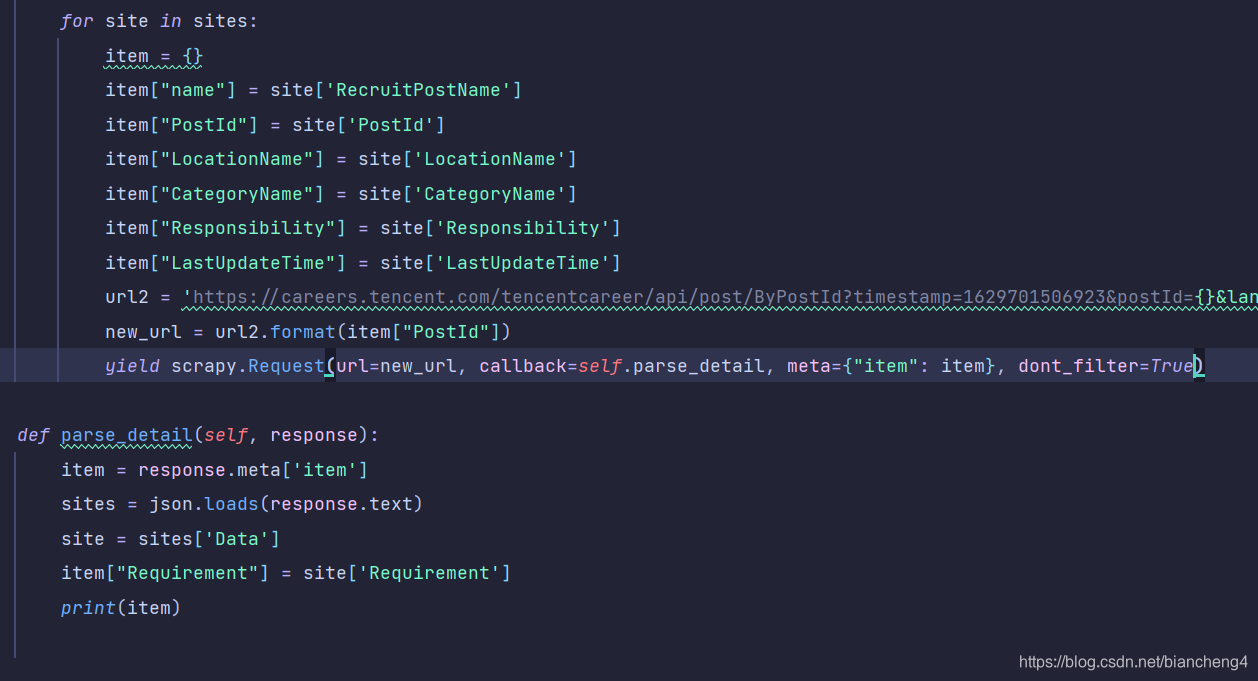
 本文揭示了在使用Scrapy爬取网站时,加入'dont_filter=true'的必要性,详解了去重规则和domain过滤,以及如何确保请求的URL准确执行。
本文揭示了在使用Scrapy爬取网站时,加入'dont_filter=true'的必要性,详解了去重规则和domain过滤,以及如何确保请求的URL准确执行。
本文揭示了在使用Scrapy爬取网站时,加入'dont_filter=true'的必要性,详解了去重规则和domain过滤,以及如何确保请求的URL准确执行。
本文揭示了在使用Scrapy爬取网站时,加入'dont_filter=true'的必要性,详解了去重规则和domain过滤,以及如何确保请求的URL准确执行。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言























 1490
1490





