




 本文介绍了一种使用Scrapy框架爬取腾讯招聘网站岗位信息的方法,包括岗位名称、工作职责、工作要求及发布日期,并详细解析了网页请求规律及Python代码实现。
本文介绍了一种使用Scrapy框架爬取腾讯招聘网站岗位信息的方法,包括岗位名称、工作职责、工作要求及发布日期,并详细解析了网页请求规律及Python代码实现。
页面地址:
https://careers.tencent.com/search.html?pcid=40001
实现目标:
| 将爬取到的岗位名称、工作职责、工作要求、发布日期以字典格式输出。 |
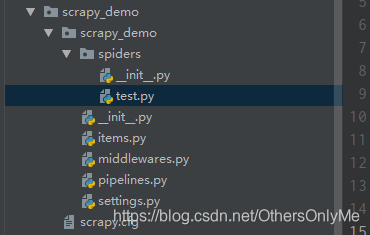
Scrapy目录框架:
思路:
| 浏览器抓包分析网页请求地址规律(爬虫最重要),找到页面地址规律后,根据请求返回的数据进行提取即可。 |
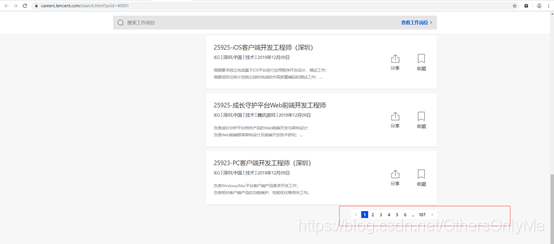
图一
由图一页面可知,招聘岗位共有187页,需循环遍历所有页面;
浏览器抓包实际请求页面地址为:
| https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1575882949947&countryId=&cityId=&bgIds=&productId=&categoryId=40001001,40001002,40001003,40001004,40001005,40001006&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn |
规律:pageIndex=1 为页数,其他暂保持不变
(爬完之后发现这里也有个时间戳,哈哈,冒似没啥影响,时间固定一样可以获取到数据)
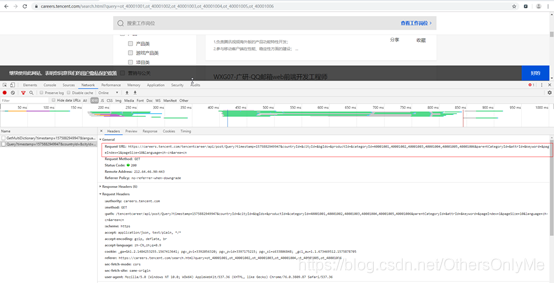
图二
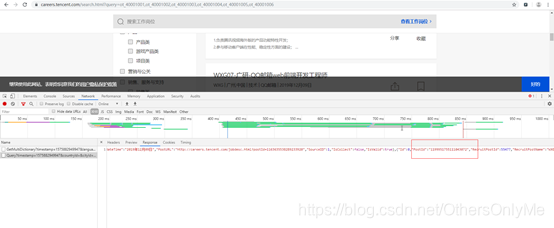
图三
页面请求返回的PostId为岗位详情页后面的具体地址:
招聘岗位详情页示例:
https://careers.tencent.com/jobdesc.html?postId=1203886892391600128
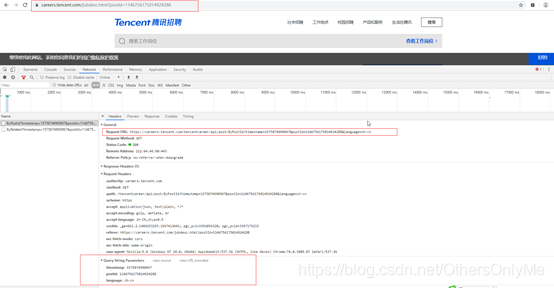
图四
从浏览器抓包的请求头来看,URL地址规律如下:
| “https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp= “此为固定部分,后面为当前时间戳, |
Python代码如下:
时间戳部分学习参考:https://blog.youkuaiyun.com/qq_31603575/article/details/83343791
|
# -*- coding: utf-8 -*-
import scrapy
import json,datetime,time
#生成 13位当前时间戳
def get_time_stamp13():
# 生成13时间戳 eg:1540281250399895
datetime_now = datetime.datetime.now()
# 10位,时间点相当于从UNIX TIME的纪元时间开始的当年时间编号
date_stamp = str(int(time.mktime(datetime_now.timetuple())))
# 3位,微秒
data_microsecond = str("%06d" % datetime_now.microsecond)[0:3]
date_stamp = date_stamp + data_microsecond
return int(date_stamp)
class TestSpider(scrapy.Spider):
name = 'test'
allowed_domains = ['tencent.com']
start_urls = ['https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1575855782891&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=40001&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn']
def pasrse1(self,response):
html1 = response.text
#响应数据转换为字典格式
html1_json = json.loads(html1)
# print(html1_json['Data'])
# exit()
# for j in html1_json['Data']:
job_dic = {}
job_dic['岗位名称'] = html1_json['Data']['RecruitPostName']
job_dic['工作职责'] = html1_json['Data']['Responsibility']
job_dic['发布日期'] = html1_json['Data']['LastUpdateTime']
job_dic['工作要求'] = html1_json['Data']['Requirement']
print(job_dic)
def parse(self, response):
html = response.text
html_json = json.loads(html)
id_url_list = html_json['Data']['Posts'] #[0]['PostId']
for lj in id_url_list:
time_format = str(get_time_stamp13())
#url地址拼接
desc_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=' + time_format + '&postId=' + lj['PostId'] + '&language=zh-cn'
# print(desc_url)
# print(lj['PostId'])
# for k in url_list['PostURL']:
# job_url = []
# job_url.append(k)
# yield scrapy.Request(url=job_url, callback=self.pasrse1, dont_filter=True)
#提交请求,迭代处理
yield scrapy.Request(url=desc_url, callback=self.pasrse1, dont_filter=True)
for i in range(2,188):
#页面地址循环遍历
url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1575855782891&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=40001&attrId=&keyword=&pageIndex=' + str(i) + '&pageSize=10&language=zh-cn&area=cn'
yield scrapy.Request(url=url,callback=self.parse,dont_filter=True)
|

执行效果如下:


















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









