







scrapy startproject ArticleSpider #创建名称为ArticleSpider的项目文件
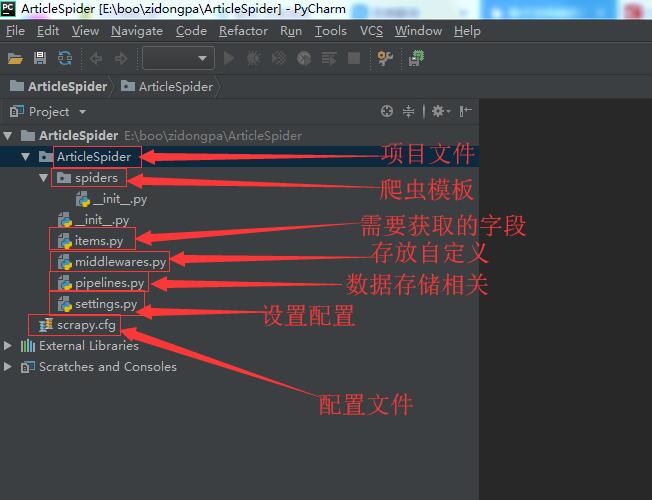
【创建爬虫项目】
通过以上命令来创建爬虫项目。
命令行创建爬虫模板(需要在项目文件夹内执行,避免模板创建到其他地方)
scrapy genspider jobbole blog.jobbole.com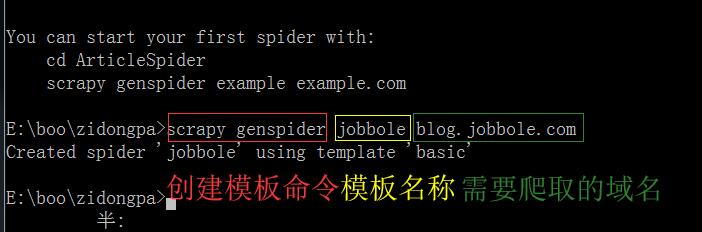
(正确的创建模板路径应该是:E:\boo\zidongpa\ArticleSpider\执行命令)
【模板工作流程】
模板中的JobboleSpider类继承scrapy的Spider方法
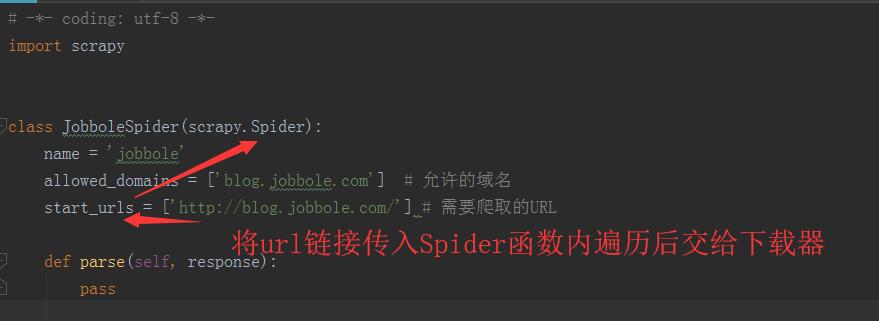
Spider方法将url遍历后交给Request下载器下载

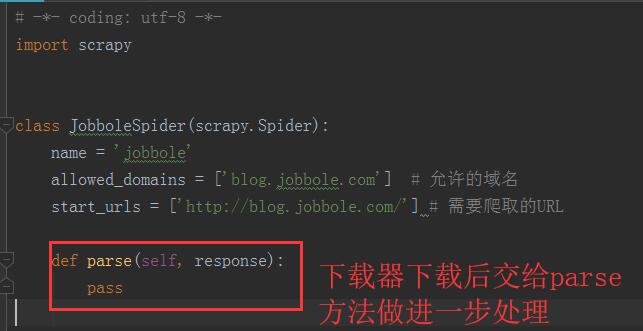
Request下载器下载后会交给parse方法做进一步处理
【调试】
需要调试时新建一个main.py文件运行调试(但是我们需要告诉计算机来获取这些文件,代码如下)
from scrapy.cmdline import execute # 调用Scrapy脚本
import sys # 因为要设置项目工程目录
import os #
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
# os.path.dirname() = 父目录
# os.path.abspath(__file__) = 当前文件路径
# sys.path.append('E:\boo\zidongpa\ArticleSpider')等同于上面函数,但是为了避免另外一台机器运行时找不到目录所用os模块设置
# print(os.path.dirname(os.path.abspath(__file__))) # 测试打印目录是否正确# >>>E:\boo\zidongpa\ArticleSpider\ArticleSpider # 打印结果execute(["scrapy","crawwl","jobbole"]) # 启动一个爬虫模板的命令(["框架名称","crawwl","爬虫模板名称"])Scrapy只启动一个爬虫模板文件,根据爬虫 name = 'jobbole' 名称来启动(项目文件夹下输入以下指令)
命令行: scrapy crawl jobbole
(win下可能出现的错误: ImportError: No module named 'win32api'),解决方法: pip install pypiwin32
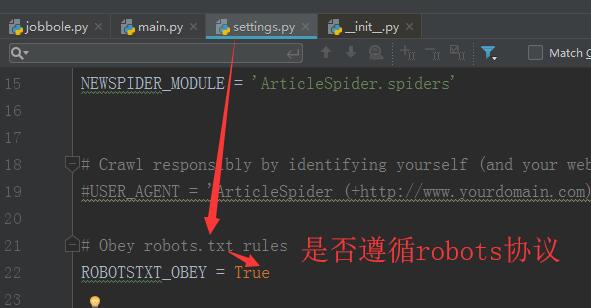
【robots协议开关】
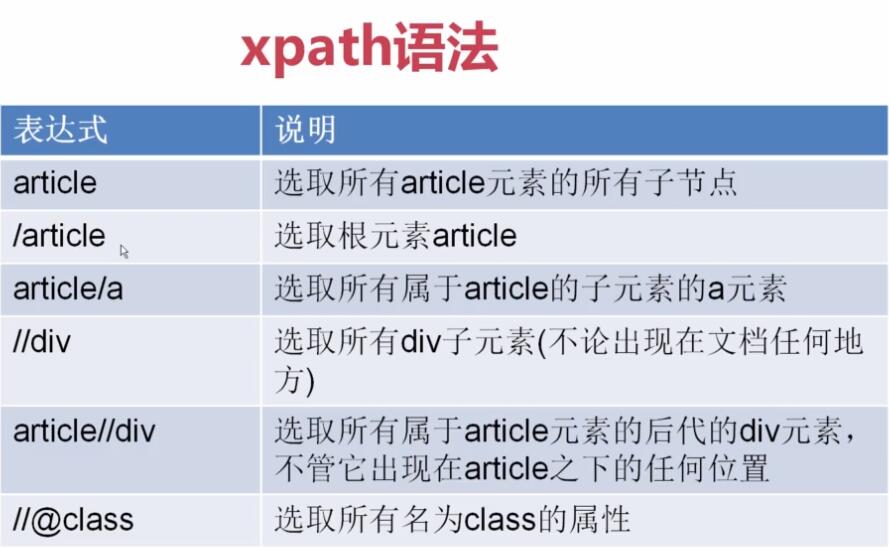
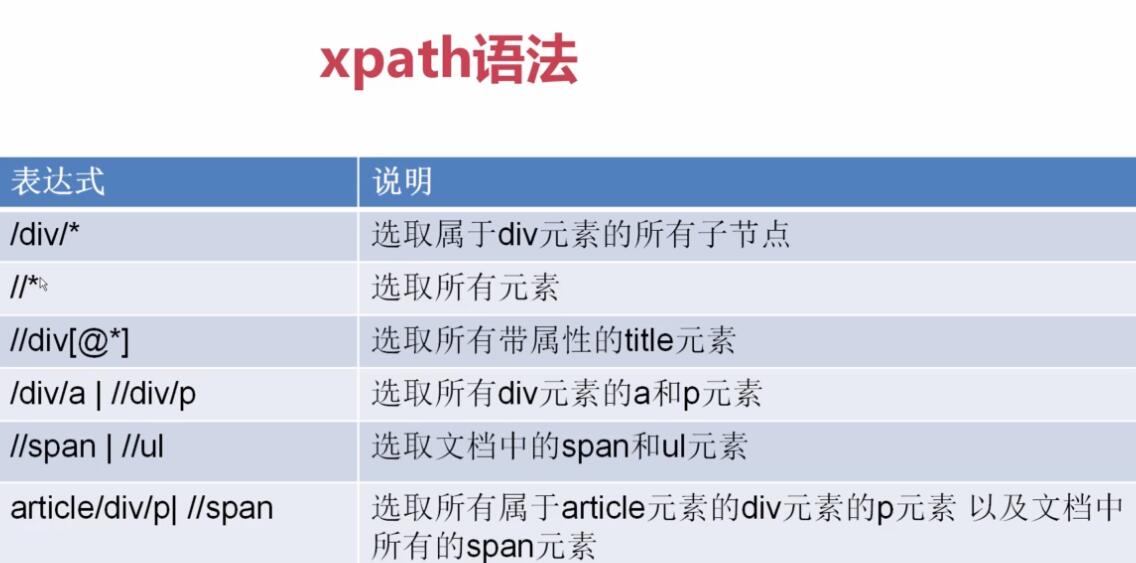
【xpath提取值】

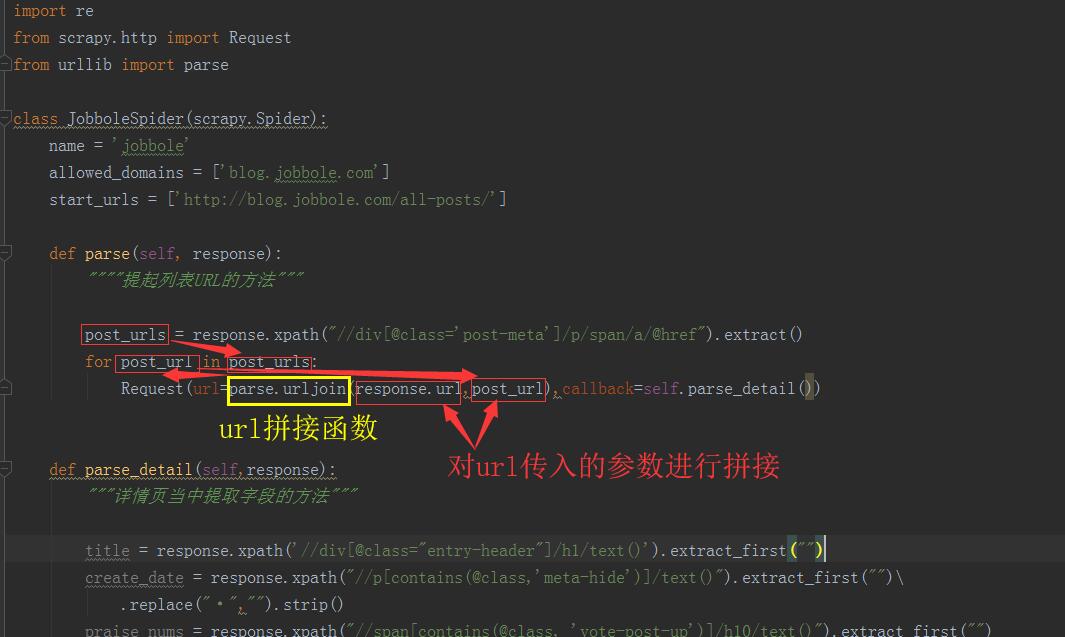
【response自带xpath和css选择器】
命令行进入 response模式 :
scrapy shell 网址
import scrapy
create_date = response.xpath("//p[@class='entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
# xpath示例
# extract() = 列表元素值
# extract()[0] = 索引方式提取元素
# extract_first("") = 提取字符串,如果没有则返回""空
# strip() = 去除首尾空格
# replace("·","") = 将 · 替换为空abcd = response.xpath('//span[contains(@class,"vote-post-up")]/text()').extract_first("")
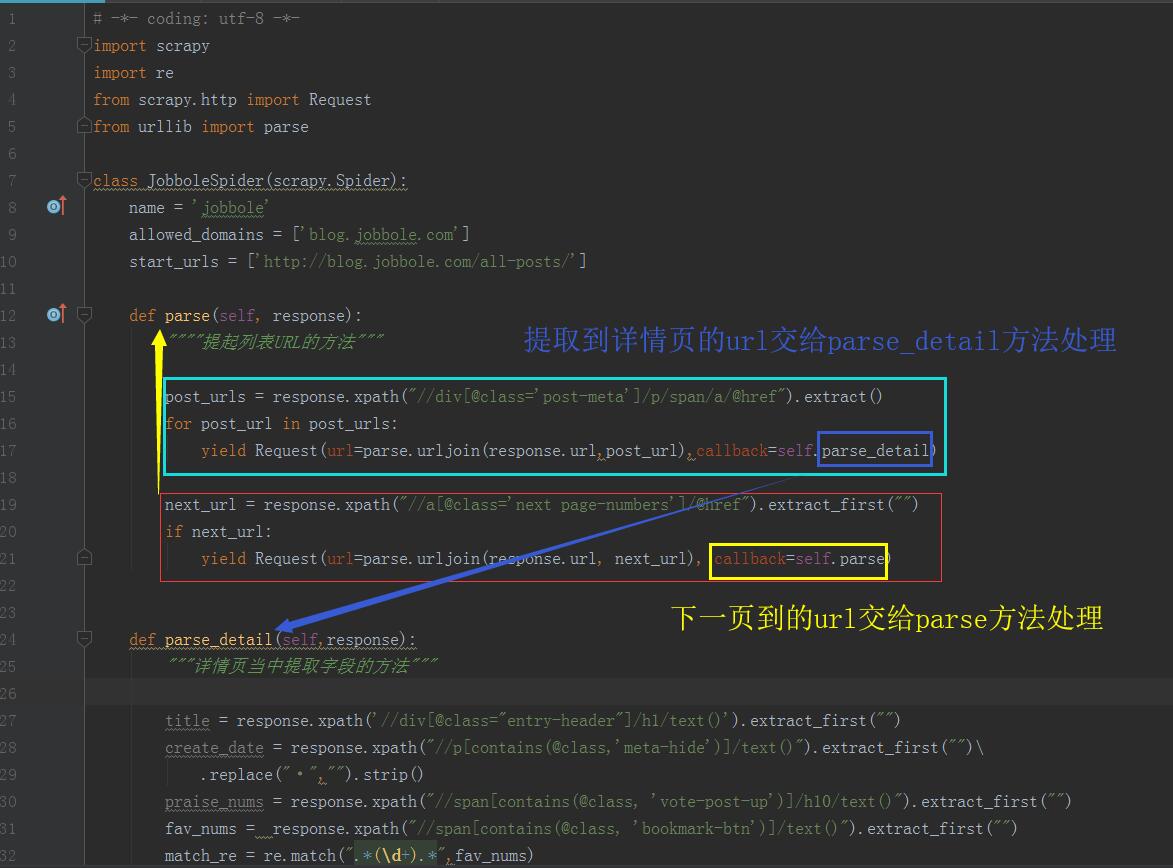
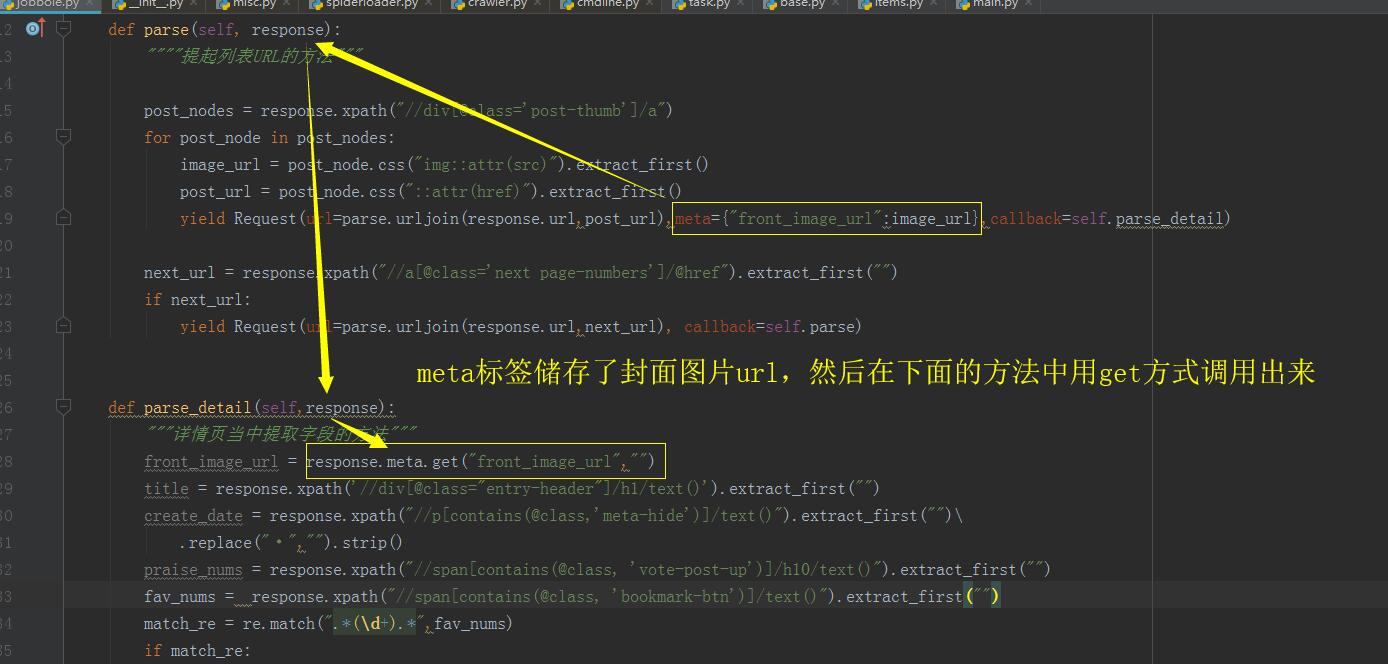
# contains(刊忐忑) = 搜索模式【列表也采集url的逻辑和函数】



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









