



 本文介绍了Presto,一个针对大数据的低延迟查询引擎,性能优于Hive。Presto采用Master-Slave架构,通过内存计算、流水线等优化实现高速查询。文章分享了Presto的查询优化策略,包括数据存储、SQL优化和与Impala的对比,如合理设置分区、使用ORC格式、限制字段选择等,旨在提升查询性能。
本文介绍了Presto,一个针对大数据的低延迟查询引擎,性能优于Hive。Presto采用Master-Slave架构,通过内存计算、流水线等优化实现高速查询。文章分享了Presto的查询优化策略,包括数据存储、SQL优化和与Impala的对比,如合理设置分区、使用ORC格式、限制字段选择等,旨在提升查询性能。
Presto
Hive使用MapReduce作为底层计算框架,是专为批处理设计的。但随着数据越来越多,使用Hive进行一个简单的数据查询可能要花费几分到几小时,显然不能满足交互式查询的需求。
2012年秋季开始开发,目前该项目已经在超过 1000名Facebook雇员中使用,运行超过30000个查询,每日数据在1PB级别。Facebook称Presto的性能比Hive要好上10倍多。2013年Facebook正式宣布开源Presto。
Presto架构
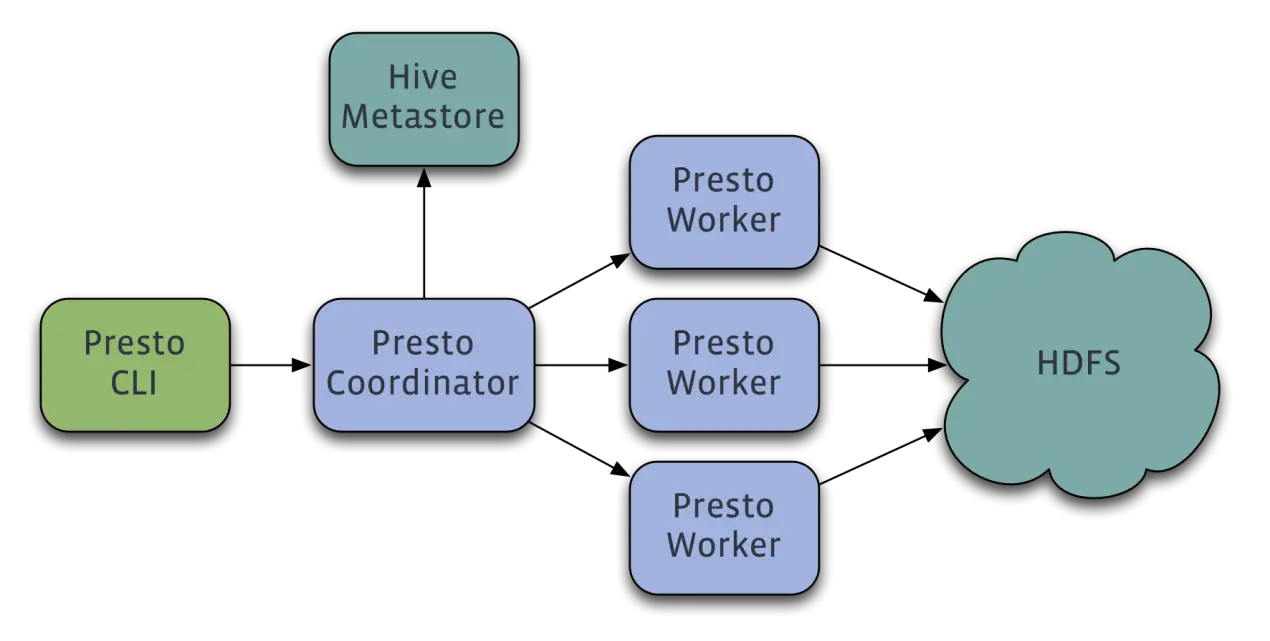
Presto查询引擎是一个Master-Slave的架构,由一个Coordinator节点,一个Discovery Server节点,多个Worker节点组成,Discovery Server通常内嵌于Coordinator节点中。
Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行。
Worker节点负责实际执行查询任务。Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。
如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点与HDFS交互读取数据。
Presto实现低延时查询的原理,我认为主要是下面几个关键点:
- 完全基于内存的并行计算
- 流水线
- 本地化计算
- 动态编译执行计划
- 小心使用内存和数据结构
- 类BlinkDB的近似查询
- GC控制
更多详情:https://blog.youkuaiyun.com/fly_time2012/article/details/52160140
Presto查询优化
数据存储
合理设置分区
与Hive类似,Presto会根据元信息读取分区数据,合理的分区能减少Presto数据读取量,提升查询性能。
使用列式存储
Presto对ORC文件读取做了特定优化,因此在Hive中创建Presto使用的表时,建议采用ORC格式存储。相对于Parquet,Presto对ORC支持更好。
使用压缩
数据压缩可以减少节点间数据传输对IO带宽压力,对于即席查询需要快速解压,建议采用snappy压缩
预先排序
对于已经排序的数据,在查询的数据过滤阶段,ORC格式支持跳过读取不必要的数据。比如对于经常需要过滤的字段可以预先排序。
SQL优化
- 只选择使用必要的字段: 由于采用列式存储,选择需要的字段可加快字段的读取、减少数据量。避免采用*读取所有字段
- 过滤条件必须加上分区字段
- Group By语句优化: 合理安排Group by语句中字段顺序对性能有一定提升。将Group By语句中字段按照每个字段distinct数据多少进行降序排列, 减少GROUP BY语句后面的排序一句字段的数量能减少内存的使用.
- Order by时使用Limit, 尽量避免ORDER BY: Order by需要扫描数据到单个worker节点进行排序,导致单个worker需要大量内存
- 使用近似聚合函数: 对于允许有少量误差的查询场景,使用这些函数对查询性能有大幅提升。比如使用approx_distinct() 函数比Count(distinct x)有大概2.3%的误差
- 用regexp_like代替多个like语句: Presto查询优化器没有对多个like语句进行优化,使用regexp_like对性能有较大提升
- 使用Join语句时将大表放在左边: Presto中join的默认算法是broadcast join,即将join左边的表分割到多个worker,然后将join右边的表数据整个复制一份发送到每个worker进行计算。如果右边的表数据量太大,则可能会报内存溢出错误。
- 使用Rank函数代替row_number函数来获取Top N
- UNION ALL 代替 UNION :不用去重
- 使用WITH语句: 查询语句非常复杂或者有多层嵌套的子查询,请试着用WITH语句将子查询分离出来
与Impala对比
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,Impala没有再使用缓慢的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎。
Impala性能稍领先于presto,但是presto在数据源支持上非常丰富,presto对SQL的支持上也更多一些。同时由于版本迭代的问题,有一段时间Impala对 hadoop某些社区版本并不支持。
欢迎关注 高广超的简书博客 与 收藏文章 !
欢迎关注 头条号:互联网技术栈 !
个人介绍:
高广超:多年一线互联网研发与架构设计经验,擅长设计与落地高可用、高性能、可扩展的互联网架构。目前从事大数据相关研发与架构工作。
本文首发在 高广超的简书博客 转载请注明!

















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









