






 文章介绍了如何使用Python脚本fpmm_etree_csv.py,利用XML.etree.ElementTree解析Freeplane.mm文件,提取思维导图中的信息,生成包含应用系统名、测试功能描述等字段的测试案例CSV文件。
文章介绍了如何使用Python脚本fpmm_etree_csv.py,利用XML.etree.ElementTree解析Freeplane.mm文件,提取思维导图中的信息,生成包含应用系统名、测试功能描述等字段的测试案例CSV文件。
Freeplane 是一款基于 Java 的开源软件,继承 Freemind 的思维导图工具软件,它扩展了知识管理功能,在 Freemind 上增加了一些额外的功能,比如数学公式、节点属性面板等。
强大的节点功能,不仅仅节点的种类很多,而且对于节点的编辑样式也丰富很多,比如数学公式、表格、HTML 的支持等;
思维导图最基本的功能就是新增节点了,Freeplane 通过 Enter 和 Tab 分别新建同级节点和下一级节点。
除了使用上述的基本节点功能外,Freeplane 还提供了 总结节点 的功能,选择一些节点,通过 编辑 -> 新增节点 -> 新增总节点 来增加总结节点。
python:xml.etree.ElementTree 读 Freeplane.mm文件,生成测试案例.csv文件。
编写 fpmm_etree_csv.py 如下.
#-*- coding: UTF-8 -*-
""" 读 Freeplane.mm文件,使用 xml.etree 生成测试案例.csv文件"""
import os
import sys
import codecs
import xml.etree.ElementTree as ET
# 全局唯一标识 unique_id 缩写: uid
uid = 1
def walk(root_node, level, result_list):
""" 遍历所有的节点 """
global uid
if root_node.tag == 'node':
tmp_list = [uid, level, root_node.tag, root_node.attrib]
result_list.append(tmp_list)
uid += 1
# 遍历每个子节点
children_node = root_node.getchildren()
if len(children_node) == 0:
return
for child in children_node:
walk(child, level+1, result_list)
return
def getXmlData(file_name):
level = 0 # 节点的深度
result_list = []
root = ET.parse(file_name).getroot()
walk(root, level, result_list)
return result_list
# main()
if len(sys.argv) ==2:
f1 = sys.argv[1]
else:
print('usage: python fpmm_etree_csv.py file1.mm')
sys.exit(1)
if not os.path.exists(f1):
print(f"{f1} is not exists.")
sys.exit(2)
fn,ext = os.path.splitext(f1)
if ext.lower() != '.mm':
print('ext is not .mm')
sys.exit(2)
fr = codecs.open(f1, mode='r', encoding="utf-8")
# 读取第一行:
line1 = fr.readline()
if not line1.startswith('<map version='):
print('it is not freemind map file.')
sys.exit(3)
fr.close()
# 读取文件 file_name
R = getXmlData(f1)
f2 = fn +'.csv'
fp = codecs.open(f2, 'w', encoding='cp936')
fp.write('应用系统名,测试功能描述,正反向,执行步骤,预期结果\n')
# zd?:字段?的拼音缩写
# zd1: 应用系统名的英文或拼音缩写
# zd2: 模块名
# zd3: 正向 或 反向
# zd4: 功能名
# zd5: 执行步骤
# zd6: 预期结果
for node in R:
if node[1] ==1:
zd1 = node[3]['TEXT']
elif node[1] ==2:
zd2 = node[3]['TEXT']
elif node[1] ==3:
zd3 = node[3]['TEXT']
elif node[1] ==4:
zd4 = node[3]['TEXT']
elif node[1] ==5:
txt = node[3]['TEXT']
if txt.startswith('步骤'):
zd5 = txt[3:]
elif txt.startswith('预期结果'):
zd6 = txt[5:]
csgnms = '-'.join((zd2,zd4)) # 测试功能描述
line = f'"{zd1}","{csgnms}","{zd3}","{zd5}","{zd6}"\n'
fp.write(line)
else:
zd5 =''
zd6 =''
fp.close()
print(f'gen: {f2}')
请注意这一关键语句: children_node = root_node.getchildren()
运行 python fpmm_etree_csv.py your_test.mm
生成 your_test.csv
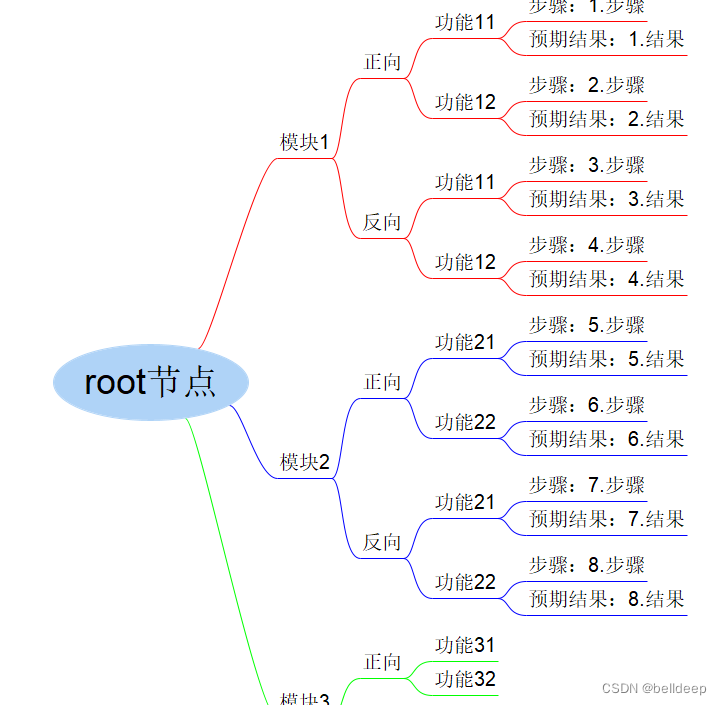
应用系统名,测试功能描述,正反向,执行步骤,预期结果
"root节点","模块1-功能11","正向","1.步骤","1.结果"
"root节点","模块1-功能12","正向","2.步骤","2.结果"
"root节点","模块1-功能11","反向","3.步骤","3.结果"
"root节点","模块1-功能12","反向","4.步骤","4.结果"
"root节点","模块2-功能21","正向","5.步骤","5.结果"
"root节点","模块2-功能22","正向","6.步骤","6.结果"
"root节点","模块2-功能21","反向","7.步骤","7.结果"
"root节点","模块2-功能22","反向","8.步骤","8.结果"


















 1355
1355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









