




 本文介绍了一种使用深度优先搜索(DFS)算法来计算矩阵中由相邻1组成的团的数量的方法。通过遍历矩阵并标记已访问的单元格,确保不重复计算同一团内的1。实例代码演示了如何实现这一过程。
本文介绍了一种使用深度优先搜索(DFS)算法来计算矩阵中由相邻1组成的团的数量的方法。通过遍历矩阵并标记已访问的单元格,确保不重复计算同一团内的1。实例代码演示了如何实现这一过程。
Given a matrix with 1s and 0s, please find the number of groups of 1s. A group is defined by horizontally or vertically adjacent 1s. For example, there are four groups of 1s in figure below.
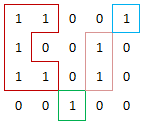
Analysis: Use DFS.
public class NumberOfGroups {
public static void main(String[] args) {
int[][] input = {{1, 1, 0, 1, 1}, {1, 0 ,0 , 1, 0}, {1, 1, 1, 1, 0}, {0, 0, 1, 0, 0}};
System.out.println(new NumberOfGroups().getNumberofGroups(input));
}
public int getNumberofGroups(int[][] input) {
boolean[][] visited = new boolean[input.length][input[0].length];
int count = 0;
for (int i = 0; i < input.length; i++) {
for (int j = 0; j < input[0].length; j++) {
if (input[i][j] == 1 && visited[i][j] == false) {
count++;
traverse(input, visited, i, j);
}
}
}
return count;
}
public void traverse(int[][] input, boolean[][] visited, int i, int j) {
if (i < 0 || i >= input.length || j < 0 || j >= input[0].length
|| visited[i][j] == true || input[i][j] == 0) return;
visited[i][j] = true;
traverse(input, visited, i - 1, j);
traverse(input, visited, i + 1, j);
traverse(input, visited, i, j - 1);
traverse(input, visited, i, j + 1);
}
}

















 5553
5553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









