




 本文详细介绍了在Ubuntu18.04LTS、Python3.6.5和Spark2.3.1环境下,使用PyCharm2018.2.1进行PySpark开发的安装步骤和配置方法,并通过读取哈利波特全书进行topN排序测试,验证安装成功。
本文详细介绍了在Ubuntu18.04LTS、Python3.6.5和Spark2.3.1环境下,使用PyCharm2018.2.1进行PySpark开发的安装步骤和配置方法,并通过读取哈利波特全书进行topN排序测试,验证安装成功。
机器环境是Ubuntu18.04LTS、python3.6.5和spark2.3.1,开发IDE是PyCharm 2018.2.1 (Community Edition),都已经安装完毕。主要介绍如何安装python开发spark程序。
一、安装相关包
1. 安装pyspark
sudo pip3 install pyspark2. 安装py4j
spark的python版开发API依赖py4j,需要安装py4j
sudo pip3 install py4j二、配置和测试
1. 配置
配置pycharm环境主要有两个,SPARK_HOME和PYTHONPATH。打开RUN->Edit Configurations如下图
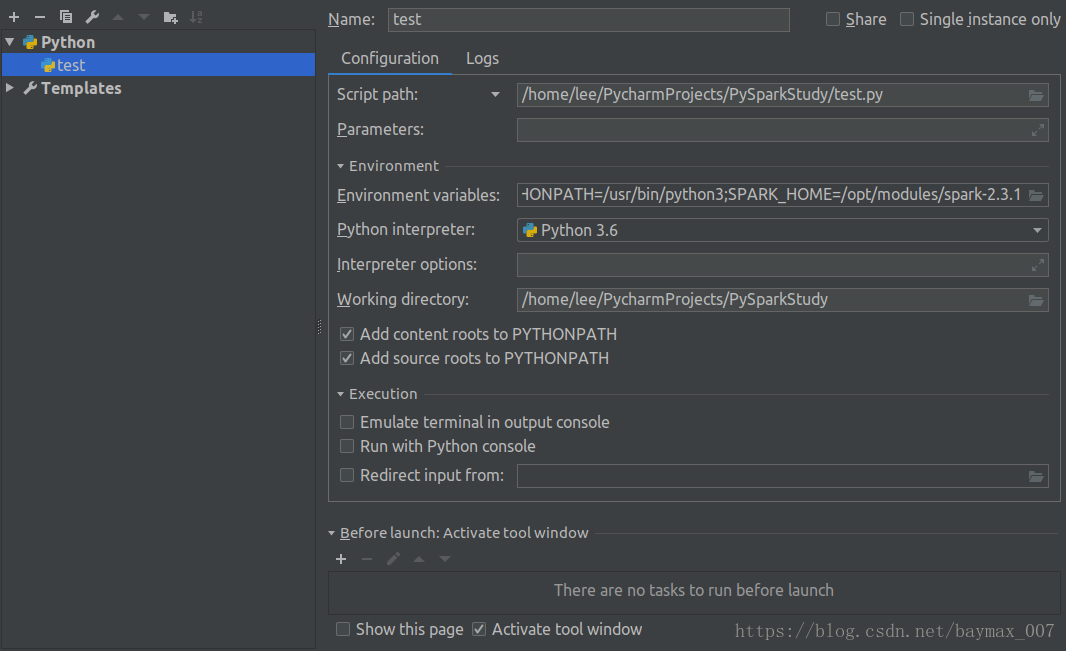
编辑Environment variables
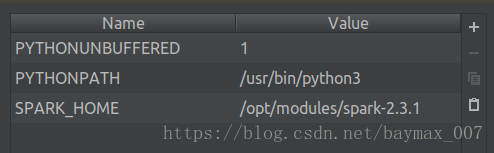
2. 测试
读取哈利波特全书,topN排序
sc = SparkContext("local","Simple App")
# 设置Log级别
sc.setLogLevel('ERROR')
# 读取HarryPotter文件
text = sc.textFile("/opt/data/HarryPotter.txt",2)
'''
(1) 匹配字母数字及下划线并分割
(2) KV转换
(3) key聚合
(4) value排序
(5) 取top N
'''
words = text.flatMap(lambda line: re.split('\W+', line)).map(lambda x: (x, 1)).reduceByKey(lambda x,y : x + y).sortBy(lambda x: x[1], False).take(20)
print(words)
==================================================================================
18/08/16 15:54:04 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
[('', 95574), ('the', 47792), ('to', 26809), ('and', 25628), ('of', 21571), ('a', 19942), ('Harry', 18127), ('he', 16192), ('was', 15514), ('said', 14387), ('s', 14235), ('his', 13699), ('I', 13444), ('in', 12340), ('you', 11770), ('it', 11758), ('had', 10035), ('that', 9990), ('at', 8343), ('t', 7674)]
Process finished with exit code 0
参考文献
https://blog.youkuaiyun.com/ydc321/article/details/78903240
https://blog.youkuaiyun.com/wmh13262227870/article/details/77992608


















 6245
6245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









