




 本文详细记录了在集群上启动Hadoop和Spark的过程,包括遇到的无法加载本地库的警告、Yarn应用已结束的错误,以及在运行Python Spark程序时的挑战。通过检查依赖库、配置环境变量和解决Java库路径问题,最终成功运行程序,但Web界面仍显示失败。此外,还指出了Spark shell在yarn-cluster模式下不适用的情况。
本文详细记录了在集群上启动Hadoop和Spark的过程,包括遇到的无法加载本地库的警告、Yarn应用已结束的错误,以及在运行Python Spark程序时的挑战。通过检查依赖库、配置环境变量和解决Java库路径问题,最终成功运行程序,但Web界面仍显示失败。此外,还指出了Spark shell在yarn-cluster模式下不适用的情况。
启动hadoop
root@master:/usr/local/hadoop-2.7.5/sbin#./start-all.sh
This script is Deprecated. Instead use start-dfs.shand start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to/usr/local/hadoop-2.7.5/logs/hadoop-root-namenode-master.out
slave02: starting datanode, logging to/usr/local/hadoop-2.7.5/logs/hadoop-root-datanode-slave02.out
slave01: starting datanode, logging to/usr/local/hadoop-2.7.5/logs/hadoop-root-datanode-slave01.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to/usr/local/hadoop-2.7.5/logs/hadoop-root-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to/usr/local/hadoop-2.7.5/logs/yarn-root-resourcemanager-master.out
slave02: starting nodemanager, logging to/usr/local/hadoop-2.7.5/logs/yarn-root-nodemanager-slave02.out
slave01: starting nodemanager, logging to/usr/local/hadoop-2.7.5/logs/yarn-root-nodemanager-slave01.out
root@master:/usr/local/hadoop-2.7.5/sbin#
启动spark
root@master:/usr/local/spark/sbin# ./start-all.sh
starting org.apache.spark.deploy.master.Master,logging to/usr/local/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
slave01: starting org.apache.spark.deploy.worker.Worker,logging to/usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave01.out
slave02: startingorg.apache.spark.deploy.worker.Worker, logging to/usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave02.out
slave01: failed to launchorg.apache.spark.deploy.worker.Worker:
slave01: full log in/usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave01.out
slave02: failed to launchorg.apache.spark.deploy.worker.Worker:
slave02: full log in/usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave02.out
root@master:/usr/local/spark/sbin#
查看运行情况
root@master:/usr/local/spark/sbin#jps
3042 Master
3124 Jps
2565 NameNode
565ResourceManager
2758SecondaryNameNode
root@slave01:/usr/bin#jps
1152 Jps
922 NodeManager
812 DataNode
1084 Worker
root@slave02:/usr/local/spark/python/lib#jps
993 Worker
721 DataNode
1061 Jps
831 NodeManager
查看web界面
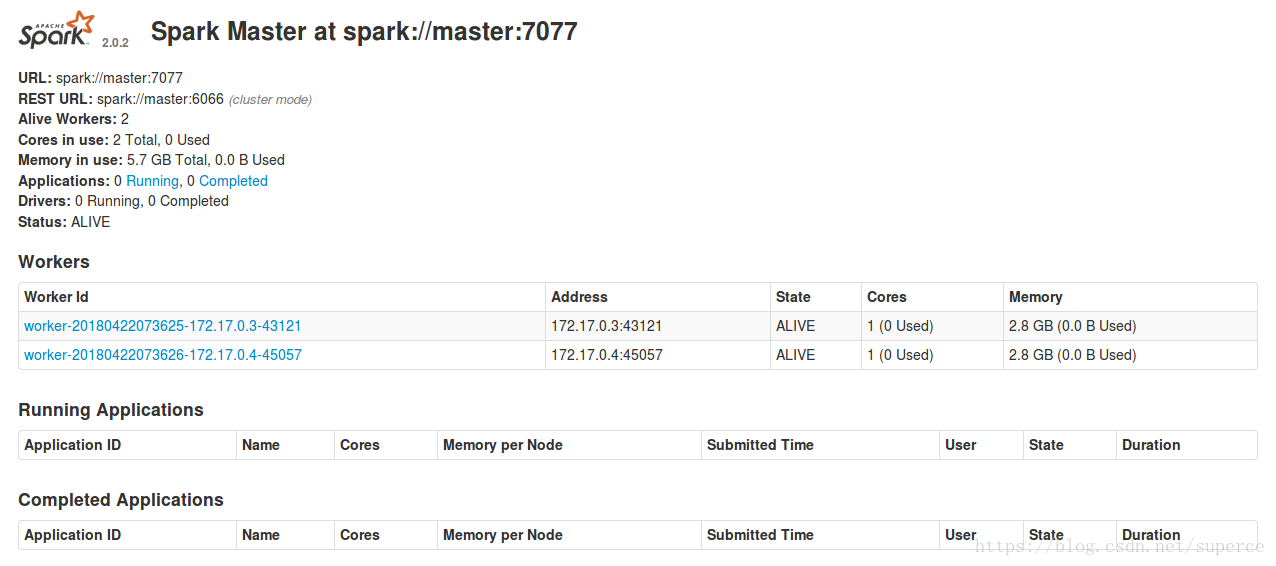
在宿主机(即在安装docker的虚拟机中),打开浏览器,输入master的IP:8080查看,此时宿主机是可以访问docker中的容器的
运行python程序
root@master:~/pysparkfile#python3 text.py
Setting defaultlog level to "WARN".
To adjustlogging level use sc.setLogLevel(newLevel).
SLF4J: Classpath contains multiple SLF4J bindings.
SLF4J: Foundbinding in[jar:file:/usr/local/spark/jars/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Foundbinding in [jar:file:/usr/local/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindingsfor an explanation.
SLF4J: Actualbinding is of type [org.slf4j.impl.Log4jLoggerFactory]
18/04/2207:50:11 WARN util.NativeCodeLoader: Unable to load native-hadoop library foryour platform... using builtin-java classes where applicable
Lines with a:61, Lines with b: 27
查看web界面并没有什么变化
启动pyspark
root@master:/usr/local/spark# pyspark
/usr/local/spark/bin/pyspark: line 53: python:command not found
Python 3.5.2 (default, Nov 23 2017, 16:37:01)
[GC
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









