




- 前言
人体姿态估计是MSCOCO数据集(http://cocodataset.org/)上面的一项比赛,人体关键点检测,目前主流的做法都是深度学习来做。可以分为两个大的方向:
(1)top-down方向:自顶向下的方法,目前的主流,像cpn,hourglass,cpm,alpha pose等都是top-down。主要分为两个阶段,行人检测和单人姿态估计,行人检测对后面的单人姿态估计影响很大,通常会使用性能较好的检测器(比如faster rcnn,fpn之类的),然后把检测到的行人框(bbox)作为单人姿态估计的输入,所以把行人准确无误的检测出来非常重要。
(2)bottom-up方向:自底向上方法,典型就是COCO2016年人体关键点检测冠军open pose。主要分为两个阶段:检测出输入图片中左右的人体关键点,根据某种策略对关键点之间进行连线,这时候就容易出现把a的关键点和b的关键点连接起来,open pose里面的策略是提出PAFs,让网络学习人体关节的矢量场信息,相当于得到了一个方向信息,结合前面的坐标点,可以确定连线。
2.构建网络
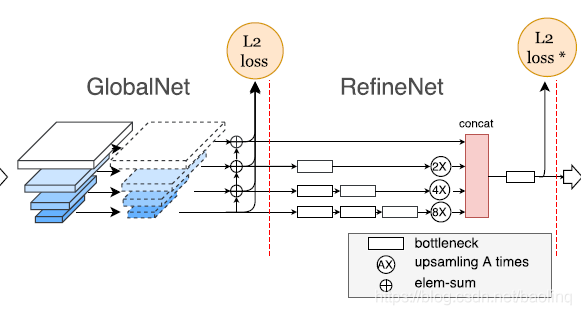
CPN网络整体结构非常的直观明了,包含两个部分GlobalNet和RefineNet,顾名思义,GlobalNet是一个全局的初步的检测,相当于一个粗检测,会得到一个不错的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3680
3680




 到【灌水乐园】发言
到【灌水乐园】发言







