







 本文概述了移动机器人路径规划的几种主要方法,包括基于图搜索的规划(D*、LPA*、D* Lite 和 Field D*)和基于采样的规划(PRM、RRT及其变种)。路径规划过程涉及信息感知、决策、控制等步骤,这些方法各有优劣,适用于不同的环境和需求。基于图的搜索方法需要全局信息,而基于采样的方法则适用于高维和动态环境。此外,还介绍了插值曲线规划,如直线、圆、回旋曲线、多项式曲线和贝塞尔曲线,用于生成平滑路径。
本文概述了移动机器人路径规划的几种主要方法,包括基于图搜索的规划(D*、LPA*、D* Lite 和 Field D*)和基于采样的规划(PRM、RRT及其变种)。路径规划过程涉及信息感知、决策、控制等步骤,这些方法各有优劣,适用于不同的环境和需求。基于图的搜索方法需要全局信息,而基于采样的方法则适用于高维和动态环境。此外,还介绍了插值曲线规划,如直线、圆、回旋曲线、多项式曲线和贝塞尔曲线,用于生成平滑路径。
路径规划方法综述
概述
在路径规划中,几个名词的含义为:
完备性:是指如果在起始点和目标点间有路径解存在,那么一定可以得到解,如果得不到解那么一定说明没有解存在;
概率完备性:是指如果在起始点和目标点间有路径解存在,只要规划或搜索的时间足够长,就一定能确保找到一条路径解;
最优性:是指规划得到的路径在某个评价指标上是最优的(评价指标一般为路径的长度);
渐进最优性:是指经过有限次规划迭代后得到的路径是接近最优的次优路径,且每次迭代后都与最优路径更加接近,是一个逐渐收敛的过程;

路径规划的过程大致如下图所示,主要包括信息获取-感知-通信-决策-控制-执行,一般狭义的路径规划指的是决策部分。
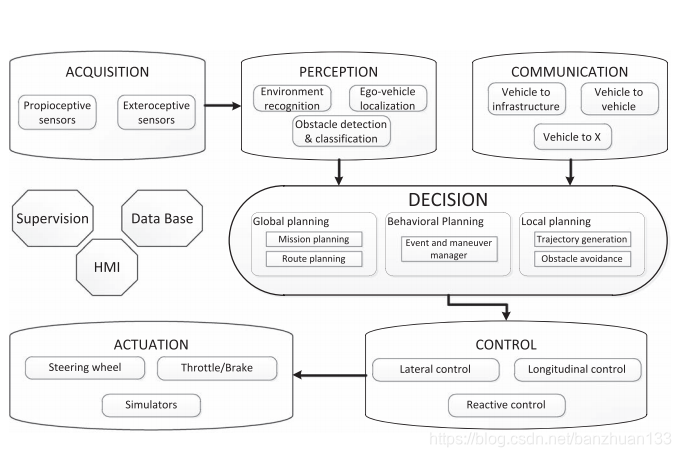
主要方法
基于图搜索的规划方法
基于图搜索的方法是最常见的路径规划方法,不仅在机器人,甚至在网络中(如路由的寻路转发中)也有广泛的应用。
几种经典的方法,包括Floyd,Bellman-Ford,Dijkstra,A*我在这里就不赘述了,相关的资料以及十分齐全了。这里主要介绍一些A*的改进版。
D*
D*是Anthony Stentz 1994年发表在ICRA上的, Optimal and Efficient Path Planning for Partially-KnownEnvironments 。关于D*算法我之前写了一篇博客,感兴趣可以戳链接。相比A-star算法,D-star的主要特点就是由目标位置开始向起始位置进行路径搜索,当物体由起始位置向目标位置运行过程中,发现路径中存在新的障碍时,对于目标位置到新障碍之间的范围内的路径节点,新的障碍是不会影响到其到目标的路径的。新障碍只会影响的是物体所在位置到障碍之间范围的节点的路径。通过将新的障碍周围的节点加入到Openlist中进行处理然后向物体所在位置进行传播,能最小程度的减少计算开销。D*路径搜索的过程和Dijkstra算法比较像,A-star算法中f(n)=g(n)+h(n),h(n)在D-star中并没有体现,路径的搜索并没有A-star所具有的方向感,即朝着目标搜索的感觉,这种搜索更多的是一种由目标位置向四周发散搜索,直到把起始位置纳入搜索范围为止,因此,D_star算法虽然能够在障碍物发生变化时找到一条路径,但不一定是一条最短的路径
LPA*
Lifelong Planning A*是Sven Koenig 和 Maxim Likhachev在2004发表在Artificial Intelligence上的。这个方法在A*的基础上,加了一步对cost变化的处理。定义了一个rhs函数
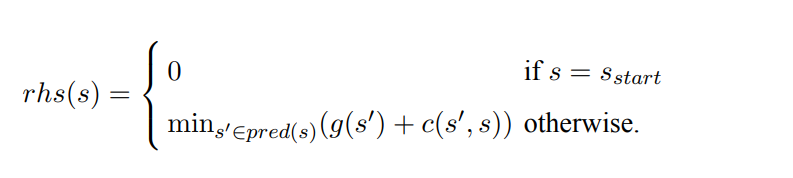
rhs函数的作用是通过前瞻一步的方式来判断cost的变化。同时定义了三种状态

处于局部一致状态就是说明环境中的最短路径没有发生改变,处于过一致状态说明可以通过改变父节点降低当前的cost,处于欠一致状态则说明由于某个父节点的cost发生变化导致最短路径的cost变大,需要重新规划。伪代码中对应的是下图红框部分

主要思想是当某个节点不可达时,将以其为父节点的子节点放入U中重新考察,同时利用之前探索的部分继续向目标拓展,直到重新规划出一条可以到达目标的路径。因为这一类方法是通过对以前搜索的信息进行再利用来减少搜索空间,所以又称为增量式搜索。
LPA*和A*一样,可以通过启发函数来减少搜索空间,同时可以解决环境发生变化的情况。缺点就是,同D*不同,它是从起点向终点搜索,这就意味着,当机器人移动后,他必须重新计算启发函数再进行搜索,会造成很大的浪费。
D* Lite 和Field D*
D* Lite还是上面两个老哥在2005年发表在Trans of Robotics上,Fast Replanning for Navigation in Unknown Terrain
为了解决之前所说的LPA的问题,很自然地想到是否可以将LPA和D结合起来,没错,这就是D Lite。D* Lite 的逻辑基本和LPA*差不多,不过是从终点向起点扩展,这里也不多介绍了。不过科研就是发现问题和解决问题,很快,又有人提出新的问题了,基于图的方法总是将图划分成栅格,再在栅格中心移动,这样实际限制了机器人的移动。举个例子,下图机器人从左下到右上肯定是走红线比较近,但是如果按照图搜索每次移动一个栅格来规划的话,得到的路径就是蓝线。
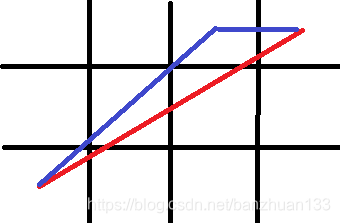
那理所应当的想法就是不一定非要走栅格中心,这就是Field D*了,2005年由David Ferguson 和 Anthony (Tony) Stentz 提出,主要思想是我不用之前那种从一个中心到另
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2111
2111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









