






导语:当DeepSeek大模型遇上国产算力“百家争鸣”,企业如何用最低成本实现ChatGPT级AI能力?本文深度解析15+主流厂商方案,重点拆解优刻得如何以“开箱即用+国产芯片全适配”重新定义行业门槛!
一、头部厂商全矩阵
1. 优刻得DeepSeek一体机
-
配置:预置DeepSeek全系列模型(7B-671B),支持沐曦、昇腾、壁仞等国产芯片
-
核心优势:
-
医疗领域:10秒完成3000页病历分析,早癌筛查效率提升8倍
-
政务领域:24小时智能问答系统,政策解读准确率超95%
-
工业领域:实时优化生产线,故障预测准确率92%
-
-
价格:经济版45万元(32B模型),企业套餐含3年运维
-
避坑:需提前规划网络带宽(建议10Gbps以上)
2. 华为昇腾Atlas一体机
-
配置:昇腾910B×8 + 鲲鹏920 + 32TB存储
-
优势:支持2000人并发,预置20个行业模型,政务采购可享30%补贴
-
适用场景:金融风控、军工保密项目
3. 联想训推一体机
-
配置:AMD EPYC + 沐曦曦云C500×8
-
亮点:支持千亿参数模型训练,送100小时驻场调优
-
价格:训练版198万元,推理版98万元
4. 浪潮云帆超融合一体机
-
配置:至强铂金9480 + NVIDIA A100×8
-
适用场景:科研机构复杂模型训练,支持671B模型推理
5. 中科曙光超融合一体机
-
配置:海光CPU/DCU + 全国产化底座
-
优势:兼容Qwen2.5、LLaMA3.2等开源模型,政企采购成本降低25%
二、高性价比黑马厂商
6. 京东云vGPU智算一体机
-
配置:国产GPU×4 + 边缘智能小站
-
价格:首年免运维,月租低至9800元
-
适用场景:电商客服、零售门店数字化
7. 科大讯飞双引擎一体机
-
配置:星火+DeepSeek双模型架构
-
优势:全栈国产化部署,教育领域应用覆盖率超70%
8. 中国长城擎天GF7280 V5
-
配置:飞腾CPU + 摩尔线程MTT S4000
-
适用场景:军工、能源等敏感行业,通过国密认证
9. 天翼云息壤智算一体机
-
配置:昇腾8卡/16卡集群 + 银河麒麟系统
-
优势:支持多卡扩展至1024卡,政务项目采购优先推荐
10. 超聚变DeepSeek一体机
-
配置:鲲鹏/海光芯片 + 满血版/蒸馏版双规格
-
适用场景:内容创作、智能营销,支持4K实时渲染
三、行业场景选型攻略
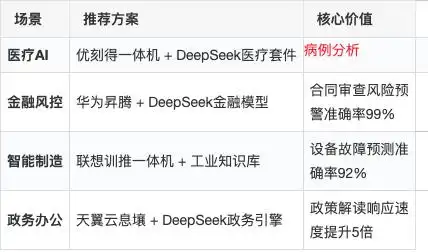
病例分析
| 场景 | 推荐方案 | 核心价值 |
|---|---|---|
| 医疗AI | 优刻得一体机 + DeepSeek医疗套件 | |
| 金融风控 | 华为昇腾 + DeepSeek金融模型 | 合同审查风险预警准确率99% |
| 智能制造 | 联想训推一体机 + 工业知识库 | 设备故障预测准确率92% |
| 政务办公 | 天翼云息壤 + DeepSeek政务引擎 | 政策解读响应速度提升5倍 |
四、优刻得深度解析:为何成为“AI平权”破局者?
-
开箱即用:预置DeepSeek全系列模型,企业可一键部署智能客服、知识库等场景
-
国产芯片全适配:率先完成沐曦、壁仞、天数智芯等国产芯片适配,降低对进口GPU依赖
-
行业解决方案:
五、实践指南
-
数据驱动:通过动态算力调度技术(如优刻得方案)实现资源利用率最大化
-
协作工具:华为昇腾一体机内置ModelArts平台,支持多团队协同开发
-
持续学习:中科曙光方案支持模型微调接口,实现业务数据闭环迭代
-
模型友好:优刻得提供联网搜索、辅助编程等标准应用,降低大模型使用门槛
结语
2025年DeepSeek一体机市场已形成“头部领跑+黑马突围”格局。优刻得以“全适配+低成本+场景化”策略,正在重塑行业规则。

















 1465
1465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









