



本文深入探讨AI大模型"Lost in the Middle"问题,即模型难以处理长上下文中间信息。这一问题源于Transformer架构的Attention机制、训练数据分布偏差及RoPE编码衰减。文章提出上下文工程解决方案,包括五大实践:上下文卸载、压缩、任务隔离、分层动作空间和精细化Prompt,帮助开发者优化注意力分配,提高Agent在复杂任务中的表现。
2023年刚开始搞AI业务落地时,写了篇RAG的文章,
https://www.zhihu.com/question/625481187/answer/3313715960
当年,我们刚开始探索AI落地时,最大的焦虑是模型“不知道”,
那会的痛点集中在:
- 怎么通过外挂知识库来解决幻觉问题
- 模型的上下文窗口有限,怎么在这最宝贵的窗口中,塞入最有效的信息
尽管当时还没有“上下文工程”这一概念,但是上下文的重要性,在那时候已经体现。
只不过对于当时的模型来说,“上下文”是稀缺的。
或者说,那时候大家的认知,还停留在,只要上下文足够充足,模型就能解决一切。
短短两三年过去,随着 Agent 浪潮的爆发,我们面临的挑战发生了一百八十度的逆转:现在的焦虑不再是模型“不知道”,而是它“知道得太多了”。
主流先进模型的上下文窗口,从当时的8K,提升到128K,再到目前甚至可以支持1M这样庞大的上下文窗口。
另外,模型的推理成本,也越来越低。
还有就是,模型支持的模态,也从纯文本,到现在的多模态,图片、视频等内容的理解,也可以直接端到端的进行。
仿佛,我们只要做的,就是把能够获取的信息,一股脑的塞满给模型就行了。
这样做的问题是什么?
Agent落地难的根本原因
从现在Agent的落地情况看,幻觉仍然还是个避不开的问题。
传统的Agent开发中,当我们将数十个工具描述、上百页文档塞进那看似无限的 Context Window 时,模型并没有变得更聪明,反而开始迷失。
模型的上下文窗口成为过剩资源后,那什么变成稀缺资源了?
答案是模型的“注意力”,没错,就是Attention is all you need中,最本质的概念,注意力。
当上下文无限膨胀,模型的注意力却也被稀释的很严重。
早在2023年,业界就已经提出了模型的Lost in the Middle问题,

即:当给大语言模型提供长上下文(Long Context)时,模型往往能很好地利用位于开头和结尾的信息,但对于位于中间部分的信息,检索和利用能力会显著下降,呈现出一条显著的 “U型” 性能曲线。
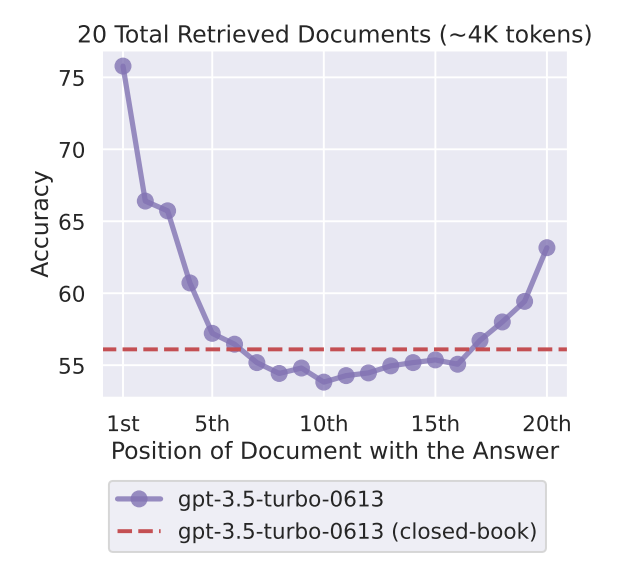
这个问题在当下主流的大模型仍然存在。
这对在开发长流程 Agent,比如
- 目前最流行的Deep Research功能,基于搜索到的上百篇网络文档,进行深度研究和梳理。
- Coding,目前的Vibe Coding工具,对整个代码库进行重构
造成了很大的阻碍。
开发时,会经常遇到这个诡异现象:
模型能清晰记得 System Prompt 中的指令(开头),也能完美响应用户的最新追问(结尾),但对于中间检索到的文档或执行过的步骤,往往视而不见。
这个问题,导致了目前的Agent,在解决实际问题时,往往不尽如人意。
面对这种资源过剩但效率低下的窘境,我们必须承认:大模型的上下文窗口不再是廉价的硬盘,而是昂贵的、需要精细管理的显存。
简单的填鸭式投喂(Prompting)已经失效。
为了在长流程任务中维持模型的清醒与专注,一个新的技术范式应运而生,上下文工程。
上下文工程的核心目标,就是对抗模型的遗忘与迷失。
让模型在每个步骤,能够获取最有价值的信息,是一种“取舍”的艺术。
我们首先从技术底层来看看“Lost in the middle”的成因。
病理剖析:为什么模型会“视而不见”?
Lost in the Middle 并非玄学,而是 Transformer 架构中数学原理与训练数据分布共同作用的必然结果。
训练数据分布
模型是数据的镜像。所谓“压缩即智能”,模型实际上学到的是人类所有数据的总和,然后用一种精妙的模式预测下一个词。
在模型的学习阶段,或者说预训练和微调阶段,模型接受到的数据往往呈现一种结构化的偏差,
大模型学习的是
即从现有的文本,输出下一个词的概率。
在人类自然语言文本(论文、新闻、小说)中,信息分布通常是不均匀的:
开头:通常是摘要、定义、背景介绍(高信息密度)。
结尾:通常是结论、总结、最新进展(高信息密度)。
而中间:通常是论证过程、细节描写或罗列数据。
模型在预训练阶段就习得了“关键信息往往在开头或结尾”的先验概率分布。
当它处理长文本时,它会倾向于认为中间部分是“过程量”,而非“结论量”。
在指令微调阶段,Prompt 的结构通常是:
- [System Instruction]
- [Context / Documents]
- [User Query]
模型被强化去响应 System Instruction(位于最前)和User Query(位于最后)。
夹在中间的 Context 往往是被动参考。
如果微调数据中缺乏针对“中间段落检索”的强监督信号(即 “大海捞针” 类的针对性训练),模型就会偷懒,只看头尾。
Attention机制的“稀释”
从Attention的公式出发,罪魁祸首其实就是这个softmax函数。
Softmax 是一个归一化函数,它的铁律是:输出的所有概率之和必须等于 1。
无论上下文窗口是 4k 还是 128k,这个“1”的总预算是不变的。
在针对流式推理(Streaming LLM)的研究中发现了一个有趣的现象:Attention Sink。
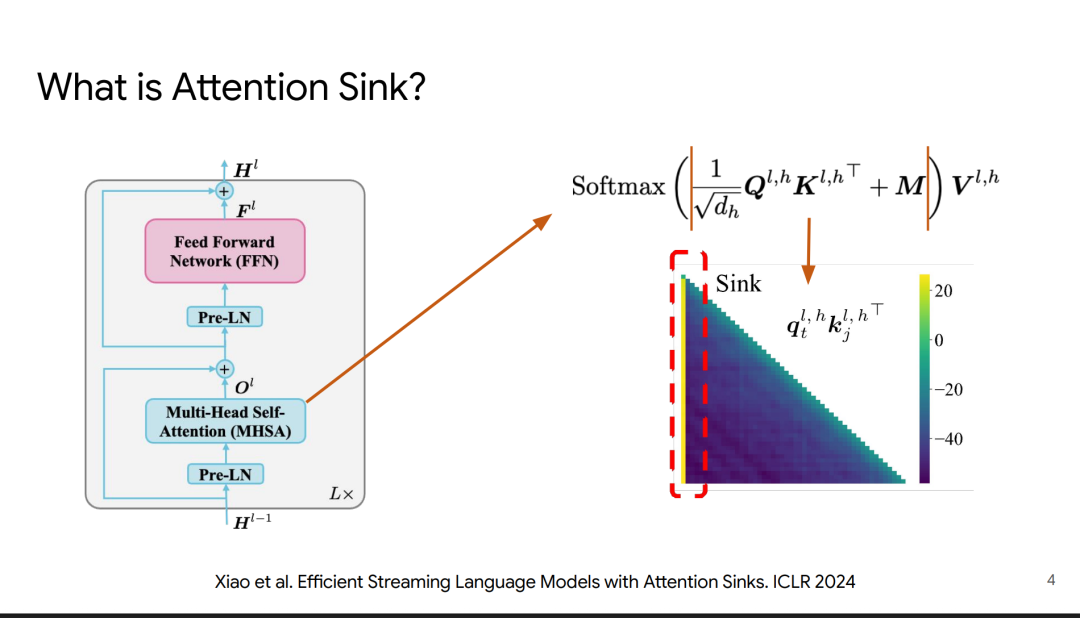
研究者发现,如果强制把开头几个 Token 的 KV Cache 丢掉,模型的 Perplexity (困惑度) 会瞬间爆炸。
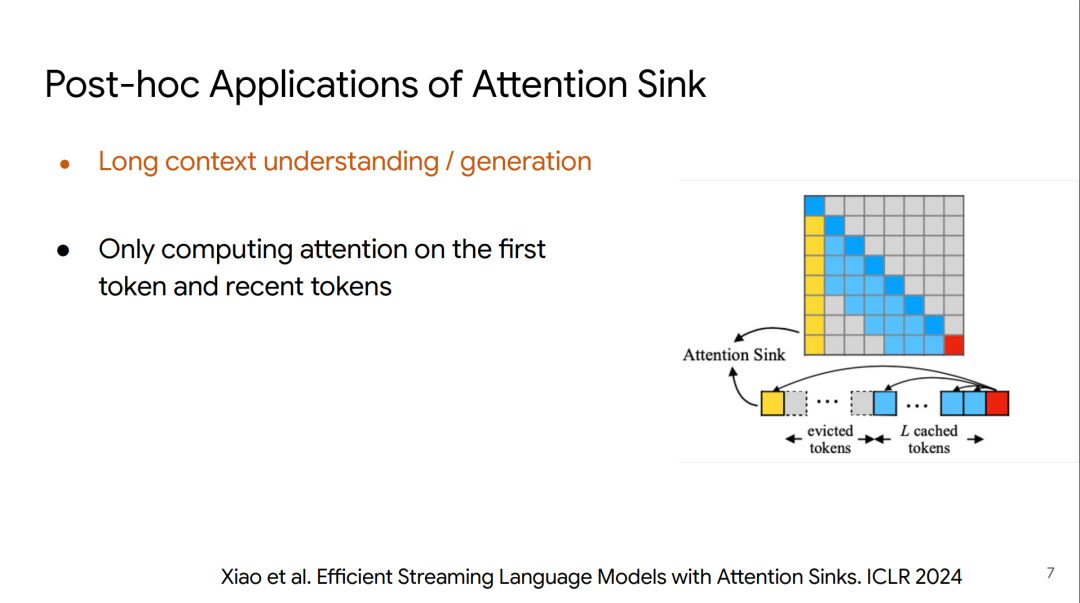
原因是,Softmax 需要所有分数加起来为 1。
如果当前 Token 对之前的任何内容都不太感兴趣,它需要一个“垃圾回收站”来安放这些剩余的概率。
结果导致模型往往将大量的注意力分数分配给序列的起始 Token(通常是start token 或 System Prompt)。
这意味着,序列开头的 Token 在 KV Cache 中占据了统治地位,进一步压缩了中间 Token 能够获得的注意力预算。
当序列长度 极度增加时(例如从 4k 到 128k),分母上的项数变多。
如果没有极其强烈的信号,中间大量的 Token 会产生很多微小的 Attention Score。
这些Attention Score,在运用于fp8甚至int4推理量化降低成本时,在量化截断后,这些微弱的信号很容易变成数值噪声,或者直接被量化为 0。
这种累积误差,导致中间的内容更加不受关注。
RoPE编码带来的长期衰减
RoPE 的设计初衷之一是让 Attention Score 随着相对距离的增加而自然衰减。
远距离衰减指的是随着q和k的相对距离的增大,加入位置编码之后的内积应该随着距离增大而减小,这样相当于离得远的token分配到的attention会比较小,而离得近的token会得到更多的注意力。
这导致了,Attention Score又有两头占优的情况。
- 结尾(Query):距离自身最近,相对位置编码带来的衰减最小,Attention 权重天然较高。
- 开头(System Prompt):虽然距离 Query 最远,但因为它是整个文本序列的“锚点”,且在训练中始终存在,模型学会在特定 Attention Head 中对绝对位置靠前的 Token 保持高权重。上文提到的Attention Sink现象就是这种情况。
- 中间:既没有近距离带来的小幅度衰减的加持,又没有“起始锚点”的特殊地位,加上距离 Query 较远,在 RoPE 的高频分量旋转下,其特征容易变得模糊。
总之,“Lost in the Middle” 并非单一原因造成,而是从算法底层到数据分布的系统性结果:
- 模型机制:Softmax 的归一化导致中间信息的注意力被稀释,且位置编码对长距离(非首尾)信号支持较弱。
- 训练数据:自然语言“头尾重要”的分布偏差,以及 SFT 中对首尾指令的过度强化。
当然了,目前业界也使用了很多方法来缓解这个问题。但是我们在应用落地的一线,不能坐以待毙,更不能把业务的稳定性寄托在黑盒模型偶尔的“超常发挥”上。
上下文工程
既然我们无法目前,暂时没法打破模型层面的瓶颈来创造无限的注意力,那么解决问题的唯一路径,就是改变注意力的分配方式。
这就是上下文工程诞生的意义。
其实上下文工程,和目前的计算机体系架构已经特别像了,类比一下,解决的是以下几个问题:
- 什么是必须留在内存(上下文)里的?
- 什么是可以存进硬盘(外部存储)的?
- 什么时候该清理内存(冗余上下文)?
- 什么时候该并行处理?
基于 Manus、Anthropic 等顶尖团队的实战经验,为了让 Agent 在处理复杂长流程任务时不再“迷失”,我梳理出了以下 五大上下文工程最佳实践。
这套方法论的核心,就是要在有限的注意力预算下,实现模型效能的最大化。
上下文卸载(Offloading)
原则:不要将所有信息都堆在消息历史中。
对于网页抓取的结果、文档、CSV 数据等可能带来超长上下文的内容,应该存储到文件系统或沙箱环境中,
模型接受的信息应该只是文件路径或极简引用。
这个信息通常只包含:文件路径、执行状态、以及一小段核心摘要,例如:
{"status": "success", "file_path": "/sandbox/data/search_results.csv", "preview": "已找到50家公司的财务数据"}
这样,模型可以意识到完整数据已安全存储在外部,它可以根据预览信息决定下一步是继续搜索,还是深入读取该文件。
当模型需要获取文件中的具体信息时,它不应直接读取所有的内容,而是做一些精细化的检索机制,进行精确打击。
比如:
- 使用Sandbox原生的能力,可以通过 shell 命令调用 grep、cat、head 或 tail 来处理结果
- 如果文件极大,模型会执行 grep “关键词” /path/to/file 来只获取文件中相关的行。
- 对于极其复杂的分析(如分析 1GB 的日志),主 Agent 可以指定一个专门的Subagent在独立的上下文空间里读完文件,总结出符合规范的结果后,再将精简的结论返回给主Agent。
我们可以看到,目前很多主流的Coding Agent产品其实都是这么做的,比如Claude Code在重构你的代码时,会大量使用grep,来搜索跟你关心的模块的代码内容,而不是去读取整个代码库。
上下文压缩(Reduction)
当必须保留在上下文中的信息接近“预腐败阈值”(实践中通常为 128k-200k tokens)时,我们需要进行压缩。
这里的压缩,和我们平时理解的自由文本摘要并不同。而是要仔细规范一个具体的Schema,让另外的LLM,根据这个Schema来填充真正的关键信息。
from pydantic import BaseModel, Fieldfrom typing import List, Optional# 定义摘要的Schemaclass ContextSummary(BaseModel): current_goal: str = Field(..., description="当前阶段的主要目标") completed_tasks: List[str] = Field(..., description="已完成的关键任务列表") next_immediate_step: str = Field(..., description="下一步的具体行动") key_files_modified: List[str] = Field(..., description="重要且相关的文件路径列表") open_questions: Optional[str] = Field(None, description="尚未解决的问题或障碍")# 假设我们有一个函数调用 LLM 进行摘要def summarize_history(message_history: list) -> ContextSummary: summary = llm.chat_with_structure( messages=message_history, response_model=ContextSummary, prompt="请根据当前对话历史,总结关键进展。必须严格遵守输出格式。" ) return summary# 压缩后的新上下文可能只包含一个系统提示和这个结构化的摘要new_context = [ { "role": "system", "content": "...", "summary": summary.model_dump_json(indent=4) }]
除了这个方式,Manus建议,在需要执行压缩时,进行一个“可逆压缩”的步骤,
遍历消息历史,将所有已写入文件或已转储沙箱的大段内容(如 file_content)直接剔除,只保留其引用的 file_path。
因为文件已经在文件系统里了,模型随时可以通过路径重新读取。这种压缩是完全可逆的,不会丢失任何推理依据。
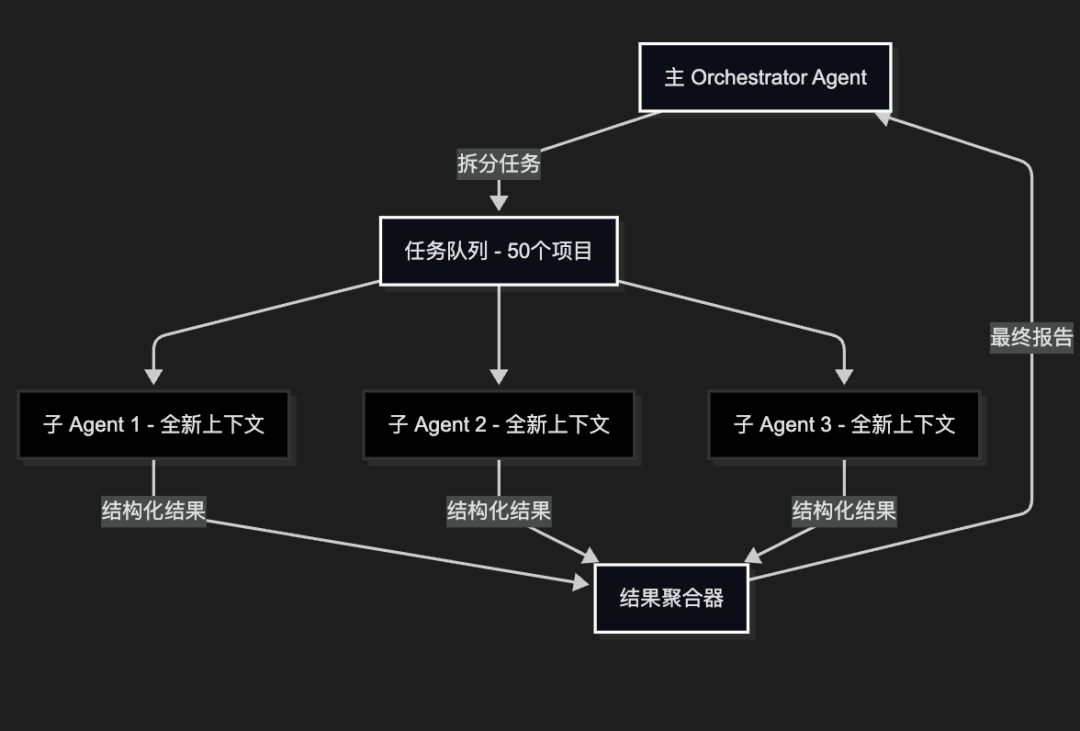
任务隔离(Isolation)—— 从单线程到并行处理
这是解决Agent长流程任务的最有效方法。放弃顺序处理模式,将复杂任务分解为 个独立的子任务,部署 个并行子代理。
比如Deep Research这种Agent,并不需要一篇一篇文档这么顺序研究,而是直接并行研究,每个子Agent的上下文,仅有需要研究的这篇文档,这彻底消除了上下文污染,确保处理第 50 个文档时的质量与第 1 个完全一致。
这种方式,类似大数据处理的Map Reduce模式,没有顺序依赖的任务,不妨这么做。
分层动作空间
这是解决过多工具塞入同一个上下文导致的“上下文混淆”问题,模型在各种场景下,不知道该用哪个。
Level 1 原子能力
保留 10-20 个核心 API 调用(如读写文件、执行 Shell)。
Level 2 沙箱工具
将复杂能力(如 PDF OCR、视频转码)封装在沙箱的 CLI 接口中。
Agent 通过 Shell 调用,利用 --help 自行学习用法。
这大大减少了 Prompt 中的工具定义部分。
相比于在 Prompt 中定义一个复杂的 ocr_pdf(file, pages, language, output_format…) 函数,不如提供一个通用的 Shell 工具:
tools = [ { "name": "run_shell_command", "description": "在沙箱环境中执行 Shell 命令。用于调用 CLI 工具或操作文件。", "parameters": {"type": "object", "properties": {"command": {"type": "string"}}} }]# Agent 的实际调用过程# 1. Agent 发现需要处理 PDF,尝试探索# Agent: run_shell_command(command="ocr-tool --help")# 2. 系统返回 CLI 的帮助文档# System: "Usage: ocr-tool [OPTIONS] INPUT_FILE\nOptions:\n --lang TEXT ...\n --output TEXT ..."# 3. Agent 自行构建复杂的命令# Agent: run_shell_command(command="ocr-tool /mnt/data/report.pdf --lang chi_sim --output result.txt")
Level 3
Agent as Tool
将复杂的子工作流(Workflow)封装为一个“工具”。
主 Agent 只需调用该工具并接收符合 Schema 的最终结果,而不必关心子流程的几十步操作。
精细化Prompt
让Agent尽量多输出思维过程,要求 Agent 在调用工具前,先输出它对当前情况的评估、计划尝试的工具以及预期的结果。
这增加了模型推理的计算量,但有助于提高准确性。
由广入深:通过提示词强制 Agent 模拟人类专家。
然后先进行广度搜索了解全局(如先 ls -R 看清目录结构),再逐步缩小范围深入细节,避免一开始就钻入牛角尖。
总结
做一个好用的 Agent,底层依赖的往往不是什么惊天动地的“屠龙之术”,而是这些看似不起眼的、点点滴滴的细节。
在这波大模型落地的早期,我们总是期待有一个“全知全能”的模型横空出世,通过无限大的上下文窗口解决所有问题。
我们迷信参数的规模,迷信窗口的长度,仿佛只要模型够强,工程就不再重要。
但大模型到目前为止,不是魔法,它只是一个新的计算组件。
就像 CPU 需要缓存机制,数据库需要索引策略一样,大模型也需要精密的上下文工程来辅助其运转。
伟大的产品,往往就诞生在对这些细节的极致掌控之中。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈

















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









