



一、简介
YOLOv5🚀是一个在COCO数据集上预训练的物体检测架构和模型系列,它代表了Ultralytics对未来视觉AI方法的公开研究,其中包含了在数千小时的研究和开发中所获得的经验和最佳实践。
二、环境准备
conda环境安装见文章![]() https://blog.youkuaiyun.com/Linshaodan520/article/details/138734234
https://blog.youkuaiyun.com/Linshaodan520/article/details/138734234
- Anaconda环境准备
1、创建python>3.8的虚拟环境
conda create -n yolo5s python=3.122、激活查看已创建的conda环境
conda activate yolov5sconda env list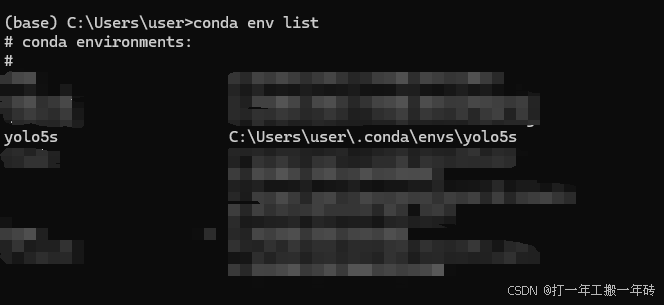
解压后通过pycharm打开,选择刚刚创建的yolov5s的conda环境为新的解释器
这里会发现存在很多依赖文件未安装
通过 pip install -r requirements.txt 命令下载导入所有需要的包
pip install -r requirements.txt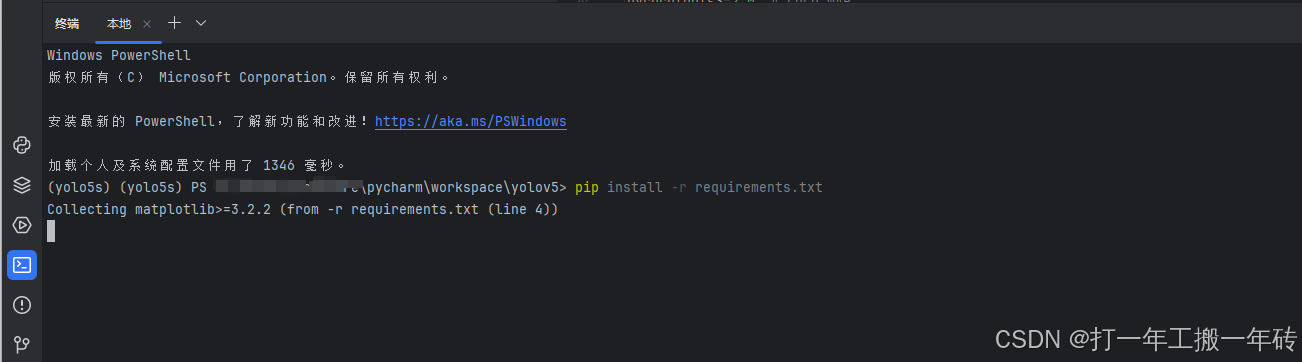
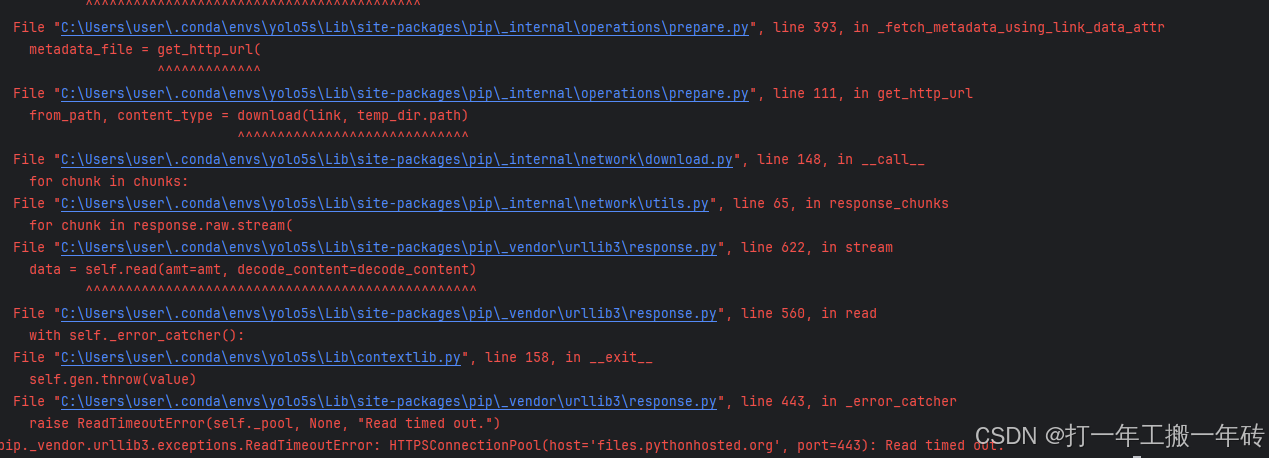
这里遇到连接超时的问题,需要换用国内清华镜像下载
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/

下载完成后需要下载预训练模型才能正常使用,选择了yolov5s(v7.0)这个轻量级版本,顺便把官方的预训练模型yolov5s.pt下载下来放在项目根目录下

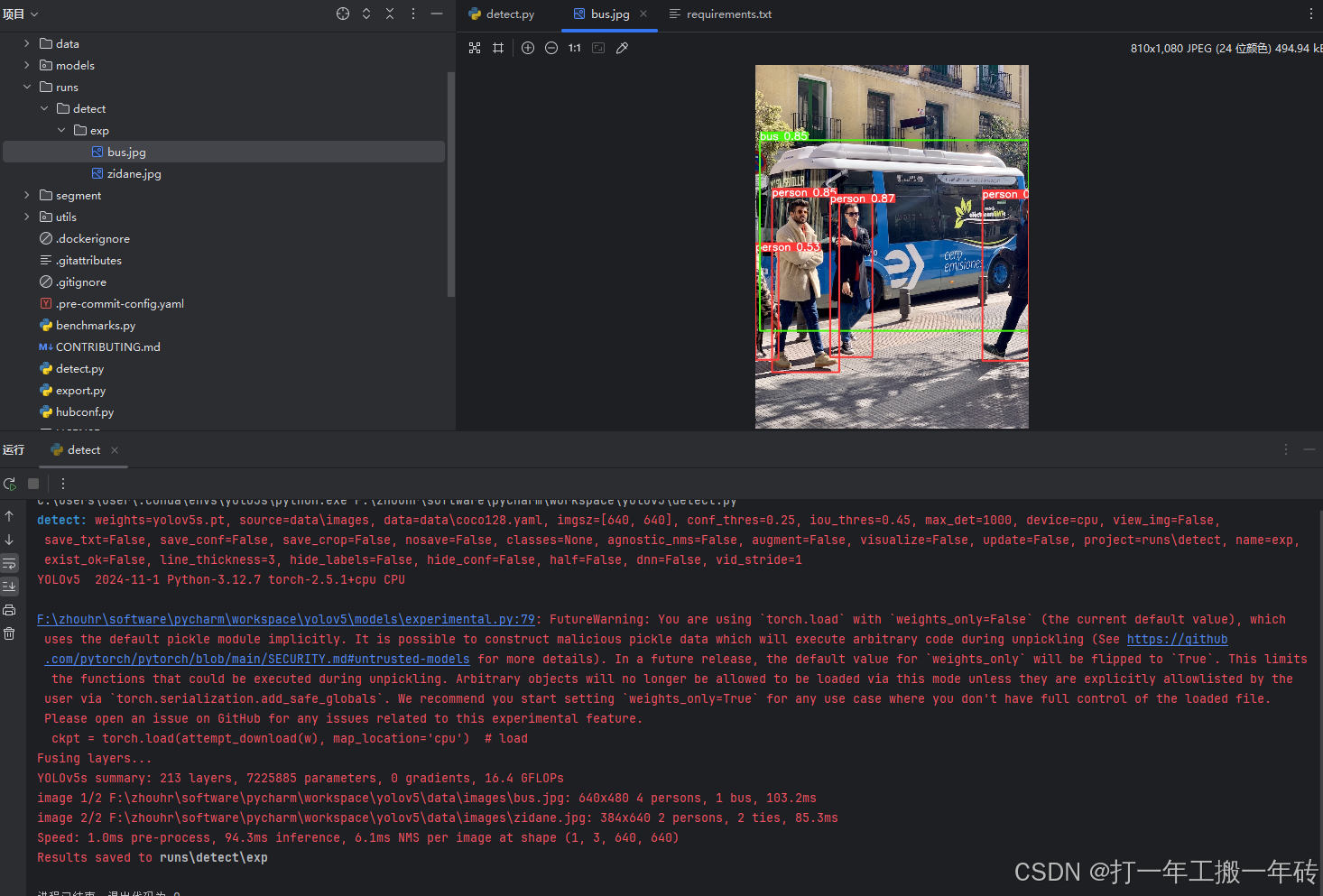
运行detect.py文件,验证成功
三、如何训练自己的模型
实例:训练一个自动检测抽烟的模型
1、收集数据集
2、数据集处理
训练前通过labelimg先进行数据标注处理,固定标签为smoke,标注完成后会在images同级目录产生Annotations目录并生成images_name.xml文件


3、划分测试集、训练集、验证集
将images和Annotations目录下的数据合并到一起
在yolov5根目录下新建mydata目录,将合并后的数据放置在下面

新建Data_set_partition.py文件
import os
import random
import xml.etree.ElementTree as ET
import shutil
from PIL import Image
# 定义数据集路径
dataset_path = "F:/xxx/smoke"
# 定义标签映射
label_map = {}
# 1. 遍历所有的xml文件,获取labels标签数量和名称
def get_labels_from_xml(xml_path):
tree = ET.parse(xml_path)
root = tree.getroot()
labels = set()
for obj in root.findall("object"):
label = obj.find("name").text
labels.add(label)
if label not in label_map:
label_map[label] = len(label_map)
return labels
# 2. 将xml文件转化成yolo格式的txt文件
def convert_xml_to_yolo(xml_path, img_width, img_height):
tree = ET.parse(xml_path)
root = tree.getroot()
yolo_lines = []
for obj in root.findall("object"):
label = obj.find("name").text
bbox = obj.find("bndbox")
xmin = float(bbox.find("xmin").text)
ymin = float(bbox.find("ymin").text)
xmax = float(bbox.find("xmax").text)
ymax = float(bbox.find("ymax").text)
# 计算YOLO格式的中心点坐标和宽高
x_center = (xmin + xmax) / 2 / img_width
y_center = (ymin + ymax) / 2 / img_height
width = (xmax - xmin) / img_width
height = (ymax - ymin) / img_height
yolo_lines.append(f"{label_map[label]} {x_center} {y_center} {width} {height}")
return yolo_lines
# 3. 按7:2:1的比例划分训练集(train)、验证集(val)、测试集(test)
def split_dataset(dataset_path):
# 创建目标目录
train_dir = os.path.join(dataset_path, "train")
val_dir = os.path.join(dataset_path, "val")
test_dir = os.path.join(dataset_path, "test")
os.makedirs(os.path.join(train_dir, "images"), exist_ok=True)
os.makedirs(os.path.join(train_dir, "labels"), exist_ok=True)
os.makedirs(os.path.join(val_dir, "images"), exist_ok=True)
os.makedirs(os.path.join(val_dir, "labels"), exist_ok=True)
os.makedirs(os.path.join(test_dir, "images"), exist_ok=True)
os.makedirs(os.path.join(test_dir, "labels"), exist_ok=True)
# 获取所有文件
files = os.listdir(dataset_path)
jpg_files = [f for f in files if f.endswith(".jpg")]
# 随机打乱文件
random.shuffle(jpg_files)
# 按比例划分
train_size = int(len(jpg_files) * 0.7)
val_size = int(len(jpg_files) * 0.2)
train_files = jpg_files[:train_size]
val_files = jpg_files[train_size:train_size + val_size]
test_files = jpg_files[train_size + val_size:]
# 复制文件到对应目录
for split, files in zip(["train", "val", "test"], [train_files, val_files, test_files]):
for file in files:
img_src = os.path.join(dataset_path, file)
label_src = os.path.join(dataset_path, file.replace(".jpg", ".txt"))
img_dst = os.path.join(dataset_path, split, "images", file)
label_dst = os.path.join(dataset_path, split, "labels", file.replace(".jpg", ".txt"))
shutil.copy(img_src, img_dst)
shutil.copy(label_src, label_dst)
# 主函数
def main():
# 获取所有xml文件路径
xml_files = [f for f in os.listdir(dataset_path) if f.endswith(".xml")]
# 遍历所有xml文件,获取labels标签数量和名称
labels = set()
for xml_file in xml_files:
xml_path = os.path.join(dataset_path, xml_file)
labels.update(get_labels_from_xml(xml_path))
print(f"Label map: {label_map}")
# 将xml文件转化为yolo格式的txt文件
for xml_file in xml_files:
xml_path = os.path.join(dataset_path, xml_file)
img_file = xml_file.replace(".xml", ".jpg")
img_path = os.path.join(dataset_path, img_file)
# 获取图像尺寸
with open(img_path, "rb") as img_f:
img = Image.open(img_f)
img_width, img_height = img.size
yolo_lines = convert_xml_to_yolo(xml_path, img_width, img_height)
# 保存yolo格式的txt文件
txt_file = xml_file.replace(".xml", ".txt")
txt_path = os.path.join(dataset_path, txt_file)
with open(txt_path, "w") as f:
for line in yolo_lines:
f.write(line + "\n")
# 划分数据集
split_dataset(dataset_path)
if __name__ == "__main__":
main()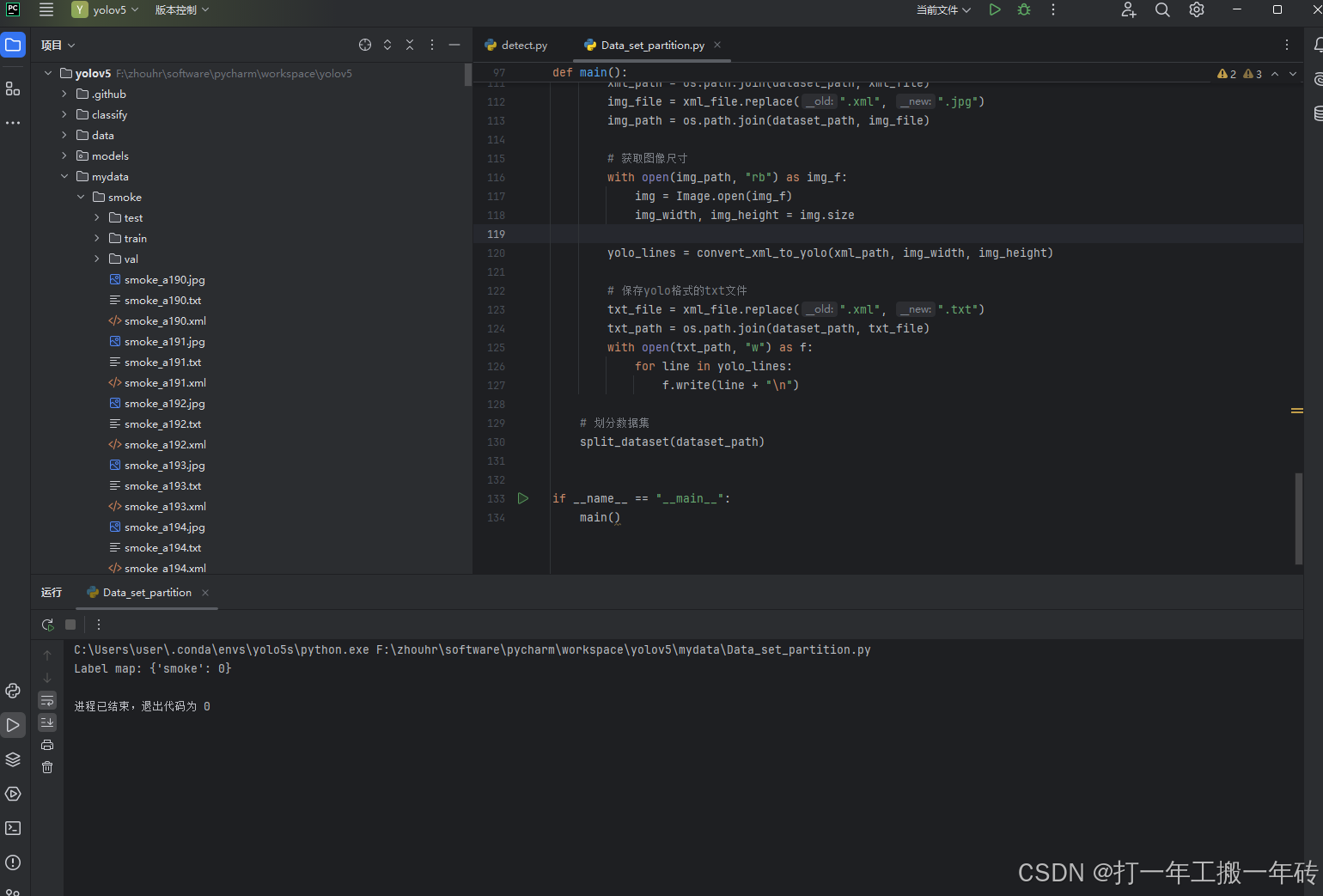
4、自定义yaml配置文件
在data目录下拷贝一份coco.ymal文件,以smoke.ymal文件保存以下内容
train: F:\xxx\smoke\train
val: F:\xxx\smoke\val
test: F:\xxx\smoke\test
# number of classes
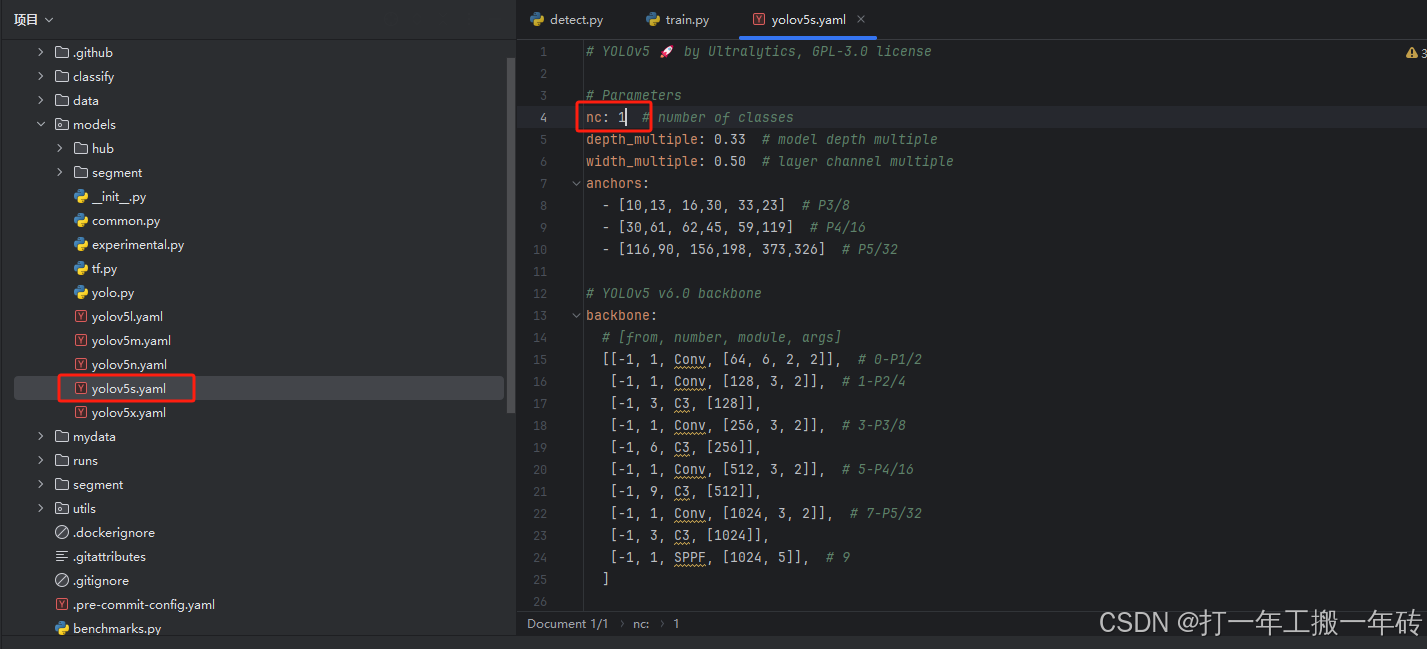
nc: 1
# class names
names: ['smoke']
修改models下yolov5s.ymal文件的nc为实际的标签数量
5、修改训练参数
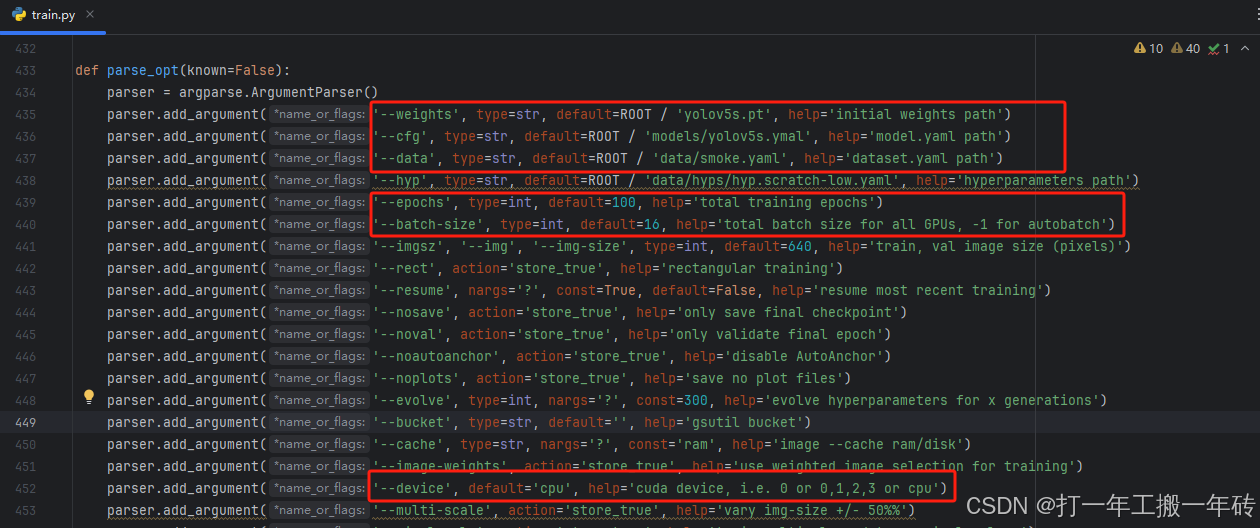
weight是配置预训练权重的路径,将default中的内容修改成下载的权重路径,也可以为空,不使用预训练权重。
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')cfg是配置模型文件的路径,将default中的内容修改成新的模型文件。
parser.add_argument('--cfg', type=str, default=ROOT / 'models/yolov5s.ymal', help='model.yaml path')data是配置数据集文件的路径,将default中的内容修改成自己的数据集yaml文件。
parser.add_argument('--data', type=str, default=ROOT / 'data/smoke.yaml', help='dataset.yaml path')hyp是模型训练过程中的超参数,可在data文件夹下选择不同的超参数。
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')epochs指训练的轮次,这里我这边在default中定了一个400次,只要模型能收敛即可。
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')batch-size是表示一次性将多少张图片放在一起训练,越大训练的越快,如果设置的太大会报OOM错误,我这边在default中设置16,表示一次训练16张图像。设置的大小为2的幂次,1为2的0次,16为2的4次。
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')img-size表示送入训练的图像大小,会统一进行缩放。要求是32的整数倍,尽量和图像本身大小一致。这边在default中设置为640。
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')device指训练运行的设备。该参数指定了模型训练所使用的设备,例如使用 GPU 运行可以指定为 default=‘0’,或者使用多个 GPU 运行可以指定为 device=0,1,2,3,如果没有可用的 GPU,可以指定为 device=‘cpu’ 使用 CPU 进行训练。
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')workers是指数据装载时cpu所使用的线程数,默认为8,过高时会报错:[WinError 1455] 页面文件太小,无法完成操作,此时就只能将default调成0了。
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')四、模型训练
模型训练
运行train.py文件,开始训练
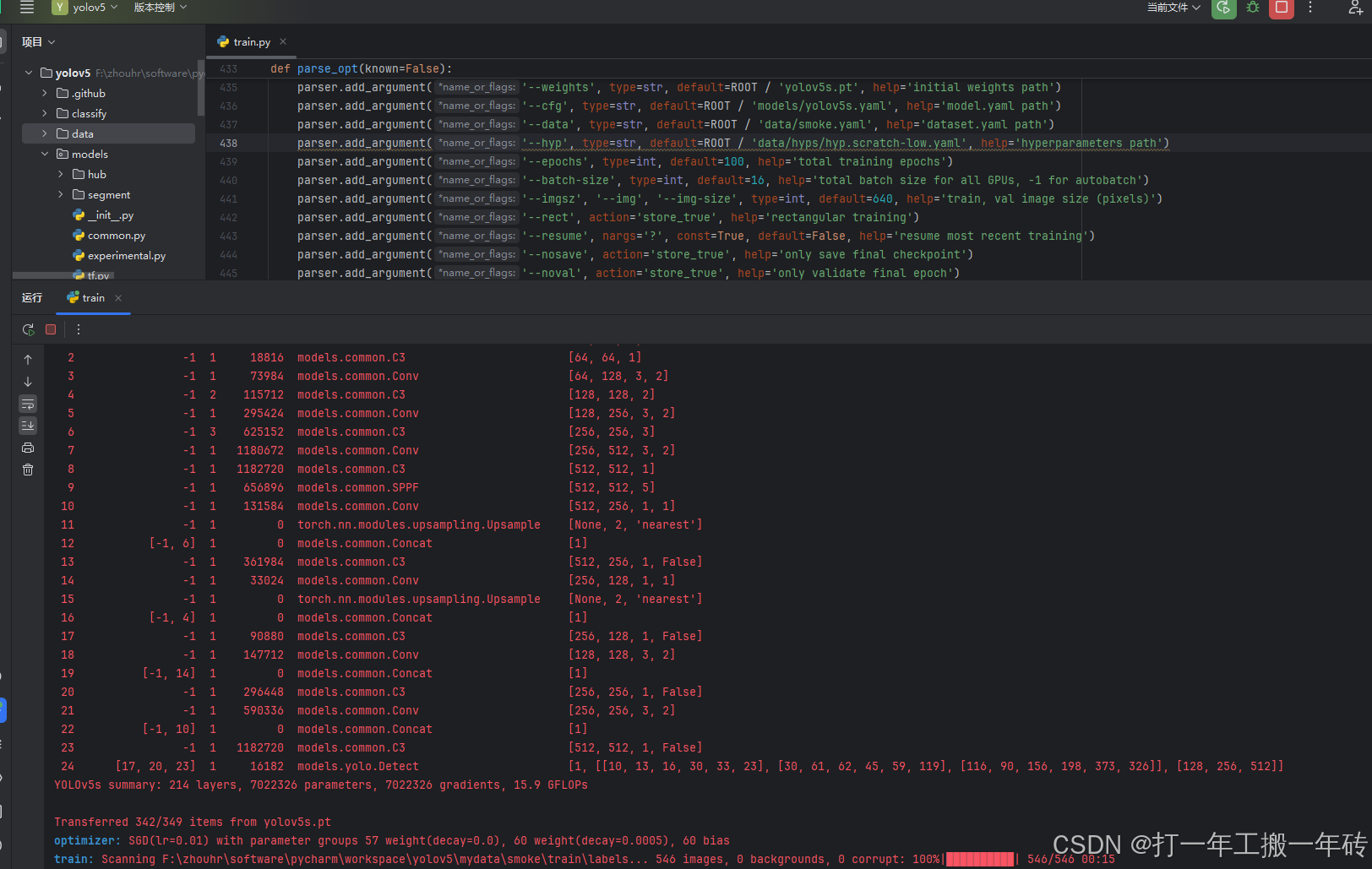
训练时可能出现的问题
1、如果出现FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead. with torch.cuda.amp.autocast(amp):
解决方法:
- 打开出现警告的文件train.py。
- 找到相关的代码行(第 307 行):
with torch.cuda.amp.autocast(amp):。- 将这行代码修改为
with torch.amp.autocast('cuda', amp):。
2、如果出现TypeError: set_autocast_dtype(): argument 'dtype' (position 2) must be torch.dtype, not bool
ValueError: Expected `device_type` of type `str`, got: `<class 'bool'>`
解决方法:
降低tourch、tourchvision、npmpy的版本
pip install tourch==2.2.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install tourchvision==0.17.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install numpy<2 -i https://pypi.tuna.tsinghua.edu.cn/simple/
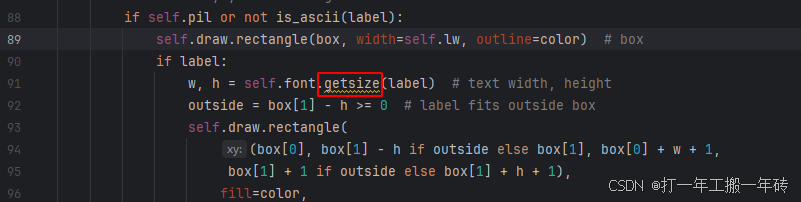
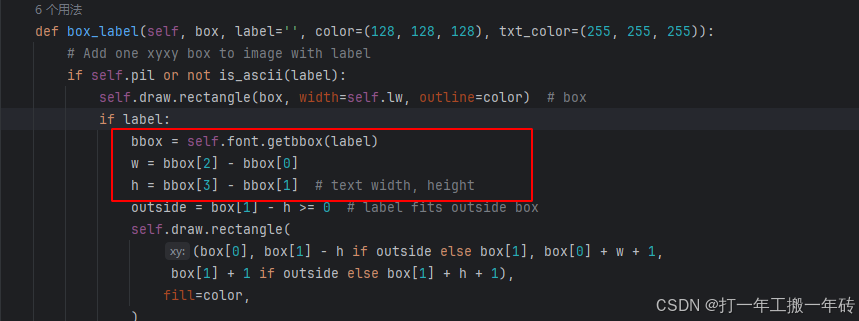
3、如果出现AttributeError: 'FreeTypeFont' object has no attribute 'getsize'
解决方法:
1、找到\utils\plots.py文件的对应报错的代码行
2、getsize方法已经不可用,修改这行代码即可
bbox = self.font.getbbox(label) w = bbox[2] - bbox[0] h = bbox[3] - bbox[1] # text width, height
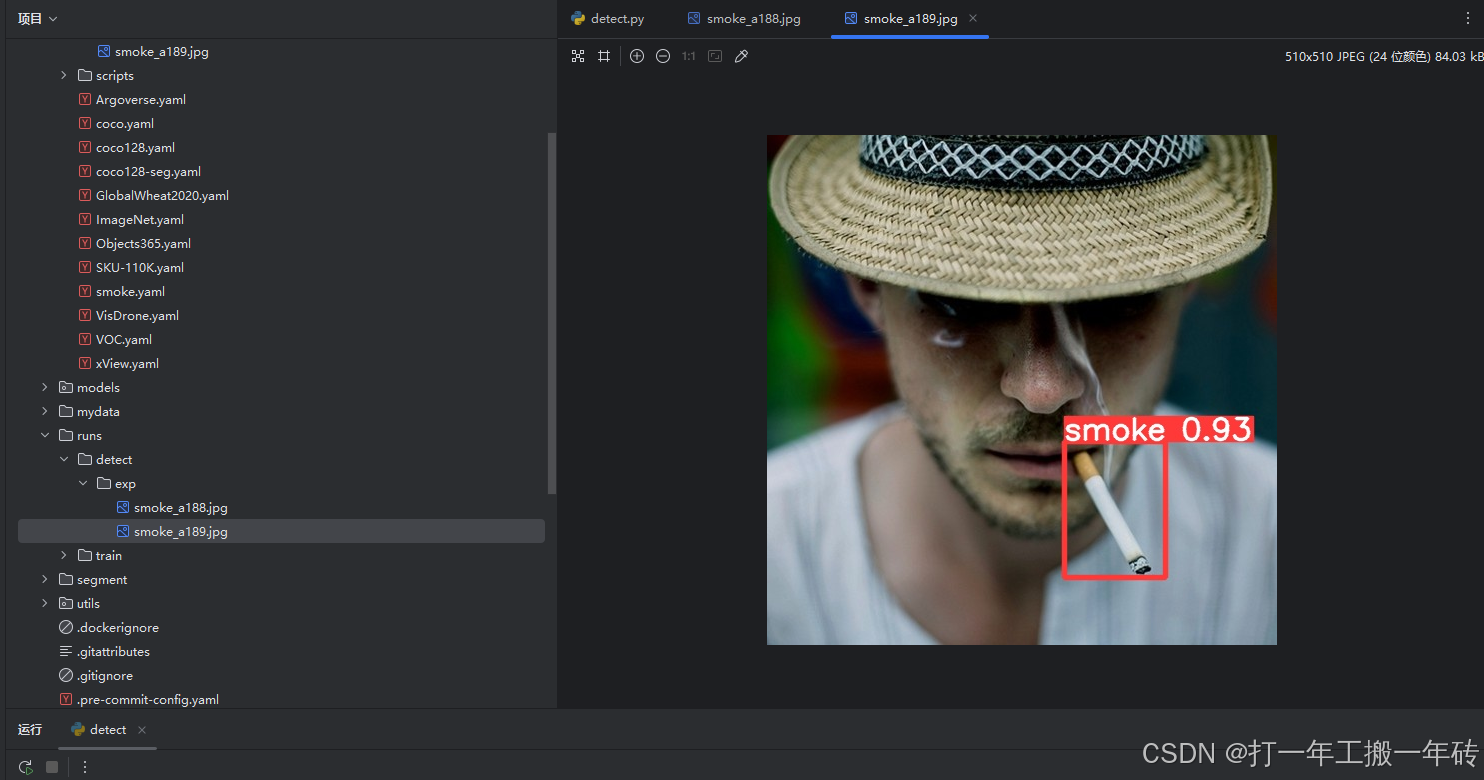
模型验证
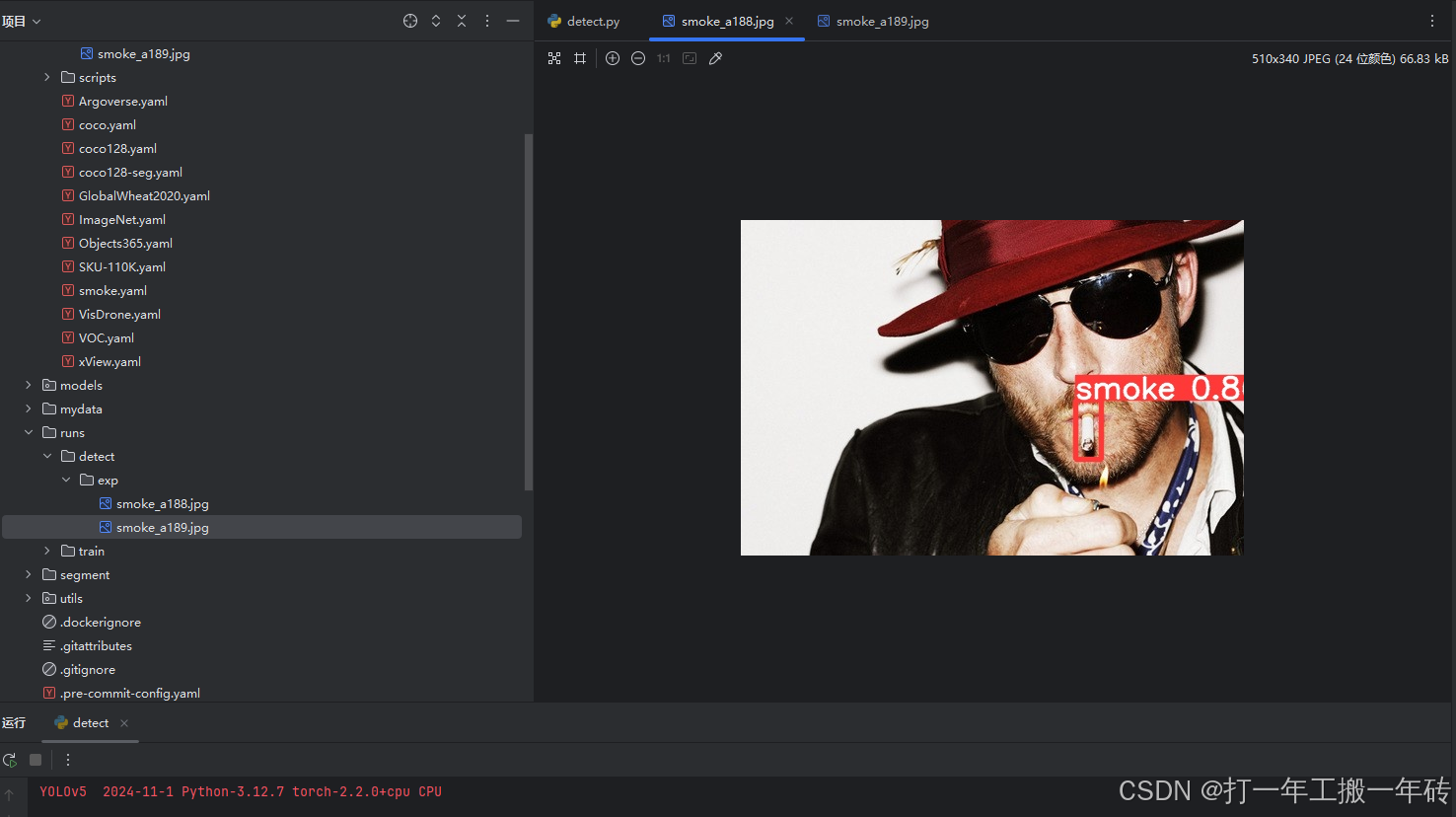
训练完成后,将会在runs/train/exp/weight文件夹下存放训练后的权重文件,detect.py替换pt和yaml为训练成功的文件,指定验证图片目录即可去进行推理验证。
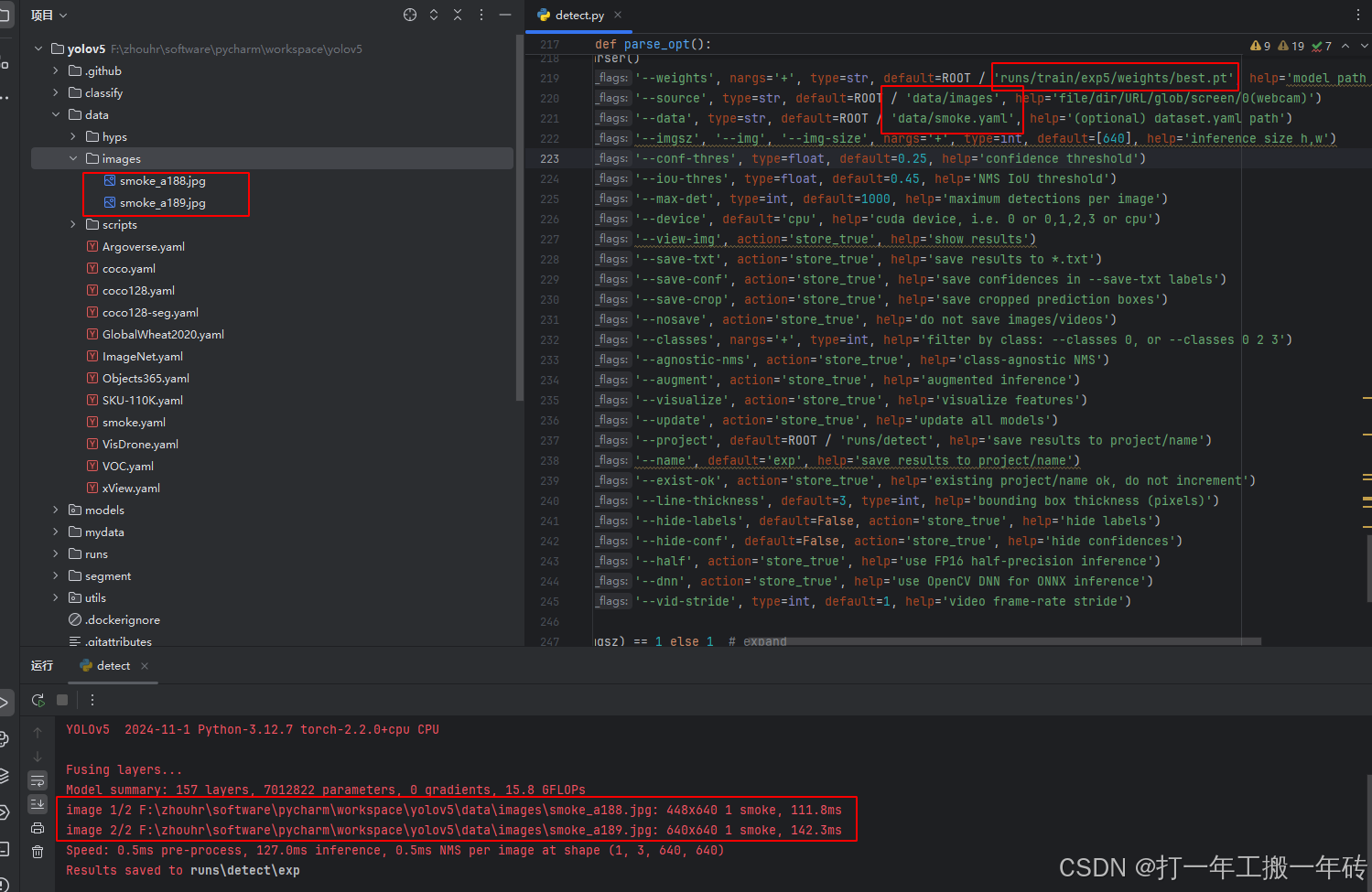
--weights:权重的路径地址
--source:测试数据,可以是图片/视频路径,也可以是'0'(电脑自带摄像头),也可以是rtsp等视频流
--output:网络预测之后的图片/视频的保存路径
--img-size:网络输入图片大小
--conf-thres:置信度阈值
--iou-thres:做nms的iou阈值
--device:是用GPU还是CPU做推理
--view-img:是否展示预测之后的图片/视频,默认False
--save-txt:是否将预测的框坐标以txt文件形式保存,默认False --classes:设置只保留某一部分类别,形如0或者0 2 3
--agnostic-nms:进行nms是否也去除不同类别之间的框,默认False
--augment:推理的时候进行多尺度,翻转等操作(TTA)推理
--update:如果为True,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息,默认为False
--project:推理的结果保存在runs/detect目录下
--name:结果保存的文件夹名称




















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











