




1 概述
现阶段视频分类算法,主要聚焦于视频整体的内容理解,给视频整体打上标签,粒度较粗。较少的文章关注时序片段的细粒度理解,同时也从多模态角度分析视频。本文将分享使用多模态网络提高视频理解精度的解决方案,并在youtube-8m 数据集中取得较大提升。
2 相关工作
在视频分类人物中,NeXtVLAD[1] 被证明是一种高效、快速的视频分类方法。受ResNeXt方法的启发,作者成功地将高维的视频特征向量分解为一组低维向量。该网络显着降低了之前 NetVLAD 网络的参数,但在特征聚合和大规模视频分类方面仍然取得了显着的性能。
RNN[2] 已被证明在对序列数据进行建模时表现出色。研究人员通常使用 RNN 对 CNN 网络难以捕获的视频中的时间信息进行建模。GRU[3] 是 RNN 架构的重要组成部分,可以避免梯度消失的问题。 Attention-GRU[4] 指的是具有注意机制,有助于区分不同特征对当前预测的影响。
为了结合视频任务的空间特征和时间特征,后来又提出了双流CNN[5]、3D-CNN[6]、以及slowfast[7]和ViViT[8]等。虽然这些模型在视频理解任务上也取得良好的表现,但还有提升的空间。比如,很多方法只针对单个模态,或者只对整个视频进行处理,没有输出细粒度的标签。
3 技术方案
3.1 整体网络结构
本技术方案是旨在充分学习视频多模态(文本、音频、图像)的语义特征,同时克服 youtube-8m数据集样本极不均衡和半监督的问题。
如Figure 1所示,整个网络主要由前面混合多模态网络(mix-Multmodal Network)和后面的图卷积网络(GCN[9])组成。mix-Multmodal Network 由三个差异化的多模态分类网络构成,具体差异化参数在Table1中。
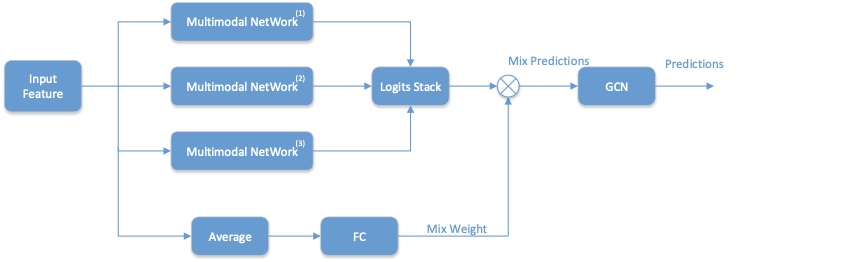
Figure 1. 整体网络结构

Table 1. 三个差异化的 Multimodal Net 的参数
3.2 多模态网络
如图Figure 2所示,多模态网络主要理解三个模态(文本、视频、音频),每个模态都包含三个过程:基础语义理解、时序特征理解、模态融合。其中,视频和音频的语义理解模型分别使用的是EfficientNet[10]和VGGish,时序特征理解模型是NextVLAD。而文本的时序特征理解模型为Bert[11]。
多模态特征融合,我们采用的是SENet[12]。SENet网络的前处理需要将各个模态的特征长度强行压缩对齐,这样会导致信息丢失。为了克服这个问题,我们采用了多Group的SENet的网络结构。实验表明,多个group的SENet网络相较于单个SENet 学习能力更强。
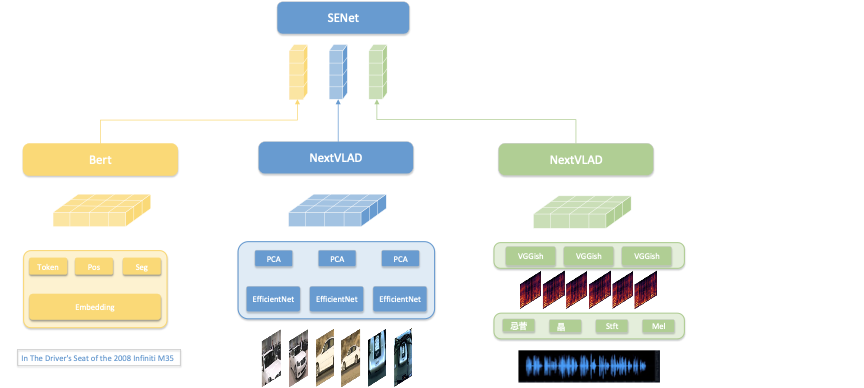
Figure 2. 多模态网络结构
3.3 图卷积
由于Youtube-8M粗粒度标签全部标注,细粒度
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 9907
9907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









