



偶然读到一篇很有意思的文章。
 原文:
原文:透过文章,可以看到人们都在通过什么样的方法试图与英伟达争夺人工智能未来的天下。
- 有人在做整片Wafer级的超超超超超超超超级GPU,可以提供90万个核心和120万GB的内存(你没看错,小编也没有手抖,的确是8个“超”字、90万和120万GB;英伟达的GB200封装了1颗Grace CPU和2颗Blackwell GPU,就叫做Superchip了,那这个Wafer级的芯片前面用8个“超”字也不为过吧)
- 有人在GPU的设计中对标了具体的应用场景(例如自然语言处理),继而采用了特殊的架构(例如时序指令集计算机架构),因此让这种GPU能够不再被内存墙困住
- 也有人正在将GPU中与图形处理相关的一些逻辑剔除掉,只保留并增强与大语言模型相关的功能,从而让这种通用GPU(GPGPU)功耗更低、性能更强,更适合今天的GenAI应用
……
无论通往罗马的道路有多少条,无论穿越这些道路上有多么艰辛,但,这些旅程早晚都会终结在另外一堵墙之前:英伟达构筑的CUDA!
多么让人沮丧的结局啊!那为何还要开始这段旅程呢?为了回答这个问题,先来看看下面这张图片:
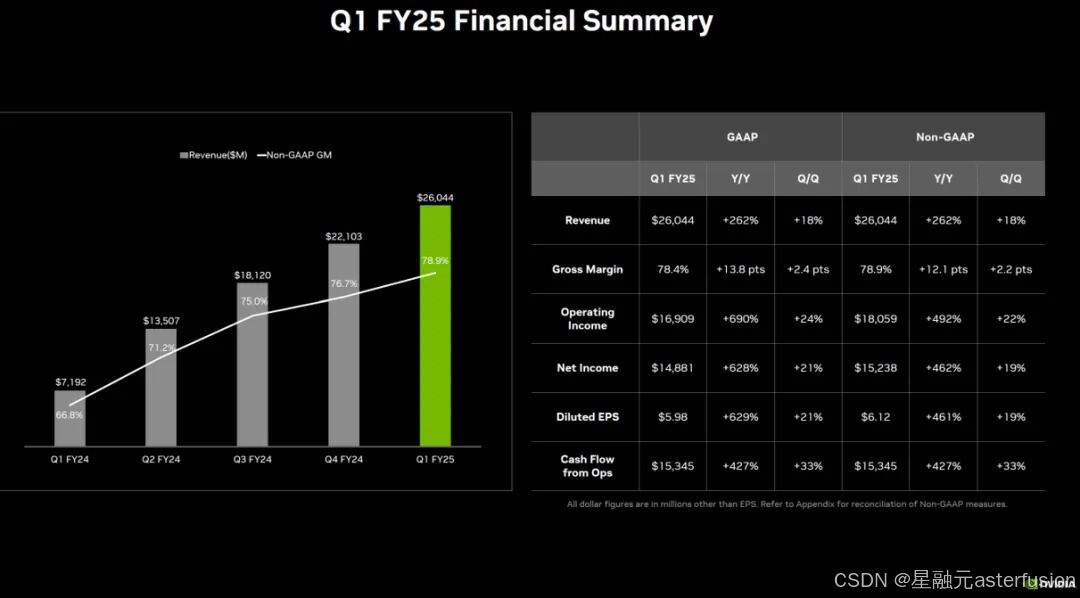
数字最枯燥,但是也最说明问题:2025财年第一财季,英伟达的收入为260.44亿美元,其中,净利润为148.81亿美元,净利率为57.14%(这个净利率数字基本可以让99.99%的做硬件的公司哭死过去好几回)!
看看穿着黑色机车夹克的黄教主在最近几次演讲中痛陈他和历史上的英伟达所经历过的压力、危机、屈辱、挣扎、另辟蹊径、奋起反抗和其他所有的罄竹难书的过往,就会发现——今天,我们如果用“天下苦NVIDIA久矣”这样的话语来引导和宣泄情绪,是多么的不公平、反智商和“盲目仇富”啊!英伟达的3万亿市值、高得难以置信的净利率、干一月等于别人干三年的收入,都是用那些不堪的过往换来的,岂是短短一句情绪宣泄可以对冲掉的!?
说到这里,对于这篇文章所描述的这些人和事,就可以给出结论了:
世上只有一种英雄主义,就是在认清AI和GPU的真(xian)相(zhuang)之后,依然热爱并坚持探索“如何用新的方法搓出新的GPU”,从而为人(gong)类(si)的(de)科(fa)技(zhan)进(zhuan)步(qu)贡(geng)献(duo)力(li)量(run)!
那么,我们最终能够穿越高墙抵达罗马吗?答案是毋庸置疑的:能!破高墙者,唯有开放生态。
历史的发展已经不厌其烦地证明了一件事情:只有开放才能有生命力,才能可持续发展。看看网络设备领域和C记、计算芯片领域和I记、存储领域和E记、公有云领域和A记,哪一个不是如此!?
面对今天雨后春笋般长出来的GPU公司,提问题的正确方式应该是:几年之后,它们会开始让人们追忆N记在GPU领域的辉煌?而不是它们能不能、会不会让人们追忆N记!
说到这里,小编的脑海中突然又浮现出一行字:交换芯片领域和B记……
AI不等于GPU芯片,AI是一个生态,一个从最底层基础设施到最上层各种应用的生态;正如GPU芯片需要多家参与的开放格局,AI生态也需要多家参与的开放共建。
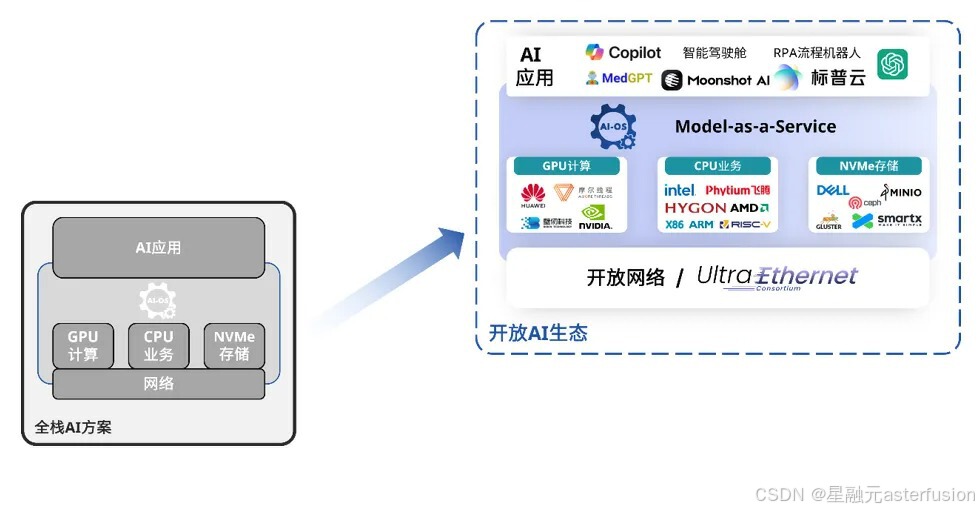 作为国内为数不多深耕于开放网络软硬件产品的科技公司——星融元就是这个开放AI生态的坚定推进者与参与者之一。
作为国内为数不多深耕于开放网络软硬件产品的科技公司——星融元就是这个开放AI生态的坚定推进者与参与者之一。
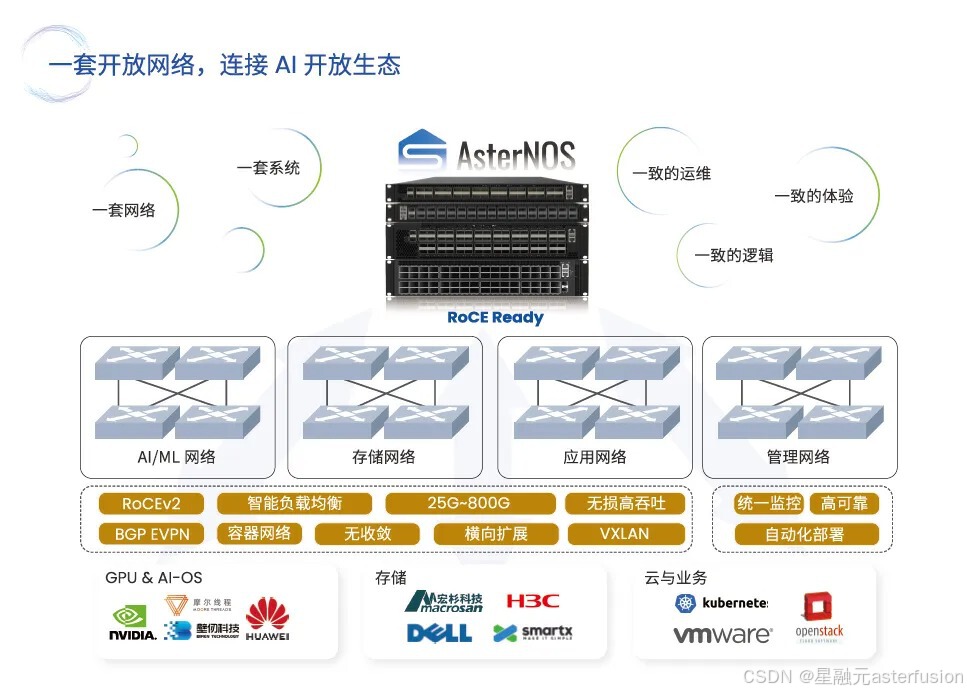
星融元(Asterfusion)是行业领先的开放网络解决方案提供商,多年来专注于为各行业客户提供基于通用、解耦、高性能的硬件和SONiC软件框架的全场景一站式网络解决方案。面向AI时代下的新需求和新挑战,我们仍将积极拥抱开放生态,持续为用户构建中立透明、易于运维、高性价比的基础网络。
关注vx公号“星融元Asterfusion”,获取更多技术分享和最新产品动态。


















 5031
5031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









