




第Y1周:详解YOLO检测算法的训练参数
- 🍨 本文为🔗IT男的一人企业中的学习记录博客
- 🍖 原作者:[IT男的一人企业]
人工智能的技术圈有一项“一招鲜,吃遍天”的免费开源技术。软件外包公司拿着它就可以吃饱喝足。这项技术就是目标检测,用的是YOLO算法。
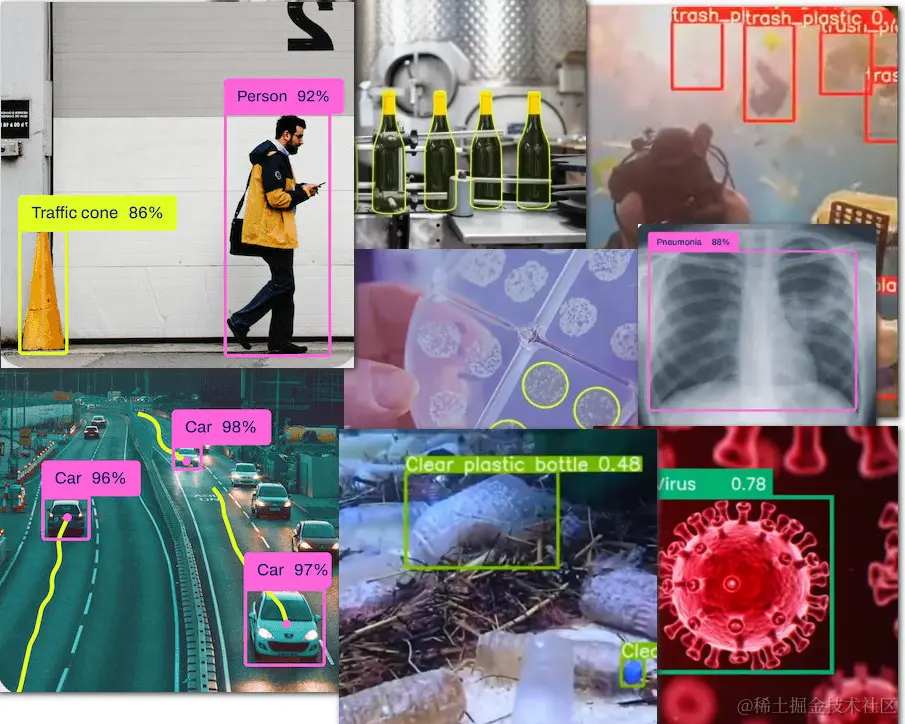
对于外行人,不管是做交通、医疗、环保还是机械行业的,他们往往会认为每一个场景都是一项技术。我接触过一个读者,他说要给我130多个AI项目做。我问都是什么项目?他告诉我,检测道路积水、检测流动摊贩、检测门前脏乱、检测违规撑伞……
我说,停停停!从我看来,这就是一个项目,都是针对某个目标进行检测。我说你有这么多需要检测的场景,咱别一个项目一个项目的走,不如做一个通用的检测平台,一招解决所以问题。

不管是检测路上的杂物,还是检测车船,看着有上百种要识别的场景。其实用到的技术都是目标检测算法。一般是用YOLO算法。
这里面最难的就是获取训练数据。这么多场景,对数据量的要求很大。因为每做一类,都要对数据进行标记。即便是现在大厂做的模型,也仅仅是通用模型,没这么细致。所谓通用就是一些生活中常见的事物,比如人啊,汽车呀。他没有细致到具体车的反光镜,化妆镜,还是后视镜。你想要搞这么细,你得找个几千张图片,然后挨个标记,交给模型去训练,训练完之后他才能进行识别。
举个例子,比方说我们想识别下图中的①和②,得先有训练素材,然后标记成训练集,最后去训练。

有些人确实是这么做了。其实,能迈出这一步的人,已经很不错了。因为多数人都望而却步,说一句:都说AI方便,什么破技术,这么费劲巴拉!
有些先驱们,前期耗费了一些人力物力,搞了一些训练集,但是最终发现还是没有获得好的效果。于是就对检测技术产生了怀疑。
我搜了搜,网上都在讲YOLO平台,还没有人专门讲过它训练参数的配置。如果配置不好参数,无异于高速上挂S档跑长途,很难获得预期的效果。
那么,YOLO进行训练时,它有哪些参数可以设置呢?又会起到什么作用呢?
以YOLOv8举例,我们可以去一个地方查询,那就是安装目录下的
ultralytics\cfg\default.yaml文件。
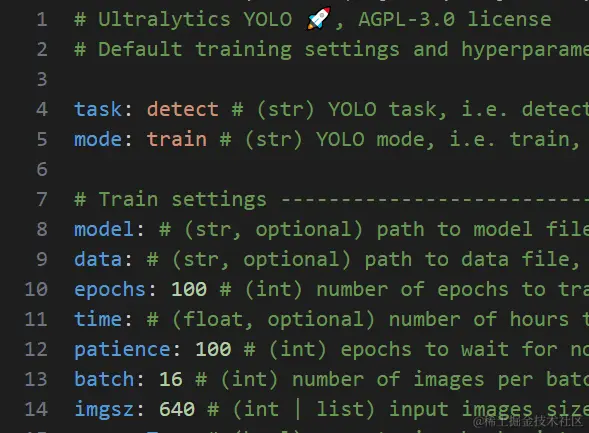
# Ultralytics YOLO 馃殌, AGPL-3.0 license
# 默认的训练设置和超参数,用于中等增强的 COCO 训练
task: detect # (str) YOLO 任务,例如检测、分割、分类、姿态
mode: train # (str) YOLO 模式,例如训练、验证、预测、导出、跟踪、基准测试
# 训练设置 --------------------------------------------------------------------------------
model: # (str, optional)模型文件的路径,例如 yolov8n.pt, yolov8n.yaml
data: # (str, optional) 数据文件的路径,例如 coco128.yaml
epochs: 100 # (int) 训练的周期数
patience: 50 # (int) 如果没有可观察到的改进,则等待周期数以提前停止训练
batch: 16 # (int) 每个批次的图像数(-1 表示自动批次)
imgsz: 640 # (int | list) 训练和验证模式下的输入图像尺寸(整数),或预测和导出模式下的列表[w,h]
save: True # (bool) 保存训练检查点和预测结果
save_period: -1 # (int) 每 x 个周期保存一次检查点(如果小于 1 则禁用)
cache: False # (bool) True/ram, disk 或 False。用于数据加载的缓存
device: # (int | str | list, optional) 运行的设备,例如 cuda device=0 或 device=0,1,2,3 或 device=cpu
workers: 8 # (int) 数据加载的工作线程数(如果是 DDP,则每个 RANK)
project: # (str, optional可选) 项目名称
name: # (str, optional) 实验名称,结果保存到 '项目/名称' 目录
exist_ok: False # (bool) 是否覆盖现有实验
pretrained: True # (bool | str) 是否使用预训练模型(bool)或从哪个模型加载权重(str)
optimizer: auto # (str) 使用的优化器,选项=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto]
verbose 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2475
2475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









