






 本文深入探讨了并发编程中的关键概念和挑战,包括原子性、互斥锁、惊群问题及False-sharing,通过分析Nginx、Memcached、Redis、Linux内核及MyCat等开源软件的并发解决方案,揭示了高性能并发设计的原理。
本文深入探讨了并发编程中的关键概念和挑战,包括原子性、互斥锁、惊群问题及False-sharing,通过分析Nginx、Memcached、Redis、Linux内核及MyCat等开源软件的并发解决方案,揭示了高性能并发设计的原理。
2.4 常见开源软件中的并发问题分析
前一节介绍了 Linux 中相关并发工具,实际场景中有很多应用,下面我们来对几个开源软件的并发设计进行分析。
2.4.1 Nginx 原子性
下面我们通过分析 Nginx 中的原子变量实现,来介绍程序如何能做到保证原子性的。
Nginx 为了保证原子性设计了 atomic 函数,atomic 的代码如下:
static ngx_inline ngx_atomic_uint_t
ngx_atomic_cmp_set(ngx_atomic_t *lock, ngx_atomic_uint_t old,
ngx_atomic_uint_t set)
{
u_char res;
__asm__ volatile (
NGX_SMP_LOCK
” cmpxchgl %3, %1; ”
” sete %0; ”
: “=a” (res) : “m” (*lock), “a” (old), “r” (set) : “cc”, “memory”);
return res;
}
atomic 的工作原理如下:
1)在多核环境下,NGX_SMP_LOCK 其实就是一条 lock 指令,用于锁住总线。
2)cmpxchgl 会保证指令同步执行。
3)sete 根据 cmpxchgl 执行的结果(eflags 中的 zf 标志位)来设置 res 的值。
其中假如 cmpxchgl 执行完之后,时间片轮转,这个时候 eflags 中的值会在堆栈中保持,这是 CPU task 切换机制所保证的。所以,等时间片切换回来再次执行 sete 的时候,也不会导致并发问题。
至于信号量、互斥锁,最终还得依赖原子性的保证,具体锁实现可以有兴趣自己再去阅读源代码。
下面是 ngx_spinlock 的实现,依赖了原子变量的 ngx_atomic_cmp_set:
void
ngx_spinlock(ngx_atomic_t *lock, ngx_atomic_int_t value, ngx_uint_t spin)
{
#if (NGX_HAVE_ATOMIC_OPS)
ngx_uint_t i, n;
for ( ;; ) {
if (*lock == 0 && ngx_atomic_cmp_set(lock, 0, value)) {
return;
}
if (ngx_ncpu > 1) {
for (n = 1; n < spin; n <<= 1) {
for (i = 0; i < n; i++) {
ngx_cpu_pause();
}
if (*lock == 0 && ngx_atomic_cmp_set(lock, 0, value)) {
return;
}
}
}
ngx_sched_yield();
}
#else
#if (NGX_THREADS)
#error ngx_spinlock() or ngx_atomic_cmp_set() are not defined !
#endif
#endif
}
在上面的代码中,Nginx 的 spinlock 主要实现过程如下:
1)进入死循环。
2)假如可以获得锁,则 return。
3)循环 CPU 的个数次来通过 ngx_atomic_cmp_set 获得锁,假如获得了,则 return;否则继续死循环。
2.4.2 Memcached 中的互斥锁
Memcached 也使用了 mutex 这样的互斥锁,来控制对 item 的访问,代码如下:
void *item_trylock(uint32_t hv) {
pthread_mutex_t *lock = &item_locks[hv & hashmask(item_lock_hashpower)];
if (pthread_mutex_trylock(lock) == 0) {
return lock;
}
return NULL;
}
注意
Memcached 的互斥锁粒度比较细,可以看到,针对每个 item,都加了一把锁,这样在并发的时候,可以尽量减少冲突,提高性能。
Memcached 在锁的获得过程中,使用了 pthread_mutex_trylock:
void item_trylock_unlock(void *lock) {
mutex_unlock((pthread_mutex_t *) lock);
}
void item_unlock(uint32_t hv) {
uint8_t *lock_type = pthread_getspecific(item_lock_type_key);
if (likely(*lock_type == ITEM_LOCK_GRANULAR)) {
mutex_unlock(&item_locks[hv & hashmask(item_lock_hashpower)]);
} else {
mutex_unlock(&item_global_lock);
}
}
Memcached 中,锁的释放过程也是同样的道理,首先从 item_locks 数组中找到锁对象。然后通过 mutex_unlock 来解锁。
2.4.3 Redis 无锁解决方案
Redis 的服务器程序采用单进程、单线程的模型来处理客户端的请求。对读写等事件的响应是通过对 epoll 函数的包装来做到的。
图2-13是 Redis 服务器模型原理,整个服务器初始化的过程如下:
1)初始化 asEventLoop。
2)初始化服务器 socket 监听,并且绑定 acceptTcpHandler 事件函数,以应对建立客户端连接的请求。
3)绑定 beforesleep 函数到 eventLoop,并且调用 aeMain 来启动 epoll 主循环。
4)主循环响应客户端要求建立连接的请求。
5)主循环读取客户端命令,并执行。
6)如有数据回写则初始化 writeEvent,将数据提交到 c-replay 队列。主循环需要处理此事件的时候则读取数据写回客户端。
因为 Redis 是单线程的模型,所以,所有的操作都是先来后到串行的,因此,在这个方案中,可以不需要锁,也没有并发的存在,模型假设了所有操作都是基于内存的操作,速度是非常快的。
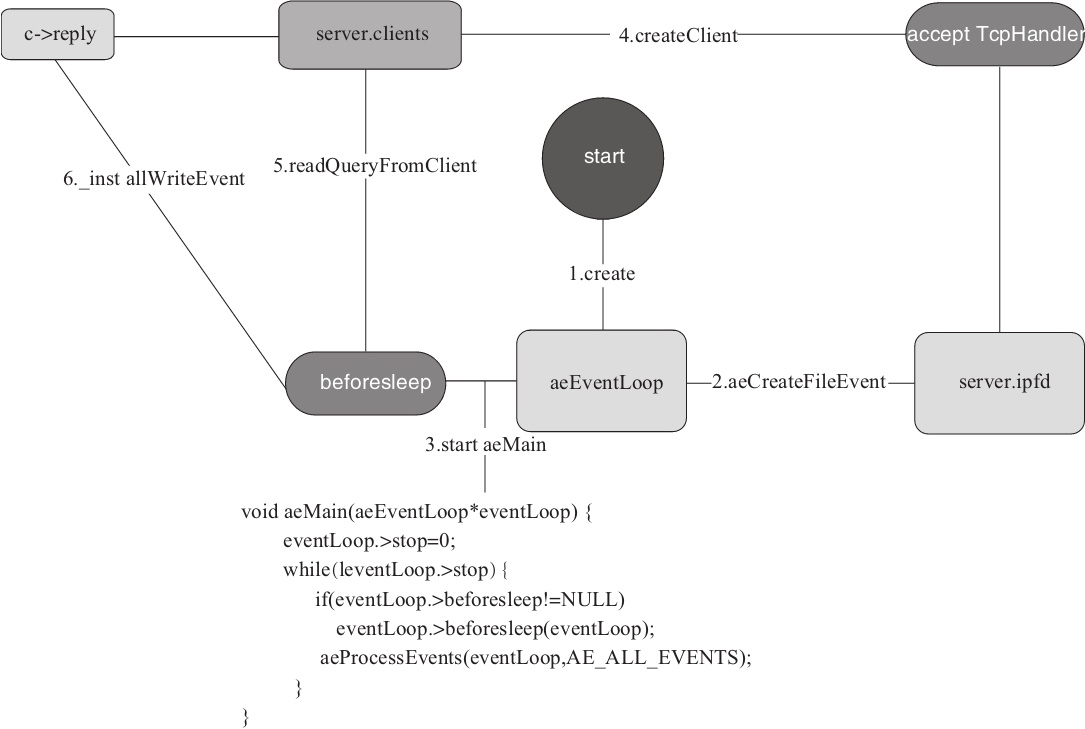
图2-13 Redis 服务器模型
2.4.4 Linux 中惊群问题分析
Linux 中惊群相关的问题鼎鼎有名,但是在网上搜索相关资料,发现都是只言片语,不是说得很完整,本节对这个问题进行系统的总结。
惊群是在多线程或者多进程的场景下,多个线程或者进程在同一条件下睡眠,当唤醒条件发生的时候,会同时唤醒这些睡眠进程或者线程,但是只有一个是可以执行成功的,相当于其他几个进程和线程被唤醒后存在执行开销的浪费。
在 Linux 中,以下场景下会触发惊群:
多个进程或者线程在获取同一把锁的时候睡眠。
多个进程或者线程同时进行 accept。
多个进程在同一个 epoll 上竞争。
多个进程在多个 epoll 上对于同一个监听的 socket 进行 accept。
下面我们分别来举例说明这几个场景,及其解决方案。
1.Linux 中通用的解决方案
Linux 提供了一个 wake_up_process 方法,用于唤醒一个指定的进程,其声明如下:
int wake_up_process(struct task_struct *p)
那么,假如有一堆的进程同时睡眠的时候,我们如何来维护这些睡眠的进程,并且如何只让其中一个被唤醒呢?
Linux 通过工作队列的方式来解决这个问题,在进程睡眠之前,会先进行一个特定的操作:
prepare_to_wait_exclusive(wait_queue_head_t *q, wait_queue_t *wait, int state)
{
unsigned long flags;
wait->flags |= WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q->lock, flags);
if (list_empty(&wait->task_list))
__add_wait_queue_tail(q, wait);
set_current_state(state);
spin_unlock_irqrestore(&q->lock, flags);
}
以上 prepare_to_wait_exclusive 函数主要是将当前的 flags 加上了 WQ_FLAG_EXCLU-SIVE 的标志,然后放入到工作队列的尾部,最后设置相应的状态,例如 TASK_INTERR-UPTIBLE 表示可以被 wake_up 唤醒。
当我们需要进行唤醒的时候,Linux 提供了_wake_up_common 方法,来唤醒工作队列中的进程:
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
unsigned flags = curr->flags;
if (curr->func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
上面的 _wake_up_common 方法会遍历工作队列,寻找 flags 中含有 WQ_FLAG_EXCLUSIVE 标志的进程,当 nr_exclusive 减为0的时候,就会跳出循环,所以只能唤醒 nr_exclusive 个进程,比如 nr_exclusive=1。
其中 curr->func 的回调函数是通过 DEFINE_WAIT(wait)宏来定义的:
#define DEFINE_WAIT_FUNC(name, function)
wait_queue_t name = {
.private = current,
.func = function,
.task_list = LIST_HEAD_INIT((name).task_list),
}
#define DEFINE_WAIT(name) DEFINE_WAIT_FUNC(name, autoremove_wake_function)
通过上面的代码可以发现回调函数为 autoremove_wake_function:
int autoremove_wake_function(wait_queue_t *wait, unsigned mode, int sync, void
*key)
{
int ret = default_wake_function(wait, mode, sync, key);
if (ret)
list_del_init(&wait->task_list);
return ret;
}
int default_wake_function(wait_queue_t *curr, unsigned mode, int wake_flags,
void *key)
{
return try_to_wake_up(curr->private, mode, wake_flags);
}
autoremove_wake_function 最终通过 default_wake_function 调用 try_to_wake_up 来实现唤醒指定的进程。整个流程见图2-14。
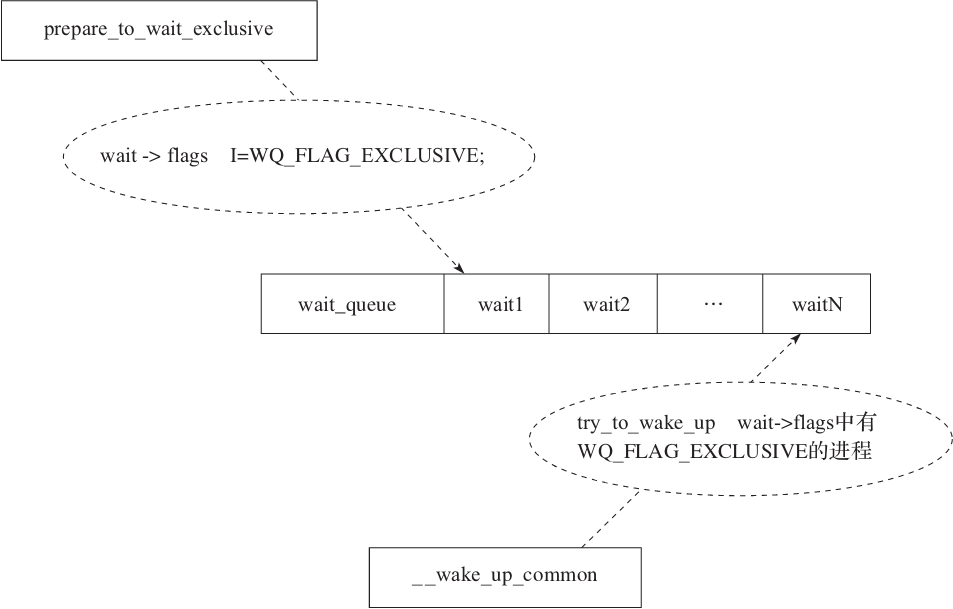
图2-14 Linux 进程唤醒流程
2.socket accept 场景下的惊群及解决方案
在 Linux 中,针对服务器监听的 socket 进行 accept 操作,假如没有新的 accept 事件,那么会进行睡眠。sys_accept 调用最终会在 TCP 层执行 inet_csk_accept 函数:
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct request_sock_queue *queue = &icsk->icsk_accept_queue;
struct request_sock *req;
struct sock *newsk;
int error;
lock_sock(sk);
...
// 阻塞等待,直到有全连接建立。如果用户设置了等待超时时间,超时后会退出
error = inet_csk_wait_for_connect(sk, timeo);
...
out:
release_sock(sk);
...
inet_csk_accept 在等待 accept 连接到来的时候,会执行 inet_csk_wait_for_connect:
static int inet_csk_wait_for_connect(struct sock *sk, long timeo)
{
struct inet_connection_sock *icsk = inet_csk(sk);
DEFINE_WAIT(wait);
...
for (;;) {
prepare_to_wait_exclusive(sk_sleep(sk), &wait,
TASK_INTERRUPTIBLE);
...
if (reqsk_queue_empty(&icsk->icsk_accept_queue))
timeo = schedule_timeout(timeo);
...
}
...
}
上面的过程看着眼熟吗,prepare_to_wait_exclusive 的作用在上一个例子已经介绍过了,这里会把当前的进程通过 DEFINE_WAIT(wait)包装成 wait_queue_t 结构,并且放入到监听 socket 的等待队列尾部。然后通过 schedule_timeout 让当前进程睡眠 timeo 个时间。
该进程被唤醒有几种可能:
睡眠 timeo 后被 timer 定时器唤醒。
accept 事件到来被唤醒。
第2种被唤醒的场景是由网络层的代码触发的。以 TCP V4 协议为例,其执行过程为:tcp_v4_rcv->tcp_v4_do_rcv->tcp_child_process,在 tcp_child_process 方法中会调用父 socket,也就是监听 socket 的 parent->sk_data_ready(parent)方法,在 sock_init_data 的时候,我们发现,该函数的定义如下:
sk->sk_data_ready = sock_def_readable;
sock_def_readable 函数实现为:
static void sock_def_readable(struct sock *sk)
{
struct socket_wq *wq;
rcu_read_lock();
wq = rcu_dereference(sk->sk_wq);
if (skwq_has_sleeper(wq))
wake_up_interruptible_sync_poll(&wq->wait, POLLIN | POLLPRI |
POLLRDNORM | POLLRDBAND);
sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN);
rcu_read_unlock();
}
sock_def_readable 首先判断是否在等待队列中有睡眠的进程,然后通过 wake_up_interruptible_sync_poll 进行唤醒。其实现如下:
#define wake_up_interruptible_sync_poll(x, m)
__wake_up_sync_key((x), TASK_INTERRUPTIBLE, 1, (void *) (m))
void __wake_up_sync_key(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, void *key)
{
unsigned long flags;
int wake_flags = 1;
if (unlikely(!q))
return;
if (unlikely(nr_exclusive != 1))
wake_flags = 0;
spin_lock_irqsave(&q->lock, flags);
__wake_up_common(q, mode, nr_exclusive, wake_flags, key);
spin_unlock_irqrestore(&q->lock, flags);
}
最终发现是由 _wake_up_common 来唤醒的,和前面介绍的是一样的,并且 nr_exclusive 为1。说明只会唤醒一个,不会发生惊群。
那么,在 inet_csk_accept 的时候,lock_sock(sk)操作为什么不能避免惊群呢?理论上锁住了监听的 socket,每次只有一个进程可以 accept 了呀。事实上,lock_sock(sk)的时候,要是拿不到锁,也会进行睡眠,假如不做特殊处理,也有可能惊群,lock_sock 最终调用 _lock_sock:
static void __lock_sock(struct sock *sk)
__releases(&sk->sk_lock.slock)
__acquires(&sk->sk_lock.slock)
{
DEFINE_WAIT(wait);
for (;;) {
prepare_to_wait_exclusive(&sk->sk_lock.wq, &wait,
TASK_UNINTERRUPTIBLE);
spin_unlock_bh(&sk->sk_lock.slock);
schedule();
spin_lock_bh(&sk->sk_lock.slock);
if (!sock_owned_by_user(sk))
break;
}
finish_wait(&sk->sk_lock.wq, &wait);
}
当无法获得上锁条件进行 schedule 放弃 CPU 之前,会先进行 prepare_to_wait_exclusive,这个动作前面已经解释得很清楚了。所以,假如同时有多个进程在 lock_sock 阻塞的时候,也仅会被唤醒一个。
最后,图2-15描述了 accept 的整体流程图。
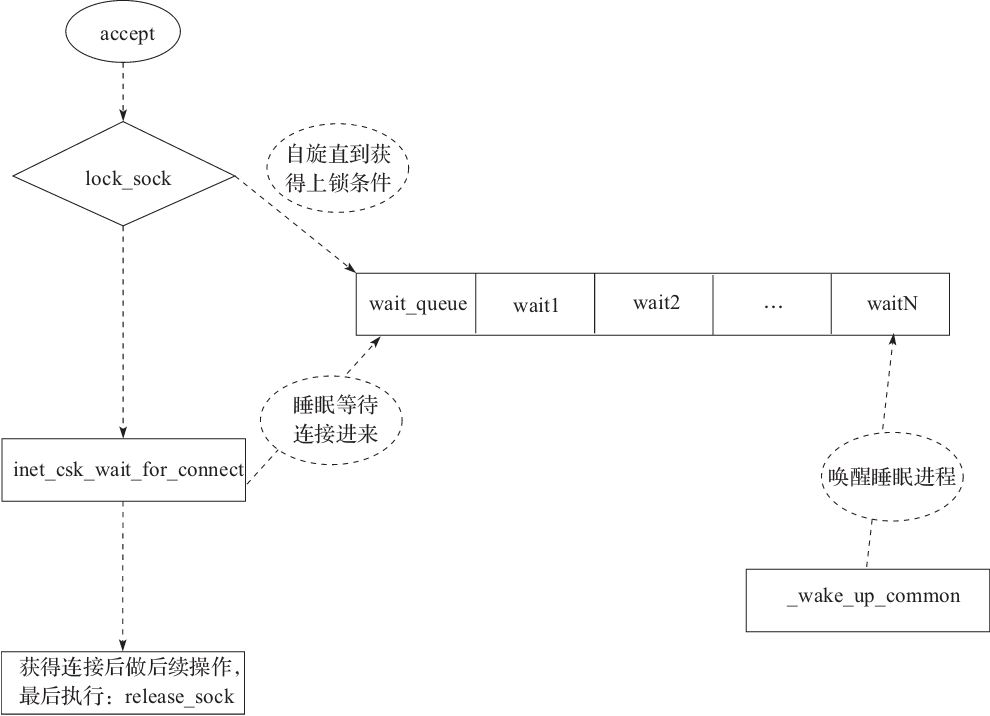
图2-15 Linux accept 的流程
3.epoll 的惊群解决方案
在使用 epoll 的时候,我们会在注册事件后调用 epoll_wait,该系统调用会调用 ep_poll 方法:
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
...
// 没有事件,所以需要睡眠。当有事件到来时,睡眠会被 ep_poll_callback 函数唤醒
// 将 current 初始化为等待队列项 wait 后,放入 ep→wg 这个等待队列中
init_waitqueue_entry(&wait, current);
__add_wait_queue_exclusive(&ep->wq, &wait);
for (;;) {
// 执行 ep_poll_callback()唤醒时应当将当前进程唤醒,所以当前进程状态应该为“可唤醒”
TASK_INTERRUPTIBLE
set_current_state(TASK_INTERRUPTIBLE)
// 如果就绪队列不为空(已经有文件的状态就绪)或者超时,则退出循环
if (ep_events_available(ep) || timed_out)
break;
// 如果当前进程接收到信号,则退出循环,返回 EINTR 错误
if (signal_pending(current)) {
res = -EINTR;
break;
}
spin_unlock_irqrestore(&ep->lock, flags);
// 放弃 CPU 休眠一段时间
if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS))
timed_out = 1;
spin_lock_irqsave(&ep->lock, flags);
}
__remove_wait_queue(&ep->wq, &wait);
__set_current_state(TASK_RUNNING);
}
...
我们发现,假如没有事件,需要睡眠,通过 _add_wait_queue_exclusive 将当前进程放入等待队列的队头中,其实现如下:
static inline void
__add_wait_queue_exclusive(wait_queue_head_t *q, wait_queue_t *wait)
{
wait->flags |= WQ_FLAG_EXCLUSIVE;
__add_wait_queue(q, wait);
}
其中 WQ_FLAG_EXCLUSIVE 用于赋给 flgas,表示该睡眠进程是一个互斥进程。
睡眠的当前进程会被回调函数 ep_poll_callback 唤醒,其实现如下:
static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void
*key)
{
...
wake_up_locked(&ep->wq);
...
}
#define wake_up_locked(x) __wake_up_locked((x), TASK_NORMAL, 1)
void __wake_up_locked(wait_queue_head_t *q, unsigned int mode, int nr)
{
__wake_up_common(q, mode, nr, 0, NULL);
}
ep_poll_callback 最终通过 _wake_up_common 函数来唤醒等待队列中的互斥进程。
4.Nginx 为什么还有惊群问题
我们分析一下 Nginx 为什么还会有惊群问题呢?Nginx 不是已经使用了 epoll 了吗?epoll 上面又已经解决了,为什么还会有这个问题呢?原因是 Nginx 的 master 在 fork 出多个 worker 进程后,worker 进程才创建出多个 epoll,所以多个进程假如同时进行 epoll_wait,还是有可能会发生惊群问题,因为每个 worker 都维护了一个进程。
worker 在循环中,会执行 ngx_process_events_and_timers,我们来看它的实现:
void
ngx_process_events_and_timers(ngx_cycle_t *cycle)
{
...
if (ngx_use_accept_mutex) {
if (ngx_accept_disabled > 0) {
ngx_accept_disabled--;
} else {
if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) {
return;
}
if (ngx_accept_mutex_held) {
flags |= NGX_POST_EVENTS;
} else {
if (timer == NGX_TIMER_INFINITE
|| timer > ngx_accept_mutex_delay)
{
timer = ngx_accept_mutex_delay;
}
}
}
}
...
上面的代码解释如下:假如 ngx_accept_disabled>0,表示现在该 woker 已经压力很大了,所以不再接受新的处理。否则,会先尝试获取互斥锁,ngx_trylock_accept_mutex。
至于 ngx_accept_disabled 的大小设定,在每次 accept 事件处理完之后,进行相应的设置:
void
ngx_event_accept(ngx_event_t *ev)
{
...
ngx_accept_disabled = ngx_cycle->connection_n / 8
\- ngx_cycle->free_connection_n;
...
}
上面这个值的意思为最大连接数的八分之一减去空闲连接的数量。大于0说明空闲连接的数量都已经少于八分之一了。
通过上面代码可以发现,不管是 woker 的负载平衡,还是惊群问题的解决,都需要满足 ngx_use_accept_mutex 条件,可以通过修改配置解决,如下所示:
events {
accept_mutex on;
}
因为 Nginx 的 worker 数量本来就有限,与 CPU 核数相当,所以,打开该锁意义不是很大,另外在高并发场景下,因为惊群锁的存在,吞吐量反而会下降,Nginx 在最新版本里也默认是关闭该锁的。
只有针对 Apache 这种多线程模型,而且会 fork 出成百上千个线程的,这个问题才会严重。我们来看 Nginx 作者的说法:“操作系统有可能会唤醒等待在 accept()和 select()调用阻塞的所有进程,这会引发惊群问题。在有很多 worker 的 Apache(数百个或者更多)中会引发这个问题,但是假如你使用仅仅只有数个(通常为 CPU 核数)worker 的 Nginx,就不会引发这个问题。因此在 Nginx 中,你在使用 select/kqueue/epoll 等(除了 accept())来调度进入的连接,可以关闭 accept_mutex。”
2.4.5 解决 MyCat 同步问题
MyCat 是用 Java 开发的开源数据库中间件,其服务器采用的是 reactor 模型(关于 I/O 模型,我们在 I/O 的章节中会具体介绍)。图2-16是我整理的 MyCat 的服务器中心领域模型。
这是一个典型的 Reactor 模型,NIOReactorPool 会预先分配 N 个 Reactor 工作线程,并且每个 Reactor 会维护一个 selector,当事件就绪后,Reactor 就会执行相关事件的回调函数。
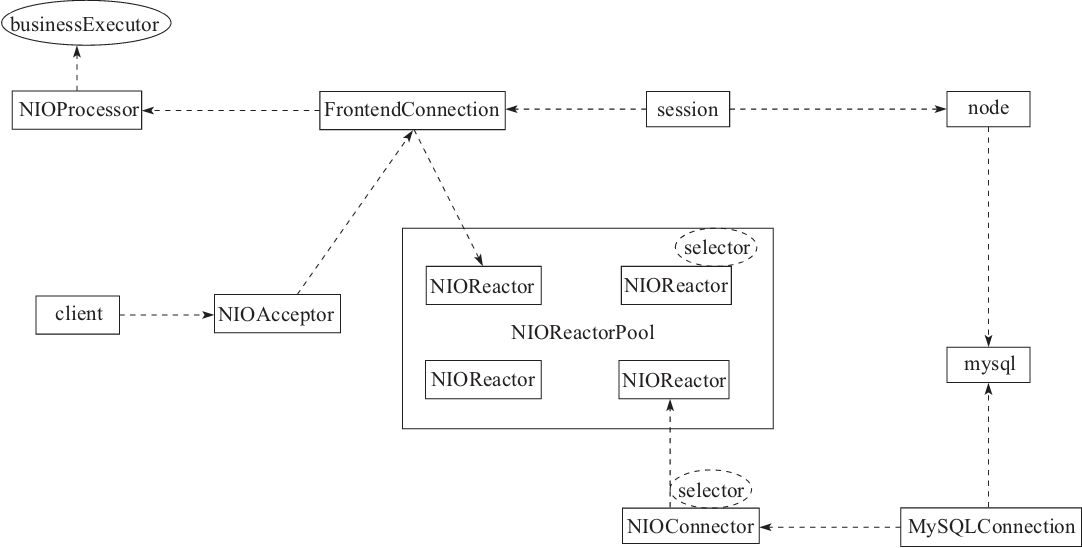
图2-16 MyCat 服务器领域模型
基于这个思路 MyCat 中所有的 I/O 操作都是异步操作,但是我自定义的 handler 有个同步的过程,没办法,业务就是这么依赖了第三方。我只能这样编写代码:
final CountDownLatch Latch=New CountDownLatch(1);
Ctx.executeNaiveSQLSequnceJob(dataNodes,sql,new SQLJobHandler(){private
List<byte[]>fields;
@Override
public boolean onRowData(String dataNode,byte[]rowData){String c1=ResultSe
tUtil,getColumnValAsString(rowData,fields,θ);
String c2=ResultSetUtil,getColumnVaLasString(riwData,fields,1);
share.seDataNode(c1);
share.setIndex(c2);
cacheLock.writeLock().lock();
try{
cache.put(bid,share);
latch.countDown();
retrurn false;
}finally{
cacheLock.writeLock().unlock();
}
}
@Override
public void onHeader(String dataNode,byte[]header,List<byte[]>fields)
this.fields=fields;
}
@Override
public void finished(String dataNode,boolean failde){latch.countDown();
}
});
try{
latch.await(5,TimeUnit.SECONDS);
}catch(InterruptedException e){
然后在实际测试过程中,发现偶然会出现线程卡死现象,我们回顾图2-16就发现了问题。因为 MyCat 的客户端连接(FrontedConnection)和后端 MySQL 的连接共用一个 Reactor 的池子,所以有可能会发生前端和后端同时被分配同一个 Reactor,那么要是前端没退出,后端必然没法执行,然后互相等待造成死锁。
为了解决我的问题,我给前端单独分配了个池子,如下所示:
LUCGER.into(using nio network nanater);
NIOReactorPool reactorPool=new NIOReactorPool(BufferPool.LOCAL_BUF_THREAD_
PREX+"NIOREACTOR",
processors.length);
NIOReactorPool clientReactorPool=new NIOReactorPool(BufferPool.LOCAL_BUF_
THREAD_PREX+" CLIENT_NIOREACTOR,"processors.length);
connector=new NIO Connector(BufferPool.LOCAL_BUF_THREAD_PREX+"NIO Connector",
reactorPool);
((NIOConnector)connector).start();
manager=new NIOAcceptor(BufferPool.LOCAL_BUF_THREAD_PREX+NAME+"Manager",system.
getBindIp(),system.getManagerPort(),mf,reactorPool);
server=new NIOAcceptor(BufferPoo.LOCAL_BUF_THREAD_PREX+NAME+"Sever",syetem.
getBindIp(),system.getServerPort(),sf,clientReactorPool);
2.4.6 false-sharing 问题解决方案
CPU 能从本地缓存中取数据就不会从内存中取,而内存中的数据和缓存中的数据一般都是按行读取的,也就是所谓的缓存行,一般为64个字节,当我们操作数据的时候,假如刚好多个变量在同一个缓存行的时候,多线程同时操作就会让之前的缓存行失效,导致程序效率降低。如图2-17所示,两个变量共享了同一个缓存行,从 L1~L3cache,只要当 X 更新时,Y 也就被踢出了缓存,反之亦然,重新从内存载入数据。
为解决该问题,很多时候只能通过以空间换时间来搞定,比如在 X 和 Y 中间添加一个不使用的变量,仅仅用来占据空间,隔开缓存行那么就会把 X 和 Y 分割为2个缓存行,各自更新,相互不受影响,就是浪费空间而已。
下面我们来看两个具体例子。
1.Jetty 中的解决方案
Jetty 在实现 BlockingArrayQueue 的时候,会加上以下代码:
private long _space0;
private long _space1;
private long _space2;
private long _space3;
private long _space4;
private long _space5;
private long _space6;
private long _space7;
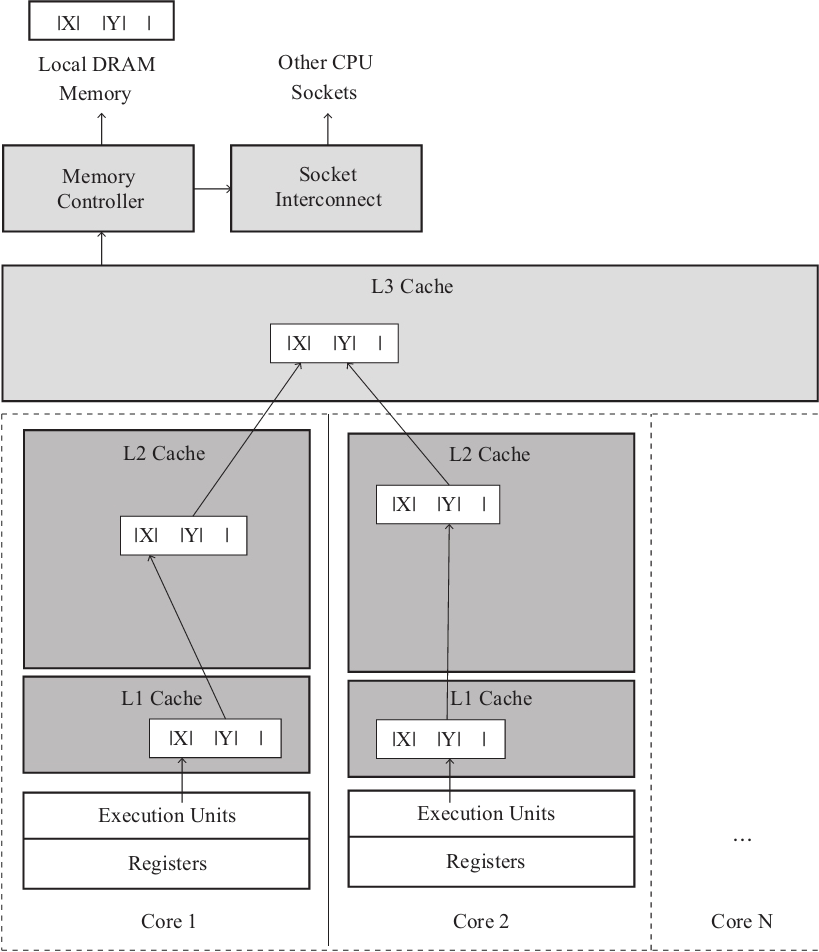
图2-17 False-sharing 问题
2.Nginx 的解决方案
在 C 程序中,Nginx 也有类似的实现:
typedef union
{
erts_smp_rwmtx_t rwmtx;
byte cache_line_align_[ERTS_ALC_CACHE_LINE_ALIGN_SIZE(sizeof(erts_smp_
rwmtx_t))];
}erts_meta_main_tab_lock_t;
erts_meta_main_tab_lock_t main_tab_lock[16]
在下一章介绍内存 slab 分配器的时候(3.5.2节),着色也是用来解决 false sharing 的问题。
2.5 本章小结
并发一直是计算机工程领域的一个重要话题,有很多书籍和文章,甚至有很多论文专门对此进行过探讨。很多初学者觉得并发很难懂,很麻烦。其实所有的问题归根结底都是由简单的道理组成的,我认为,脱离计算机的底层原理来谈并发都是水中月,镜中花,尤其对初学者来说,会陷入在一堆并发编程的 API 中难以自拔。
本章开篇就阐述了到底什么是并发,并发会引发的问题,这样便于后续更加深入理解并发相关处理。对于应用程序员来讲,不管你是用 C 或是 Java,甚至是 Go 语言,我们面临的并发问题,操作系统同样面临类似的问题。所以,只有在理解了操作系统的并发场景后,我们才会理解 Linux 内核的并发工具:atomicspin_lock、semaphore、mutex、读写锁、per-cpu、抢占、内存屏障、RCU 机制等。
最后,分析了常见开源软件遇到的一些并发解决方案:Nginx 的原子性、Memcached 的互斥锁、Linux 中惊群问题分析、解决 Mycat 中的同步问题、伪共享问题解决方案等,将这些应用与 Linux 内核的相关实现对照,就能做到融会贯通。

















 208
208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









