




 本文深入探讨Zebra路由更新的四个关键步骤:通知订阅者、检查下一跳活性、处理BGP路由及向内核下发FIB表项。通过详细分析,揭示了路由更新背后的复杂流程,包括hook调用、nexthop活性验证、MPLS转发表更新及FIB表项的内核下发机制。
本文深入探讨Zebra路由更新的四个关键步骤:通知订阅者、检查下一跳活性、处理BGP路由及向内核下发FIB表项。通过详细分析,揭示了路由更新背后的复杂流程,包括hook调用、nexthop活性验证、MPLS转发表更新及FIB表项的内核下发机制。
前面可知,消息被enqueue了mq的work queue,当zebra的mq的work queue被调度的时候,meta_queue_process回调函数会被执行,for循环执行一个就退出,是为了实现subq的绝对优先级调度。

process_subq 取出头结点的存放的struct route_node,然后直接调用rib_process继续处理route_node,其核心思想是遍历route_node的所有的route_entry根据规则选择最优的路由,然后使用这个最优的路由继续处理,rib_choose_best的原则在函数里面也说的很清楚。


本次我们以添加rib为例来分析,rib_process_add_fib主要完成4个事情,下面我们一个一个分析:

第一件事情:
hook_call,通知关心rib_update的订阅者hook_call(rib_update, rn, "new route selected");
#define hook_call(hookname, ...) hook_call_##hookname(__VA_ARGS__)
宏展开后就是调用hook_call_ rib_update(rn, "new route selected")
而hook_call_ rib_update函数是在DEFINE_HOOK定义的,就是调用关心rib_update这个HOOK点的订阅者,rib_update定义如下:


而rib_update订阅者的注册如下,目前有fpm, hook_register调用_hook_register函数:
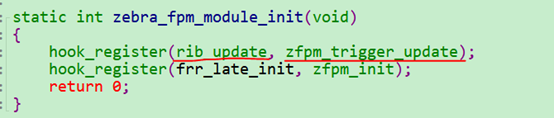

所以hook_call(rib_update, rn, "new route selected")调用的是zfpm_trigger_update函数。
第二件事情:检查nexthop的active
其主要完成遍历re的所有的nexthop,然后调用nexthop_active_check/ nexthop_active检查nexthop是否是active,根据nexthop填充prefix查找路由表,查看下一跳是否在路由表里面,如果是CONNECT路由,那么解析active成功,如果下一跳不是CONNECT的路由,同时还要处理路由递归的情况,把递归的路由存放在struct nexthop的resolved里面,此时的resolved里面存放的路由肯定是前面已经检查并active的路由,所以不并在递归继续查找了。 。


第三件事情:
如果re是BGP的labeled unicast产生的,那么我们需要向内核下发LSP,MPLS的转发表,具体的下发过程,我们后面分析MPLS的时候,在继续分析

第四件事情:向内核下发FIB表项
调用rib_install_kernel函数处理,直接调用dplane_route_add,入队数据平面的队列。
根据前面的初始化分析,我们知道:
zebra_dplane_init_internal初始化了kernel的数据平面的回调函数kernel_dplane_process_func

dplane_route_add调用dplane_route_enqueue把FIB消息入队,并添加事件唤醒dplan 线程


zebra_dplane_start创建了zebra dplane的线程, 线程的事件回调函数dplane_thread_loop,在这个函数里面会出队所有的消息,并调用注册的数据面的回调函数,本次路由的回调函数是kernel_dplane_process_func,然后调用kernel_route_update,继续调用netlink_route_multipath,构造路由的netlink消息,下发给内核,下发的路由会设置NEXTHOP_FLAG_FIB。
同时调用netlink_parse_info处理内核的处理结果

我们把上面的分析的函数主要路径总结如下,细节只有慢慢去看:


















 2353
2353





 到【灌水乐园】发言
到【灌水乐园】发言







