




Title:Learning Correlation Structures for Vision Transformers
Paper:Learning Correlation Structures for Vision Transformers
Code:Learning Correlation Structures for Vision Transformers (kimmanjin.github.io)
导读
本文提出一种新的注意力机制,称为结构自注意力(StructSA),并提出StructViT:结构视觉Transformer,StructVit可以有效提取图像中的结构化信息,在图像和视频分类任务上性能表现SOTA!

动机
让我们回到最熟悉的自注意力公式:
可以看到标准的自注意力计算仅关注其计算结果,而忽略了其中间过程产生的丰富的结构信息。
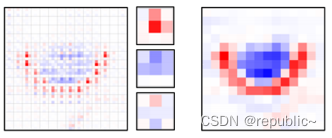
这部分信息集中在公式 的部分。比如取图(a)中标红的部分作为q,那么经过
计算后,我们会得到一个如图(b)的特征图,图(b)也被称为Q-K关联矩阵,可以看到其中包含了丰富的结构信息。
而本文的目标就是利用b图中丰富的结构化特征信息,从而使得Vit具有更好的提取结构特征的能力。
方法
StructuralQuery-KeyAttention(SQKA)
为了将普通的查询键注意转换为结构感知的注意,结构化查询键注意(SQKA)在查询键相关上部署卷积:
值得一提的是,这里的卷积
具有多个维度,因此可以学习到多种的结构信息,这也在后续的实验中也被很好的证明。
Contextual Value Aggregation
在以结合卷积的方式计算完成后,按照常规自注意力的操作,就应该把它与Value值相乘累加起来。
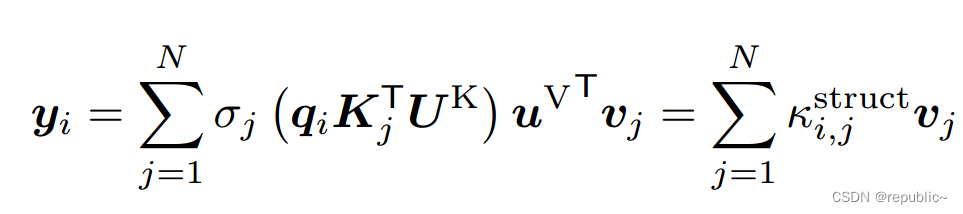
其中
是为了将刚刚多维度卷积生成的多个特征图重新投影降维,以便与Value值计算。
为了更好的实现上下文聚合,公式为进一步改进,可以被替换为
,即
周围的一块Value值,并且通过一个空间块将
投影到
的大小,从而实现Value的上下文聚合。最终的公式如下所示:
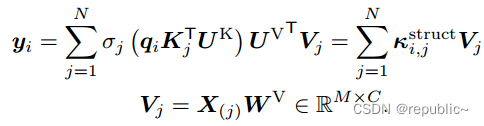
与其他卷积结构Vit的对比
也有很多Vit引入了卷积结构这些卷积多被用于投影上
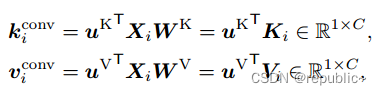
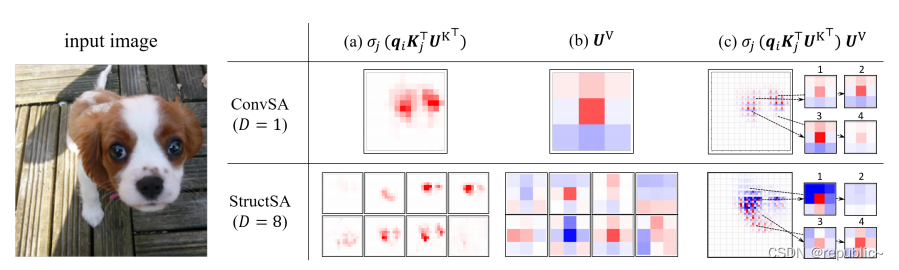
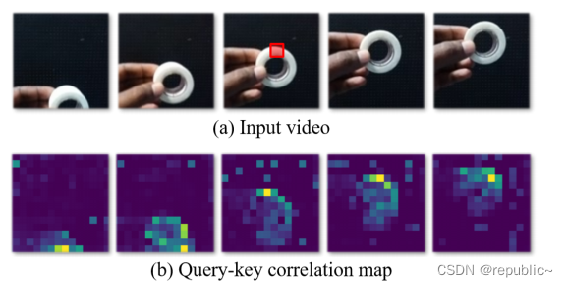
作者通过可视化实验证明了StructSA能提取到更多的信息。
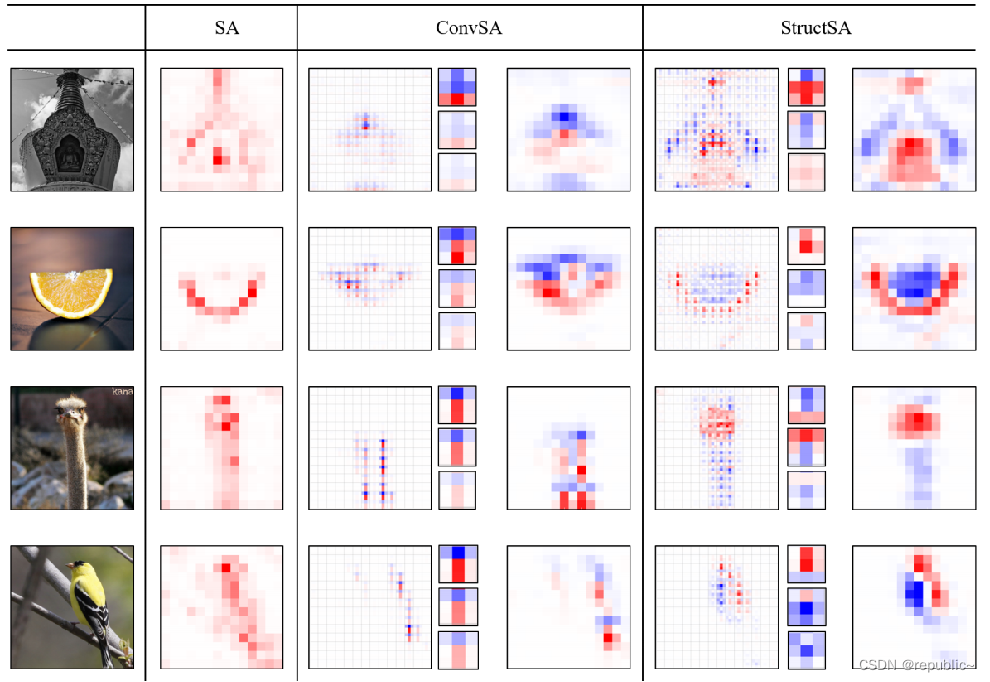
最明显的是图2的柠檬,可以看到某些卷积学习到了果肉的结构信息,某些卷积学习到了果皮的信息,这证明了SructSA的有效性,并且也为Vision Transformer提供了很好的可解释性
实验
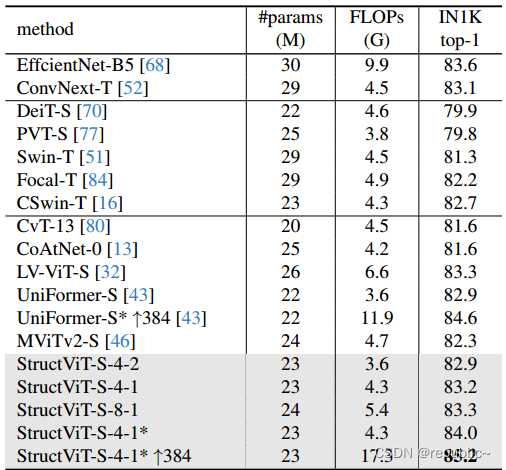
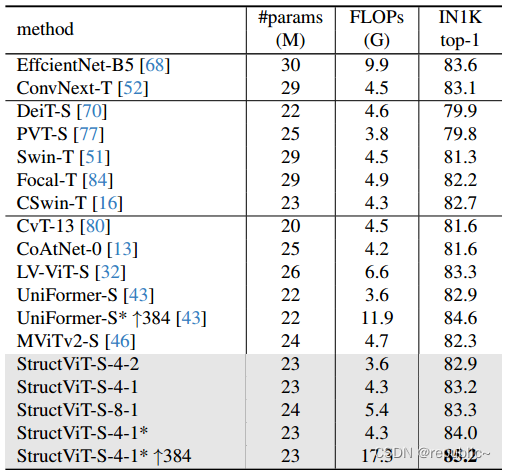
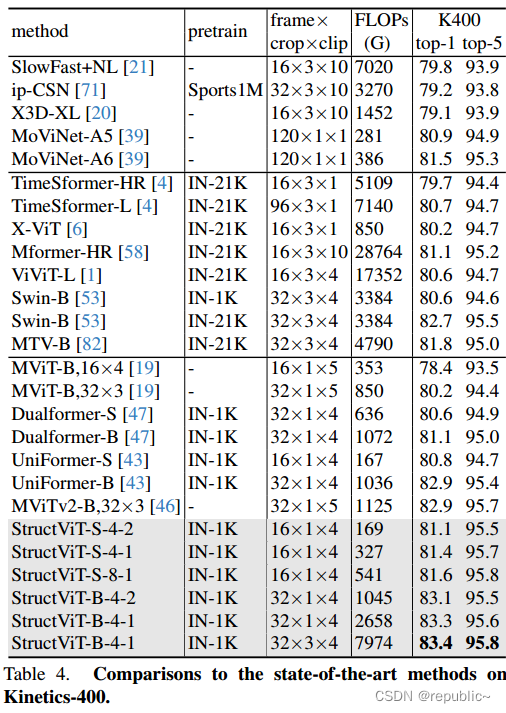
本文在图像和视频数据集(ImageNet-1K, Kinetics-400, Something-Something V1 & V2, Diving-48, FineGym)的分类任务上进行了广泛的实验,证明了StructVit的有效性。
总结
本文引入了一种新的自注意机制,StructSA,它利用查询键相关的丰富结构模式进行视觉表征学习。StructSA利用局部关联的空间(和时间)结构,并在整个位置上聚合局部特征块。结构视觉转换器(StructViT)使用StructSA作为主要注意力模块,在图像和视频分类基准上实现了最先进的结果。
写在最后
希望看完的小伙伴多多点赞,收藏,关注,我会持续分享深度学习领域最新的论文!

















 316
316



 到【灌水乐园】发言
到【灌水乐园】发言








