



背景
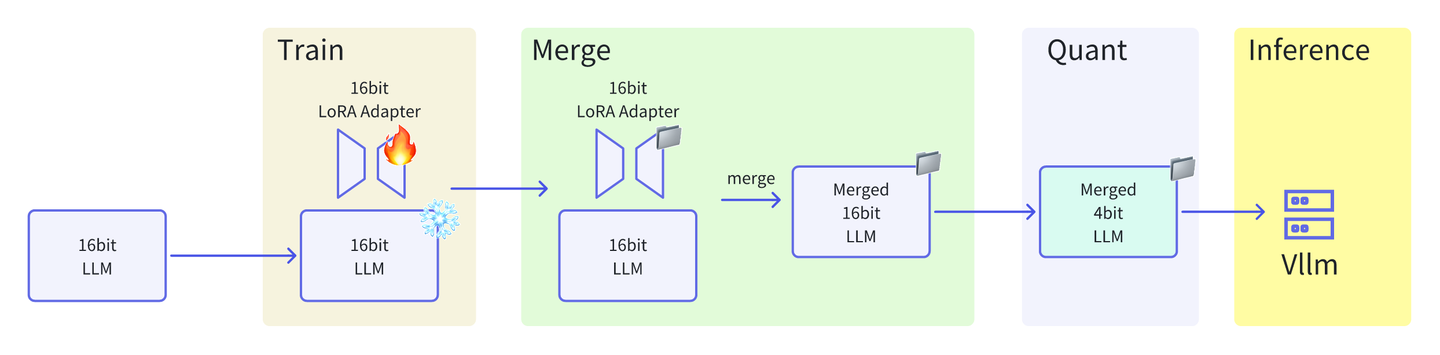
在某领域任务中,使用自有数据集通过 LoRA 方式训练了一个 LoRA adapter 模型。在推理阶段,常规做法是读入一个量化模型,并使用 PeftModel.from_pretrained() 读取 16 位的 adapter 以挂载该 adapter。不过,这种方法的推理速度较慢。
为了兼顾推理速度与质量,需要对模型和 adapter 进行 16 位合并以及 GPTQ 量化,本文以Qwen 2.5-vl为例,实现一个合并与量化过程。 适用场景:推理机显存有限,且希望保证推理速度和推理质量均衡。
以Qwen 2.5 VL为例,我们采用transformer读取以及合并模型,ms-swift进行GPTQ量化,vllm进行推理。
安装依赖
# 克隆 ms-swift 项目仓库到本地
git clone https://github.com/modelscope/ms-swift.git
# 进入 ms-swift 目录
cd ms-swift
# 安装 ms-swift 及其相关的语言模型(llm)依赖,-e 选项允许对安装的包进行可编辑安装,方便开发过程中的修改和调试
pip install -e.[llm] -q
pip install --upgrade transformers -q
pip install -U auto_gptq optimum -q
pip install -U bitsandbytes -q
pip install -U peft -q
pip install trl -q
pip install qwen_vl_utils -q
pip install vllm -q训练
本文不再赘述,可参考https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen2_VL_(7B)-Vision.ipynb![]() https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen2_VL_(7B)-Vision.ipynb等。训练后需要保留adapter模型,也可以在训练后直接使用save_pretrained_merged保存合并后模型,跳过加载与合并步骤。
https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen2_VL_(7B)-Vision.ipynb等。训练后需要保留adapter模型,也可以在训练后直接使用save_pretrained_merged保存合并后模型,跳过加载与合并步骤。
注意训练时不要量化base model(QLoRA)。原因在于:
-
训练阶段用QLoRA,推理阶段也要用QLoRA。但QLoRA因为base model和adapter精度不同,合并会报错,不能用本文方法后续量化。如果希望合并后高效部署,请用LoRA重新训练;
-
训练阶段用LoRA,推理阶段也要用LoRA,本文适用LoRA的情况。
⚠️ 把LoRA adapter挂载到量化后的base model上,或QLoRA的权重加载到16bit精度的base model上,会导致困惑度(ppl,越低越好)增高。https://medium.com/@bnjmn_marie/lora-load-and-merge-your-adapters-with-care-3204119f0426
加载与合并
在已有adapter文件的基础上,需要加载模型并合并。这一步可以将模型地址CKPT_PATH改成自己的基座模型地址,lora_path是LoRA adapter的保存地址。
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training, PeftModel
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
Qwen2_5_VLForConditionalGeneration,
AutoProcessor,
)
import torch
compute_dtype = getattr(torch, "float16")
lora_path = 'YOUR PATH'
CKPT_PATH='Qwen/Qwen2.5-VL-7B-Instruct'
tokenizer = AutoProcessor.from_pretrained(CKPT_PATH,
trust_remote_code=True,
use_fast=True)
# use cuda device
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(CKPT_PATH, # 3B or 7B
device_map="auto",
trust_remote_code=True,
torch_dtype=compute_dtype,
).eval()
# merge as fp16 model and output
lora_model = PeftModel.from_pretrained(
model,
lora_path,
torch_dtype=torch.float16,
)
lora_model = lora_model.merge_and_unload()
lora_model.save_pretrained("qwen_2.5_vl_r1_2")
tokenizer.save_pretrained("qwen_2.5_vl_r1_2")量化
预量化需要一个数据集用于校准,可准备一个微调训练中用到的数据集(如果是强化微调,请预先用训练后模型生成一些QA)。json数据集中每条数据格式如下:
{"messages": [{"role": "user", "content": "什么是SFT?"}, {"role": "assistant":"content":""}]}采用ms-swift进行量化。为了防止爆显存,量化数据集所选数量quant_n_samples不需要很大,且截断长度max_length不需要设置很大.
# 参考https://blog.youkuaiyun.com/xiaobing259/article/details/147527746
OMP_NUM_THREADS=4
swift export \
--model 'YOUR ROOT/qwen_2.5_vl_r1_2' \
--dataset 'quantize_dataset.json#100'\
'AI-ModelScope/alpaca-gpt4-data-zh#30' \
'AI-ModelScope/alpaca-gpt4-data-en#30' \
--quant_n_samples 160 \
--quant_batch_size 1 \
--max_length 512 \
--quant_method gptq \
--quant_bits 4 \
--output_dir 'Qwen2.5-VL-Instruct-GPTQ-Int4'量化Qwen 2.5 VL 7B Instruct+LoRA(r=32),采用以上配置刚好可以在双卡Tesla T4上运行。
推理
采用GPTQ量化的模型,推荐用vllm进行推理,若采用transformers架构,实测推理速度很慢。 ⚠️ 需要在推理机上也安装上述依赖
from vllm import LLM, SamplingParams
from transformers import AutoProcessor, TextStreamer
import torch
CKPT_PATH='YOUR PATH/Qwen2.5-VL-Instruct-GPTQ-Int4'
tokenizer = AutoProcessor.from_pretrained(CKPT_PATH, trust_remote_code=True)
model = LLM(
model=CKPT_PATH,
dtype="float16", # 同 compute_dtype
quantization="gptq",
gpu_memory_utilization=0.9,
trust_remote_code=True,
)
messages.append({'role': 'user', 'content':"YOUR CONTENT"})
input_text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt = True)
sampling_params = SamplingParams(temperature=0.6, top_p=0.95, top_k=20, max_tokens=4096)
output_st = model.generate(
[input_text],
sampling_params = sampling_params,
)[0].outputs[0].text
print(output_st)量化后速度比较
| 模型设定 | 推理框架 | 推理速度 tokens/s | 显存占用 | 推理质量(目标任务上) |
| Qwen 2.5 VL 7B Instruct | vllm | - | oom | - |
| Qwen 2.5 VL 7B Instruct | transformers | 12.1 | 高 | 低 |
| Qwen 2.5 VL 7B Instruct+LoRA | vllm | - | oom | - |
| Qwen 2.5 VL 7B Instruct+LoRA | transformers | 8.3 | 高 | 高 |
| Qwen 2.5 VL 7B Instruct Merged GPTQ INT4 | vllm | 40.6 | 低 | 中 |
| Qwen 2.5 VL 7B Instruct Merged GPTQ INT4 | transformers | 2(不推荐) | 低 | 中 |
除了gptq,awq等ms-swift支持的量化方案也可以尝试,需要安装不同的依赖,模型和transformers库支持即可。


















 5022
5022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









