




 本文概述了InnoDB数据库如何利用B+树实现数据高效存储,重点讲解了主键索引和非聚簇索引的工作原理,涉及添加数据策略、数据查找路径及全表扫描的场景。还探讨了联合索引的左倾特性、删除数据过程和B+树选择原因。最后,解析了覆盖索引的概念及其在查询优化中的应用。
本文概述了InnoDB数据库如何利用B+树实现数据高效存储,重点讲解了主键索引和非聚簇索引的工作原理,涉及添加数据策略、数据查找路径及全表扫描的场景。还探讨了联合索引的左倾特性、删除数据过程和B+树选择原因。最后,解析了覆盖索引的概念及其在查询优化中的应用。
前言
在程序开发中,总是离不开数据库的支持,如果你做过数据库数据恢复的话,就会发现数据库其实也是存储在磁盘上的文件,而不是我们平时在Navcat上面看到的那些序列数据。
文章只是对自己的思路做总结,如果觉得文章过于简单,请系统了解实现。
工作原理
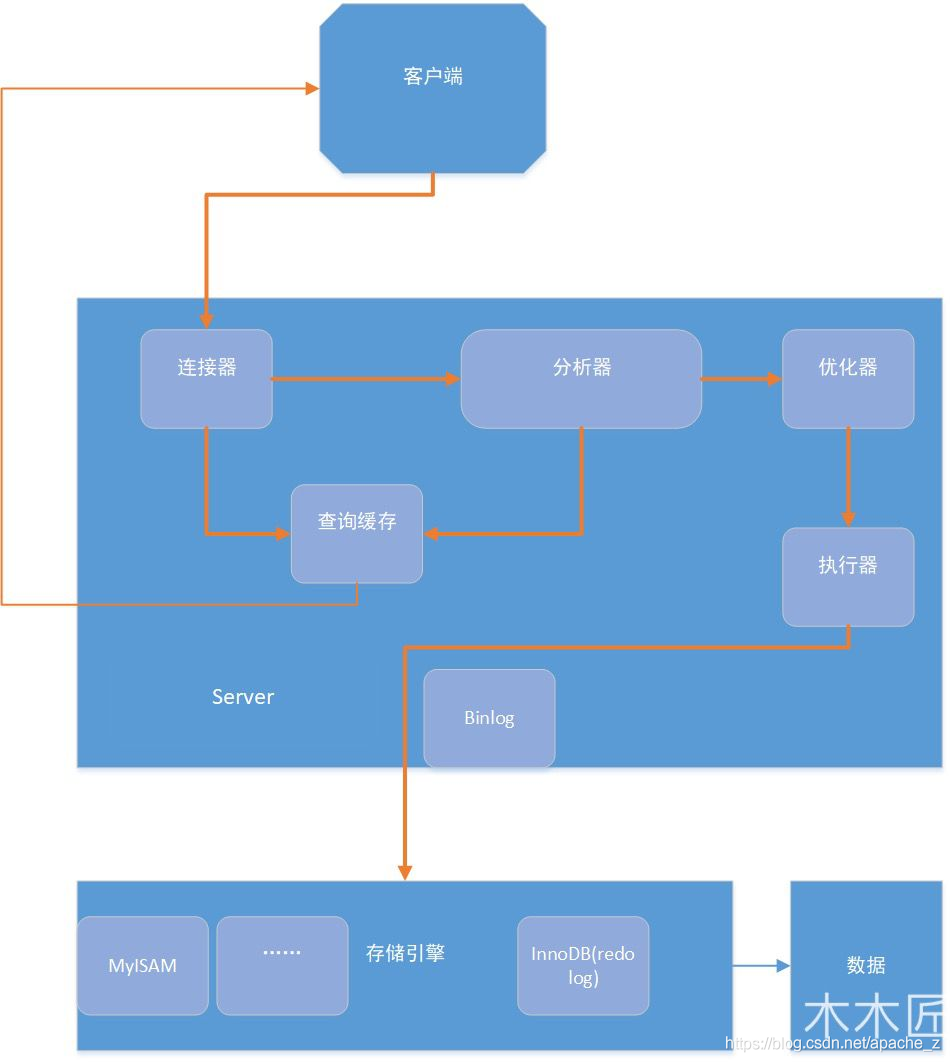
数据存储
在数据库中我们常常选择innodb作为存储引擎,所以,我主要了解的也是这个。
在我们使用数据库的过程中,索引总是跟随着我们,比如主键索引。其实我们的表的数据就是通过索引树的形势存储,也就是聚簇索引(数据存储在叶子节点)。每次添加数据的过程就是对索引树的更新。
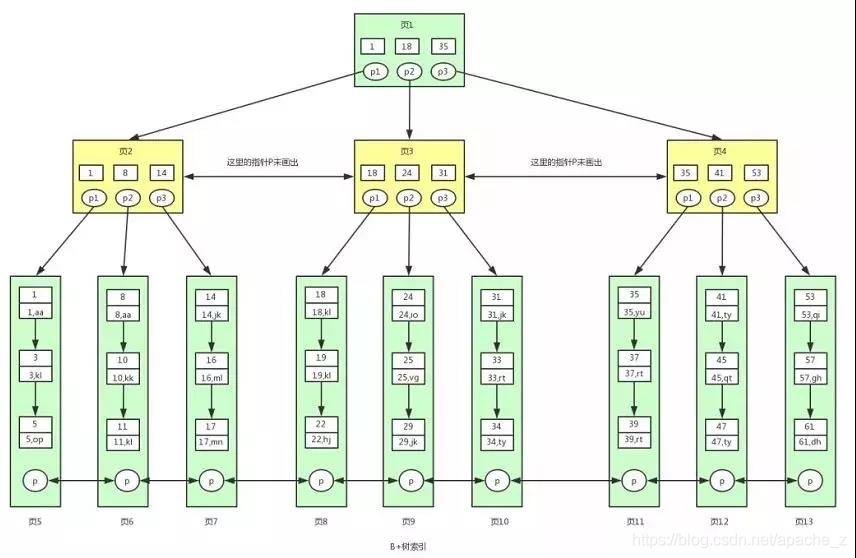
B+树

B+树的特点:
1、所有的非叶子节点只存储关键字信息。
2、所有卫星数据(具体数据)都存在叶子结点中。
3、所有的叶子结点中包含了全部元素的信息。
4、所有叶子节点之间都有一个链指针。
页的概念
在数据库的读取的过程中,每次只取一页数据,而不是单条数据或者是一次读取所有合适数据。
在MySQL中,数据存储是页,16K大小,所以把数据放在叶子节点,以减少创建新页的数量。
核心
添加数据
首先主键是自增的,只需要在树的最后一个叶子节点添加数据,如果页满了,分出新的页添加数据。(如果主键不是,需要在已存在的索引树中查找合适的位置插入,这样不仅需要查找位置,还会导致已存在的页发生变化。)
查找数据
主键索引查找,首先根据B+树查找到对应的页,在页里面存在一种类似于书的目录的数据结构,可以根据目录查找到对应的数据。
非聚簇索引,需要根据索引的值,查找带合适的位置,拿到数据的key,然后回表才能查询到具体的数据。
全表扫描,使用全表扫描的情况,没有合适的索引使用,或者MySQL分析出使用索引速度不如全表扫描,都会使用全表扫描(项目优化,往往需要判断某一条查询是否是全表)。
最后
几个问题:
- 联合索引,为什么有左倾特性。
- 删除数据的过程
- 为什么选择B+树作为MySQL的索引树,而不是B树,B-树,红黑树。
- like的模糊查询以%开头,会导致索引失效。
- 覆盖索引:SQL只需要通过索引就可以返回查询所需要的数据,而不必通过二级索引查到主键之后再去查询数据。


















 580
580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











