



SIRAG框架通过引入决策者和知识筛选器两个轻量级智能体,解决了传统RAG系统中检索器与生成器缺乏协调的问题。采用创新的过程监督训练方法,利用"LLM法官"评估每一步决策质量,解决了强化学习中的信用分配难题。实验表明,该系统在保持轻量级参数的同时,显著提升了RAG在复杂问题上的性能、稳定性和可解释性,为构建更智能的AI系统提供了新范式。
前排提示,文末有大模型AGI-优快云独家资料包哦!
SIRAG: 用多智能体协作与过程监督,打造更稳定、更可解释的RAG系统
自2023年以来,检索增强生成(Retrieval-Augmented Generation, RAG)已成为扩展大语言模型(LLM)能力、解决其知识局限和幻觉问题的核心技术。然而,标准的RAG流程存在一个根本性的挑战:检索器(Retriever)和生成器(Generator)通常是独立开发的,它们之间缺乏有效的协调与沟通。这导致检索器可能返回大量无关或冗余的信息,而生成器又难以充分利用这些信息,甚至在信息不足时也不懂得“再问一次”。
为了解决这一“貌合神离”的困境,一篇名为《SIRAG: Towards Stable and Interpretable RAG with A Process-Supervised Multi-Agent Framework》[1]的论文提出了一种全新的解决方案。它不试图去微调庞大的检索器或生成器本身,而是引入了一个由两个轻量级AI智能体组成的“协调层”,通过多智能体协作和新颖的“过程监督”训练范式,实现了对RAG流程的精细化控制,从而在效果、稳定性与可解释性上取得了显著突破。
RAG的困境:各自为战的检索器与生成器
传统的RAG流程像一条单向的流水线:用户提问 -> 检索器获取文档 -> 生成器根据问题和文档生成答案。这个流程的症结在于,它是一个“一锤子买卖”。
- • 检索质量不可控:检索器一次性返回所有它认为相关的文档,其中可能混杂着噪声。
- • 缺乏动态决策:系统无法判断当前信息是否足够回答问题。对于简单问题,可能检索过度;对于复杂的多跳(multi-hop)问题,一次检索又远远不够。
- • 生成器负担过重:生成器需要从良莠不齐的文档中自行筛选、整合信息,这极大地考验了它的上下文理解和抗干扰能力。
虽然业界已经有了诸如重排器(Reranker)、查询重写(Query Rewriting)等改进方案,但它们往往只优化了流程中的某个单一环节,未能从全局上解决检索与生成之间的协同问题。
SIRAG的核心架构:引入两位轻量级AI智能体
SIRAG的核心思想是在固定的检索器和生成器之间,插入一个智能决策系统。这个系统由两个协同工作的轻量级AI智能体构成,它们像一个团队,共同管理整个问答流程。
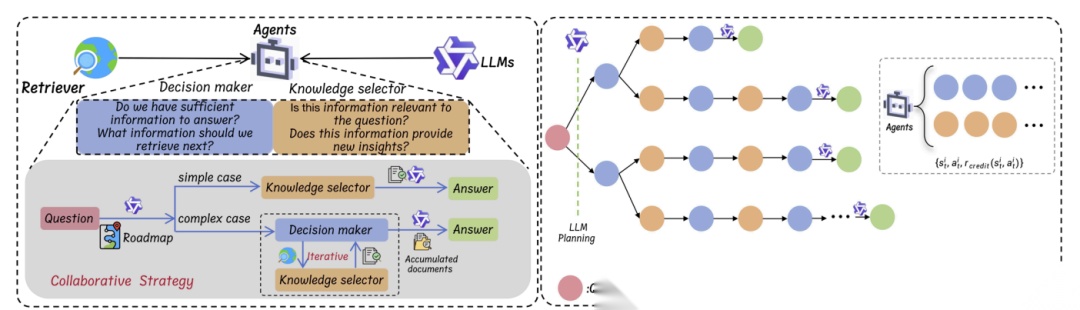
SIRAG的整体框架。左侧展示了决策者和知识筛选器两个智能体如何协同工作,动态地决定是继续检索还是生成答案。右侧则描绘了使用强化学习进行端到端优化的流程
-
- 决策者 (Decision Maker, DM):扮演着“项目经理”或“策略师”的角色。在每一步,它都会审视当前的问题和已经收集到的所有信息,然后做出关键决策:
- •
Retrieval(new query):如果认为当前信息不足,它会决定发起新一轮的检索,甚至可以生成一个更精确的查询语句。 - •
Stop&Generation:如果认为信息已经充分,它就会叫停检索,并将整理好的信息移交给生成器,产出最终答案。
-
- 知识筛选器 (Knowledge Selector, KS):扮演着“图书管理员”或“信息分析师”的角色。每当检索器返回一批新文档时,KS就会介入,仔细评估每个文档与问题的相关性以及是否提供了新的见解,然后筛选出一个最优的文档子集,将其加入到“证据池”中。
通过这两个智能体的交替协作,SIRAG将原本静态的RAG流水线改造成了一个动态、迭代的闭环系统。对于简单问题,DM可能在第一轮检索后就决定生成答案;而对于需要层层递进推理的复杂问题,DM和KS可以进行多轮“检索-筛选”循环,逐步构建出完整的证据链,最后才生成答案。
最关键的是,这两个智能体模型可以非常轻量(实验中仅为0.5B参数),它们作为“代理”或“协调者”,无需改动或重新训练动辄千亿参数的底层LLM和检索模型,实现了真正的“即插即用”。
训练的艺术:过程监督与强化学习
如何让这两个智能体学会高效协作呢?传统的强化学习方法通常只看最终答案是否正确,给予一个稀疏的奖励信号。这种方式存在严重的“信用分配”问题:一个成功的答案背后可能包含了数个决策步骤,我们无从知晓哪一步是关键,哪一步是多余的;反之,一个错误的答案也可能包含了一些正确的中间步骤。
为了解决这个问题,SIRAG引入了其最具创新性的部分——过程监督(Process Supervision)。
LLM-as-a-Judge:引入过程级奖励
SIRAG不再仅仅依赖最终答案的正确性,而是请来一个强大的“导师”模型(如GPT-4或Qwen2-72B)作为法官(Judge),在训练过程中监督每一个中间步骤。
每当DM或KS做出一个动作(例如,DM决定再次检索,或KS选择了一组文档),“法官”LLM都会对这个动作的质量进行打分,评估其是否“合理、信息丰富、且与问题意图一致”。这样,每个中间动作都能得到一个即时的、细粒度的奖励信号。
最终的奖励由两部分加权构成:
总奖励 = α * 最终答案正确性奖励 + β * 过程质量奖励
这种机制极大地提升了训练的稳定性和效率。智能体不仅知道最终目标,还清楚地了解通往目标的每一步应该怎么走才是“好”的,从而学会了更优的决策策略。
树状演练与PPO优化
为了让智能体探索更多样的决策路径,SIRAG在训练时采用了树状结构演练(tree-structured rollout) 策略。它会主动探索不同的决策分支(比如,第一步是检索还是直接生成),确保模型能学到应对不同情况的策略。
最后,整个系统利用近端策略优化(Proximal Policy Optimization, PPO) 算法进行端到端的训练,让两个智能体在最大化综合奖励的目标下,不断优化自己的协作策略。
实验效果:更准、更稳、更高效
SIRAG在多个单跳和多跳问答基准测试中都取得了优异的成绩。

SIRAG在四个数据集上的主要表现。可以看到,SIRAG(0.5B)在平均性能上显著优于包括标准RAG、Reranker、Query-Writer以及selfRAG在内的基线方法
从上表中可以看出:
-
- 性能卓越:SIRAG以仅0.5B的智能体参数量,在平均准确率上达到了46.23%,全面超越了其他基线方法。
-
- 擅长复杂问题:在2WikiMultiHopQA和HotpotQA这两个最具挑战性的多跳问答数据集上,SIRAG的性能提升尤为显著(分别提升了9.3%和9.2%),证明了其动态、多轮的检索-筛选机制对于解决复杂问题至关重要。
-
- 高性价比:相较于需要微调7B模型的selfRAG等方法,SIRAG在实现了更高性能的同时,展现了极高的参数效率。
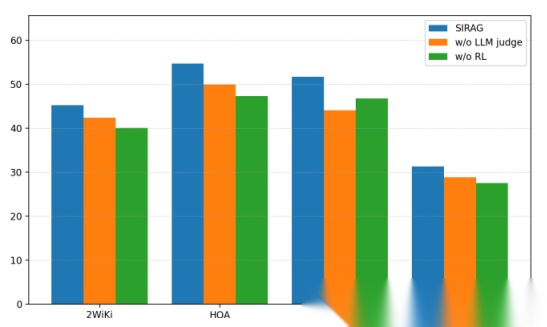
消融实验结果。SIRAG的完整模型性能最佳。移除“LLM法官”后,模型性能下降且不稳定。移除强化学习(仅使用预热阶段模型)后,性能也大幅降低
消融实验进一步证明了SIRAG设计的有效性。当去掉“LLM法官”提供的过程监督后(w/o LLM judge),模型的性能变得非常不稳定,有时甚至不如初始模型,这凸显了过程级奖励对于稳定训练的关键作用。而与没有经过强化学习优化的模型(w/o RL)相比,完整版的SIRAG性能有巨大飞跃,证明了端到端优化对于智能体协作的必要性。
核心优势与未来展望
总而言之,SIRAG框架为优化RAG系统提供了一个全新的、极具前景的范式。其核心优势在于:
-
- 模块化与即插即用:无需改动现有的RAG基础设施,只需在其上层增加一个轻量级的智能体协调层即可。
-
- 过程监督带来的稳定性:通过“LLM法官”机制,解决了强化学习中的信用分配难题,使训练过程更稳定、收敛更快。
-
- 增强的可解释性:智能体的每一步决策(何时检索、筛选哪些文档、何时停止)都构成了一条清晰的推理轨迹,让我们可以直观地理解系统是如何一步步得到答案的。
-
- 卓越的性能与效率:用极小的代价,显著提升了RAG系统在复杂问题上的处理能力。
在AI智能体与多智能体协作日益成为主流的2025年,SIRAG的设计思想无疑是与时代脉搏同频的。它不仅是RAG技术的一次重要演进,也为我们如何构建更智能、更可控、更具协作性的AI系统,提供了一个绝佳的范例。未来,我们或许可以看到类似的多智能体“协调层”被应用于更广泛的AI任务中,成为驾驭和组织强大基础模型不可或缺的一环。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









