




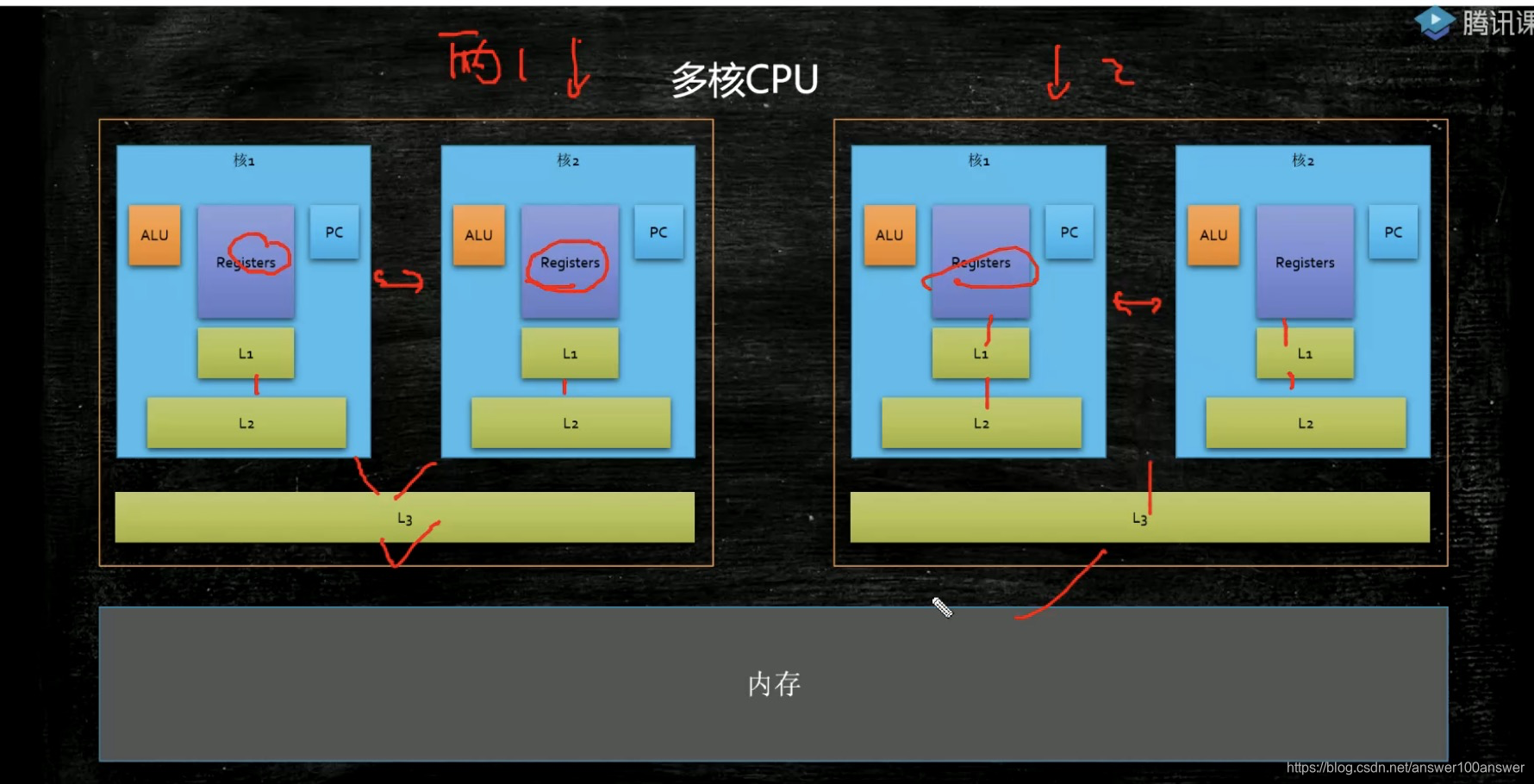
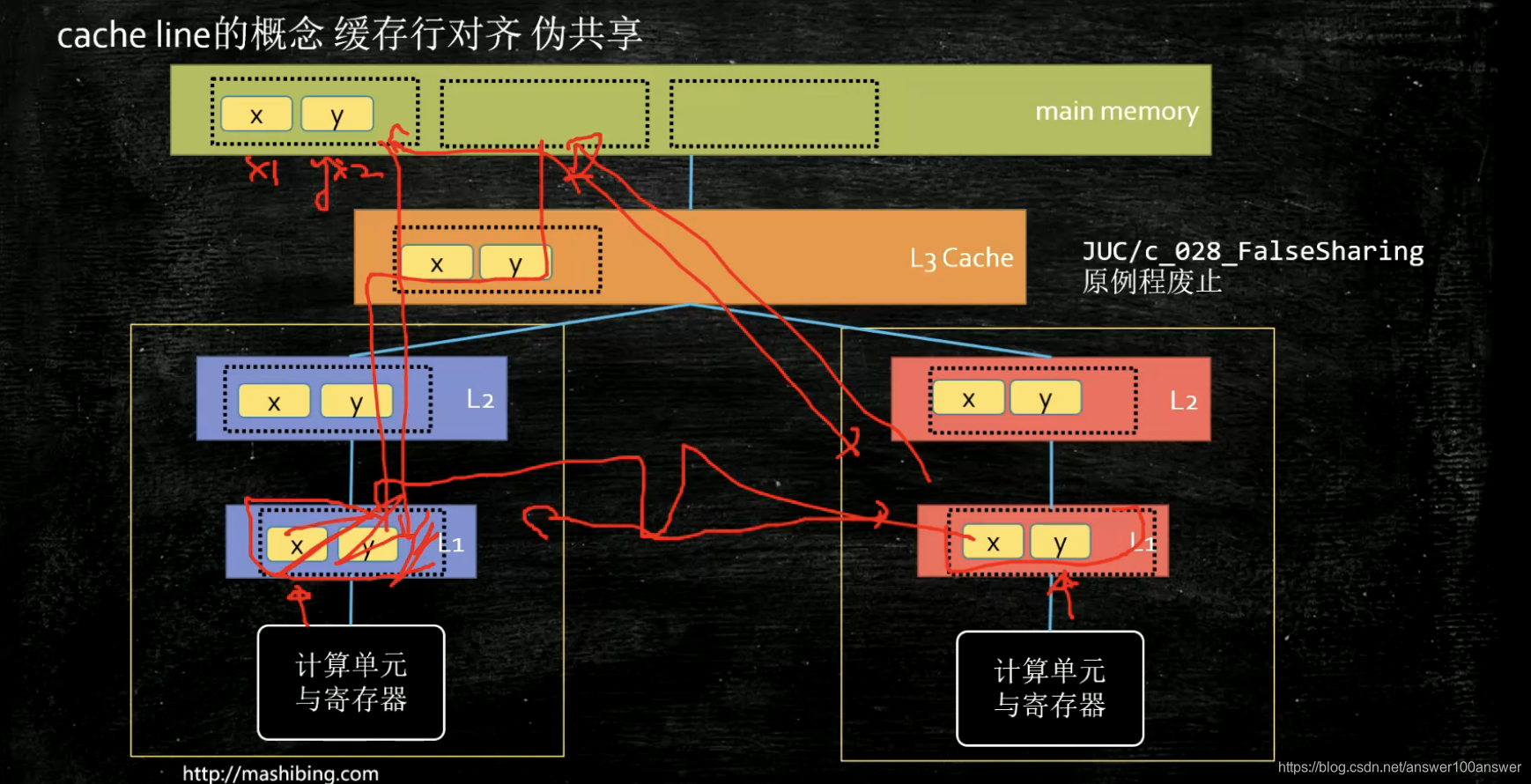
先找L1缓存,再找L2缓存,再找L3缓存。

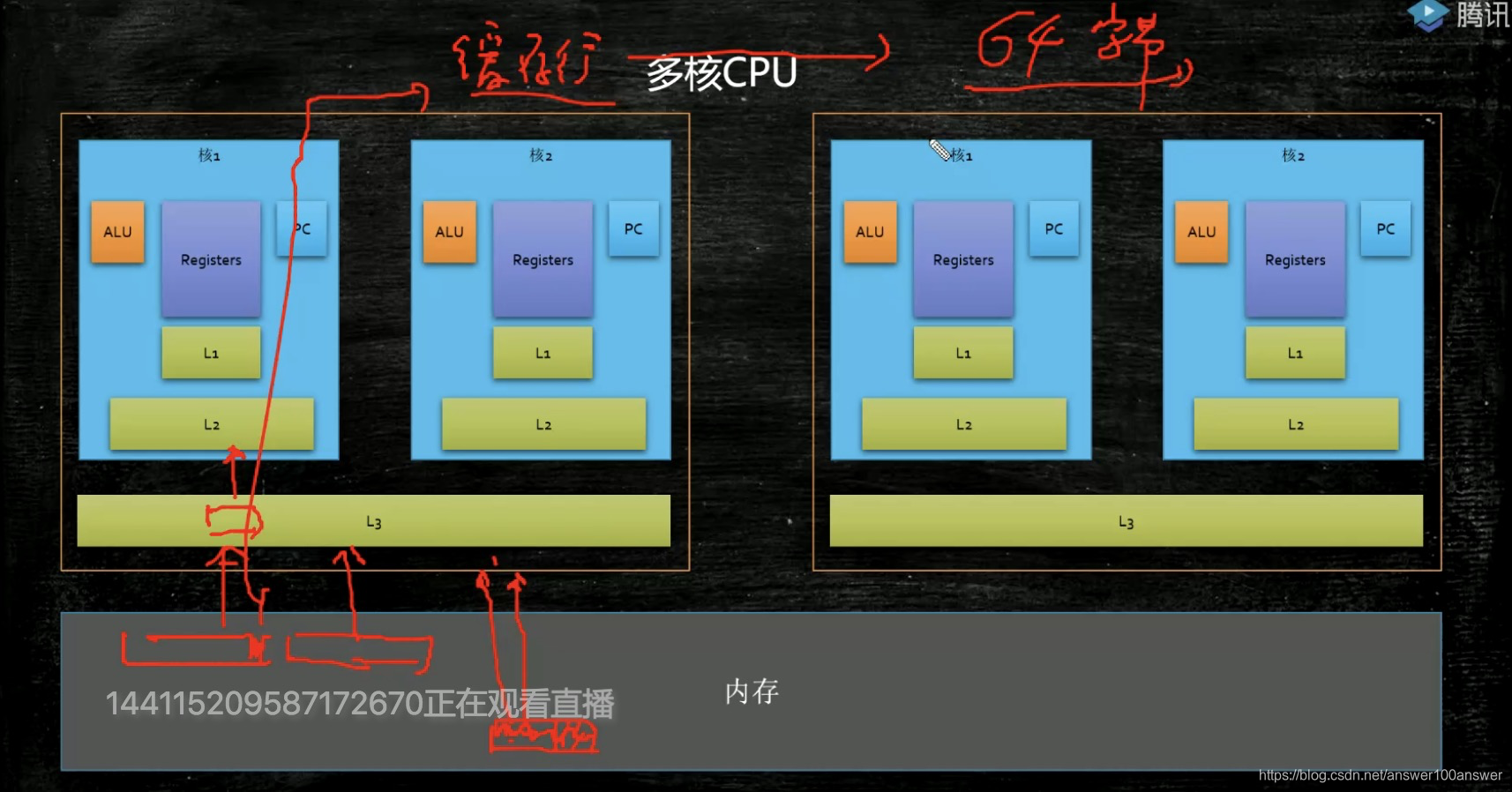
缓存是按块来读的。缓存块的大小叫做缓存行,固定大小64字节。

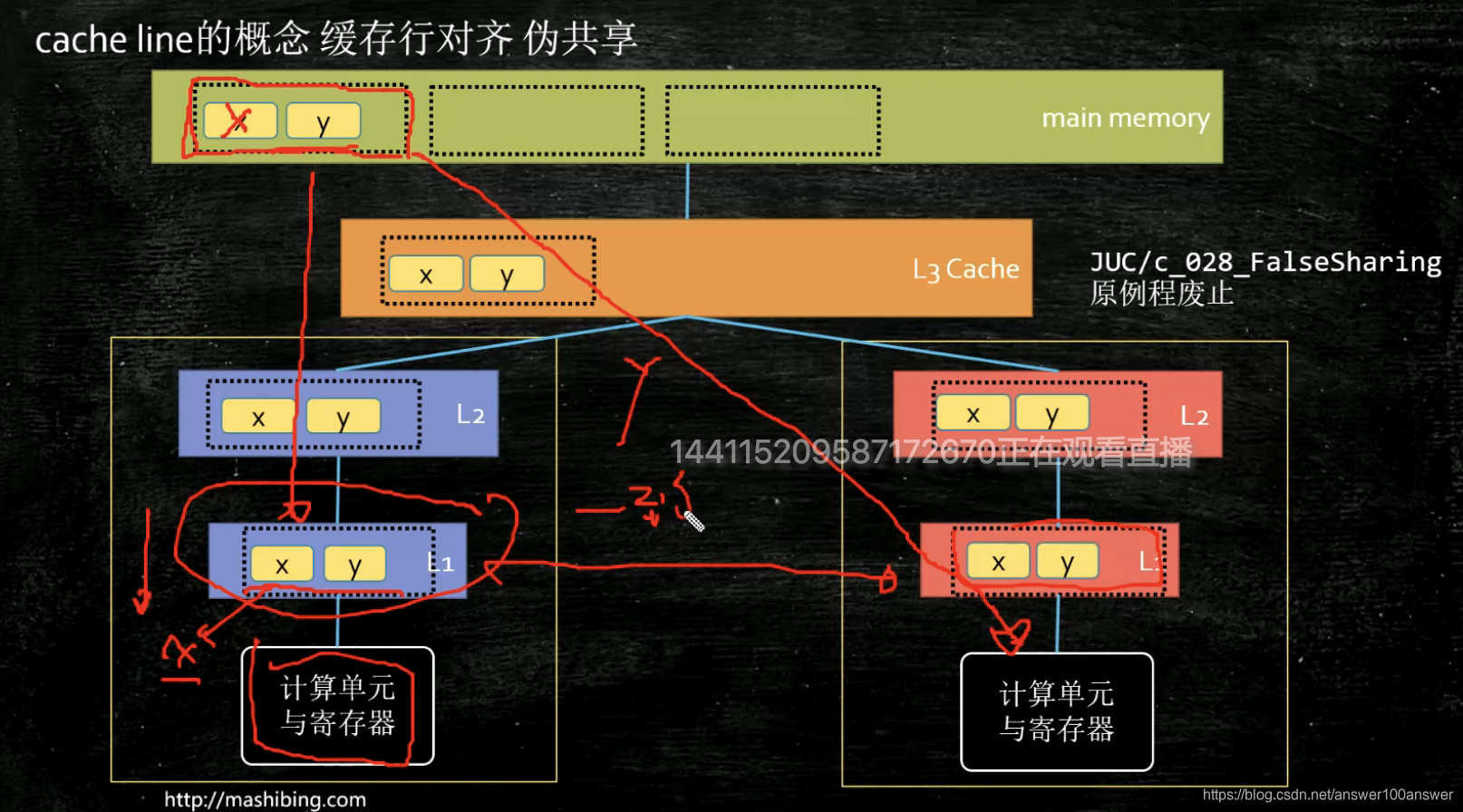
缓存一致性:缓存行在其他核更新时,本缓存如何更新?

缓存行的4中状态。英特尔CPU使用MESI缓存一致性协议。

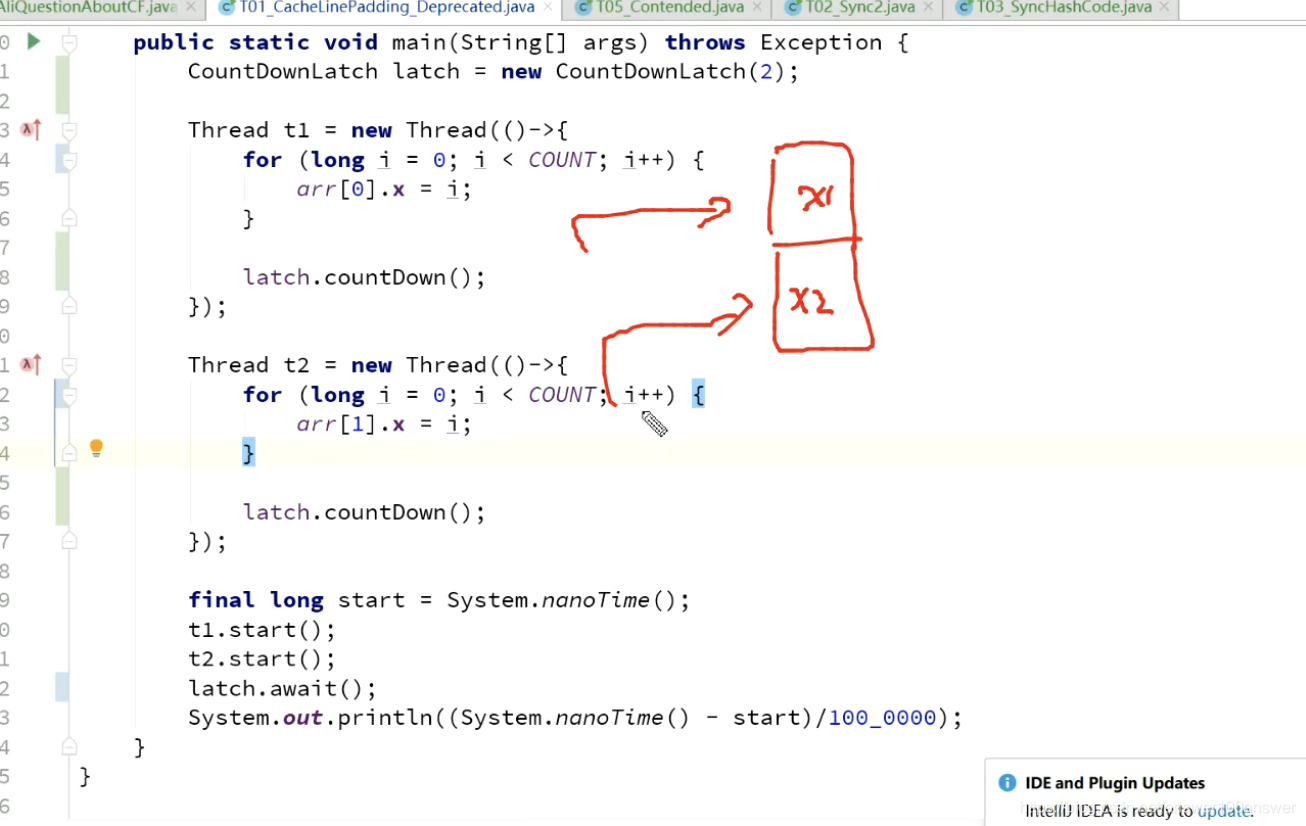
花3s时间。
对比:
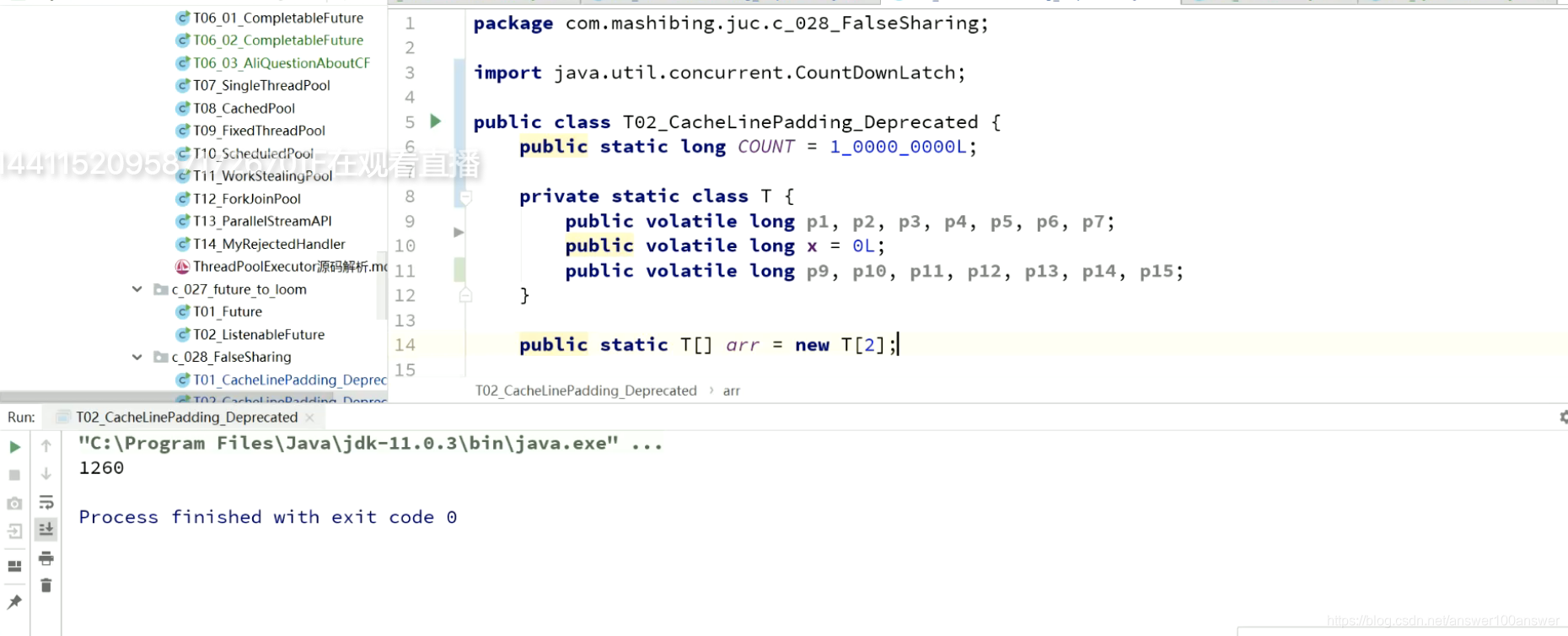
只花了1.2s。
说明:两个值非常近时,多线程访问速度可能低。
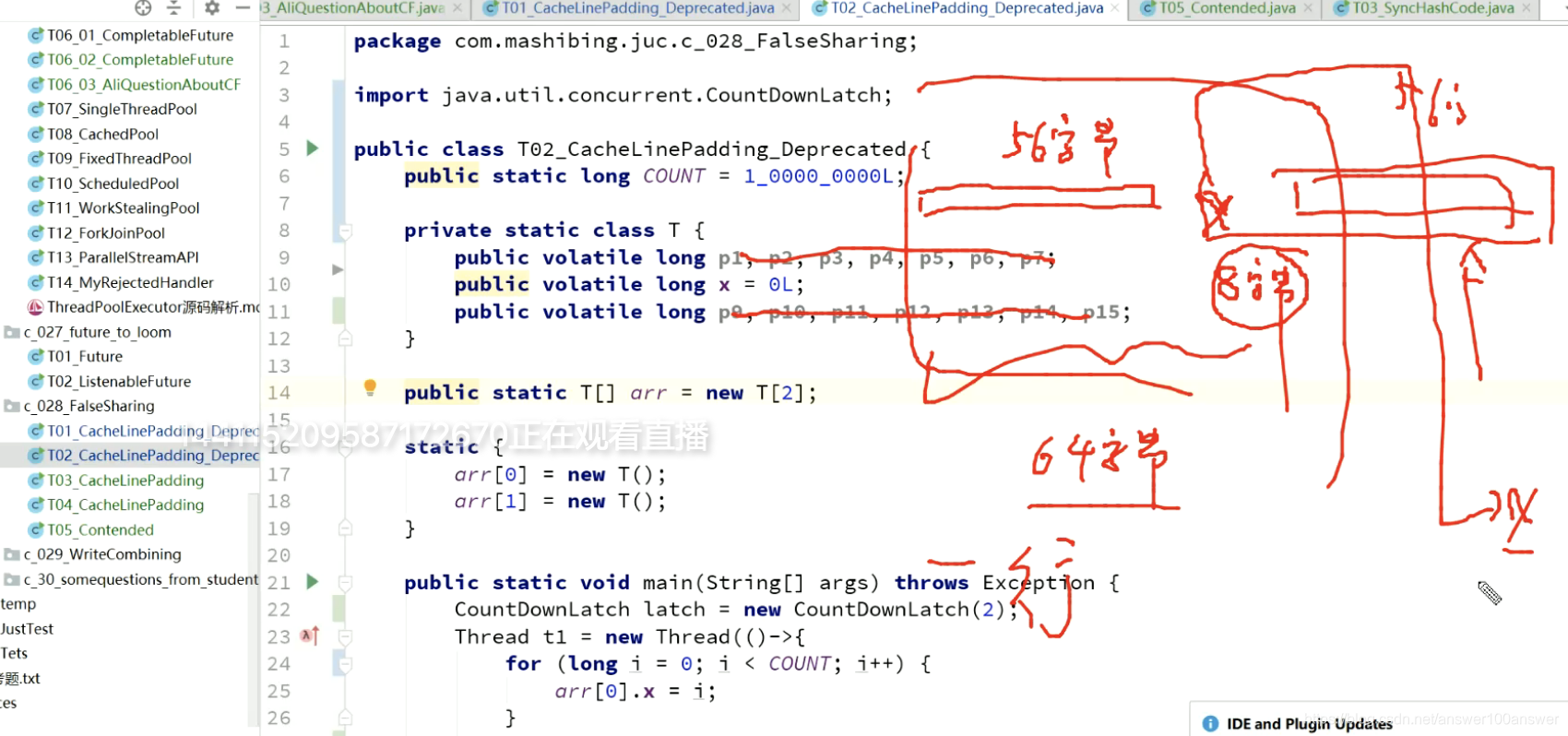
加入填充后,x不可能与其他变量在同一个缓存行。因此改变时不需要通知其他缓存行。
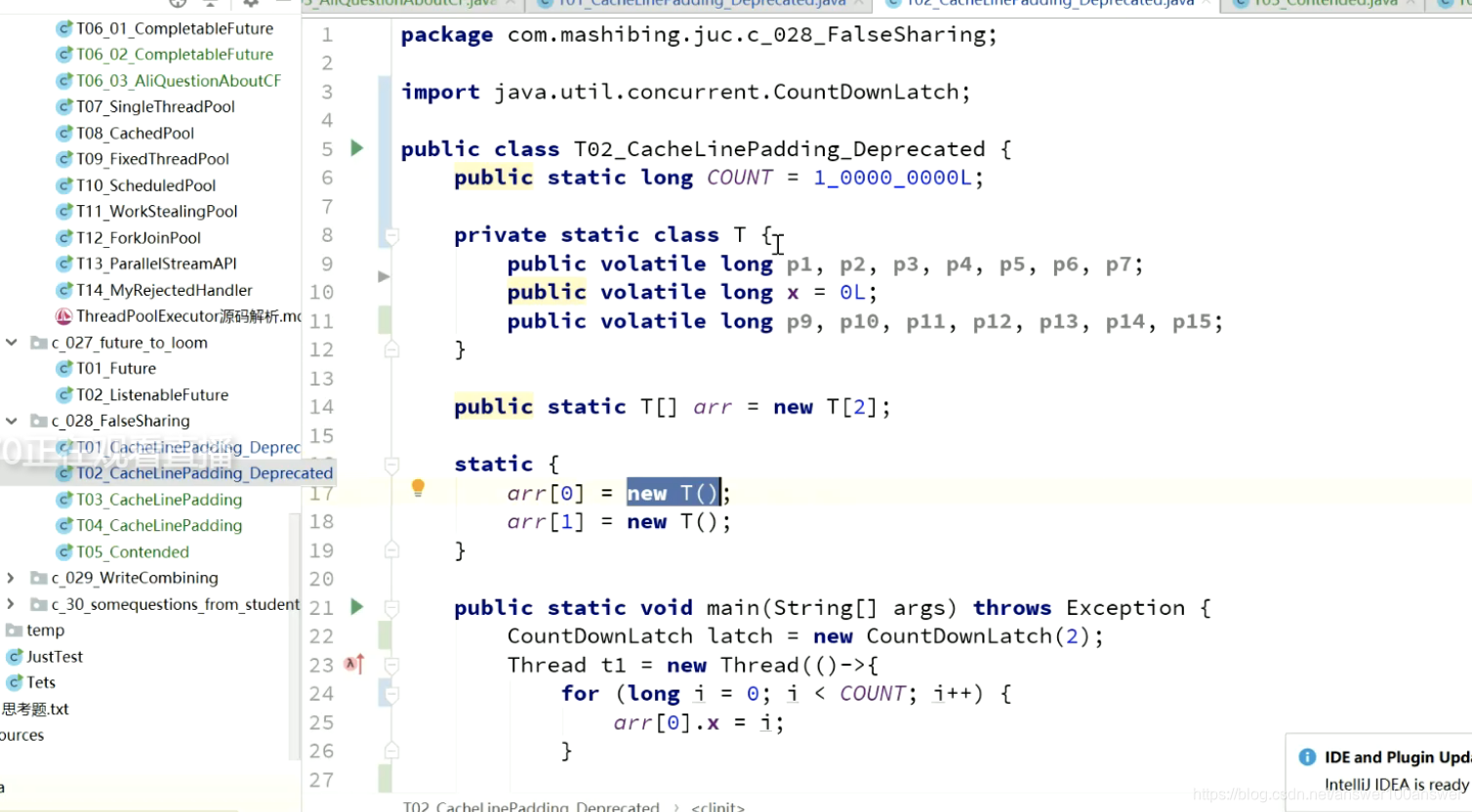
有的源码如下:

添加了无效字段的填充。
volatile:1.线程可见性
2.禁止重排序。
cpu速度是内存的100倍。
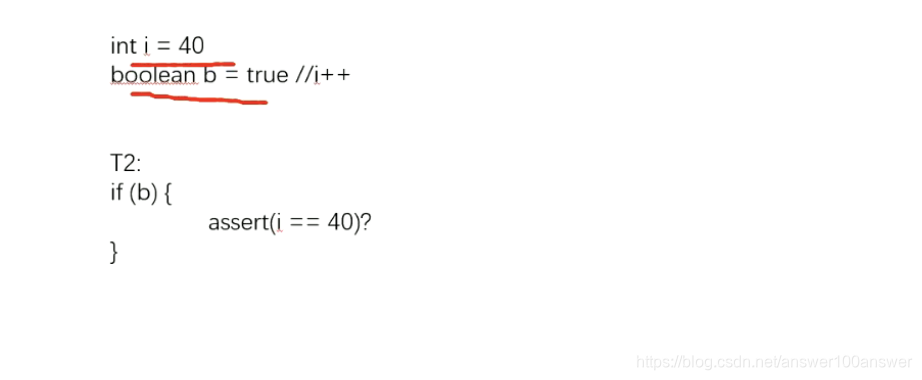
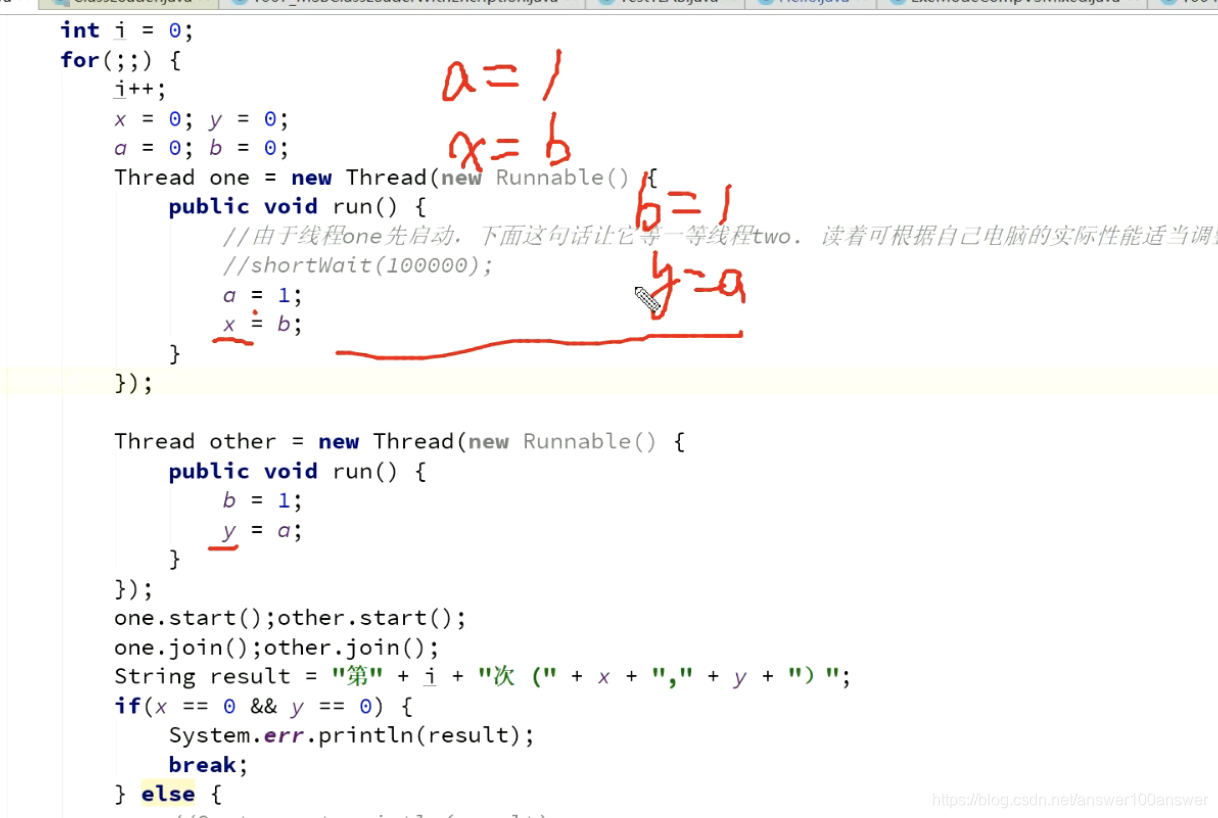
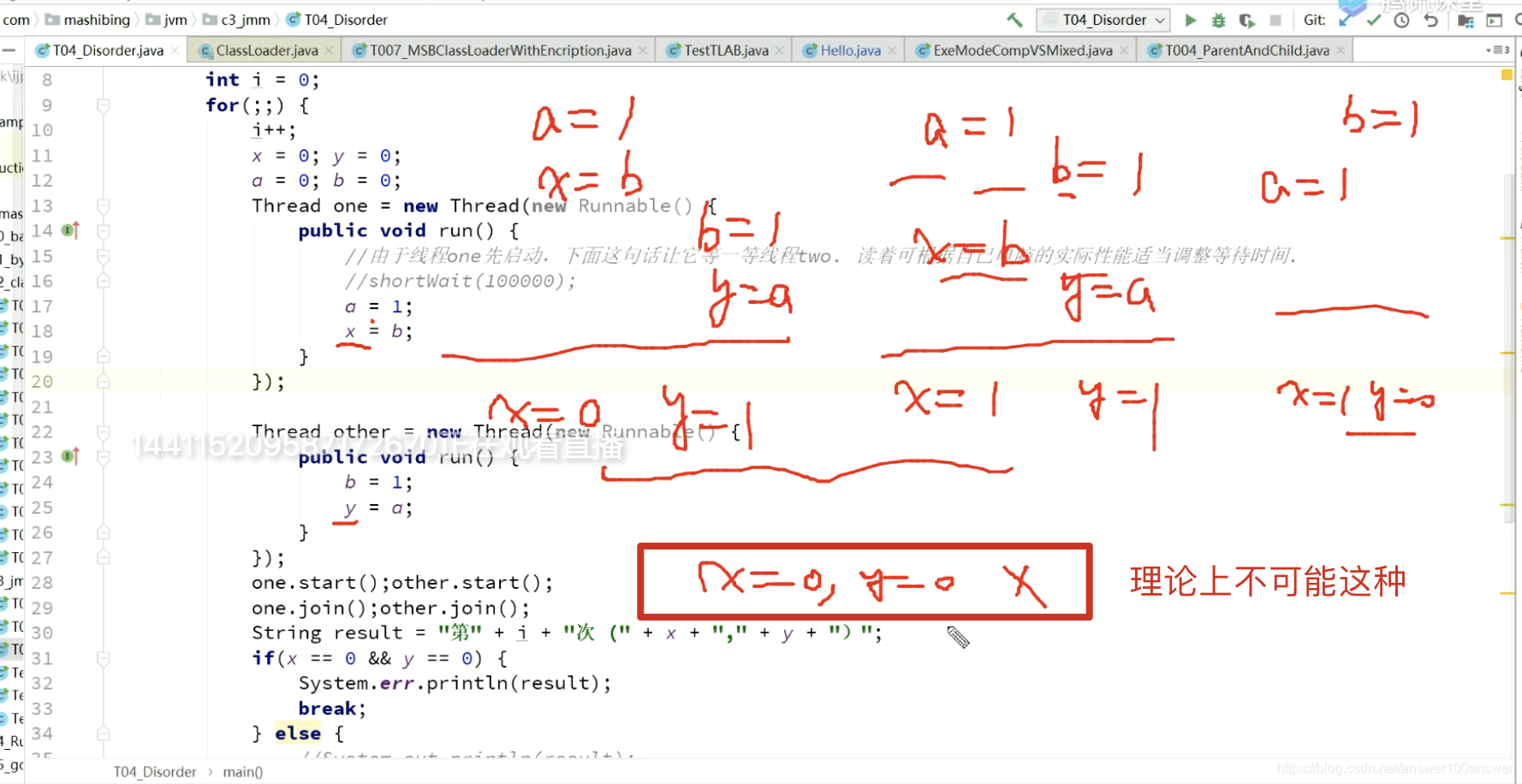
原因是CPU会乱序执行。
DCL单例要不要加volatile。

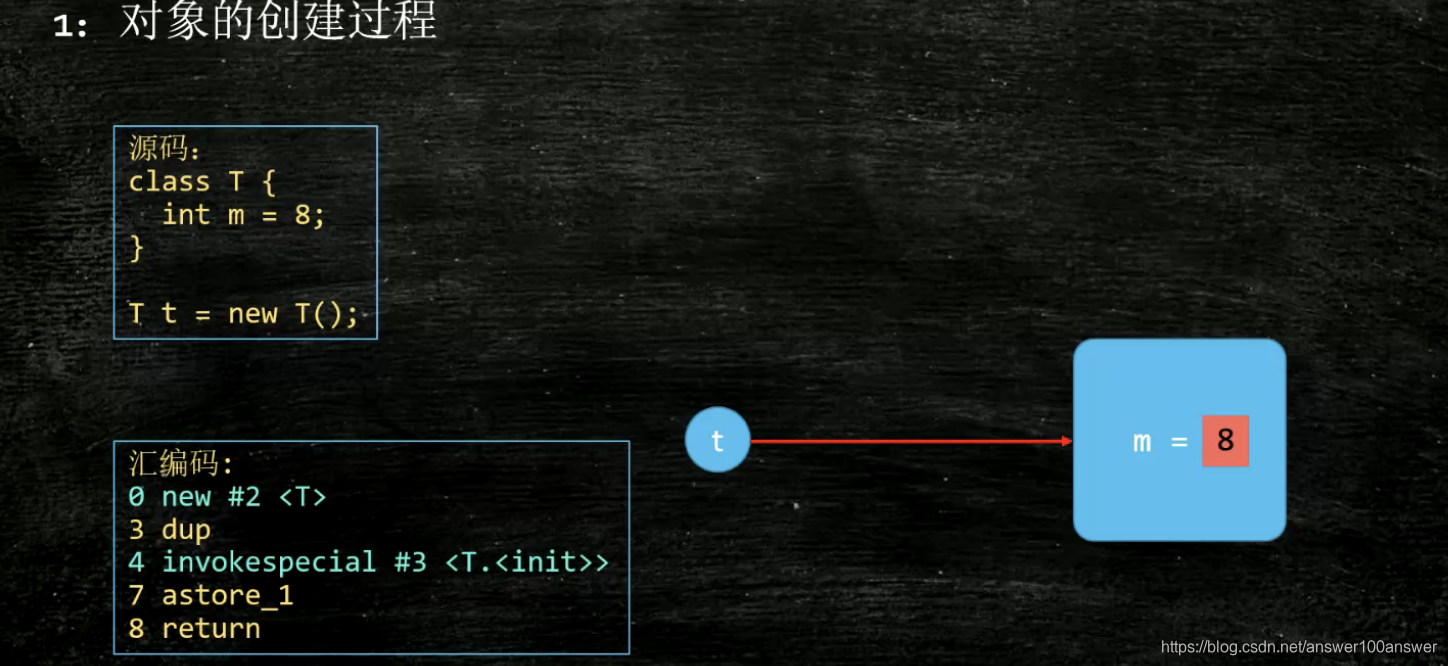
DCL:Double Check Lock
这个单例还挺不错的。
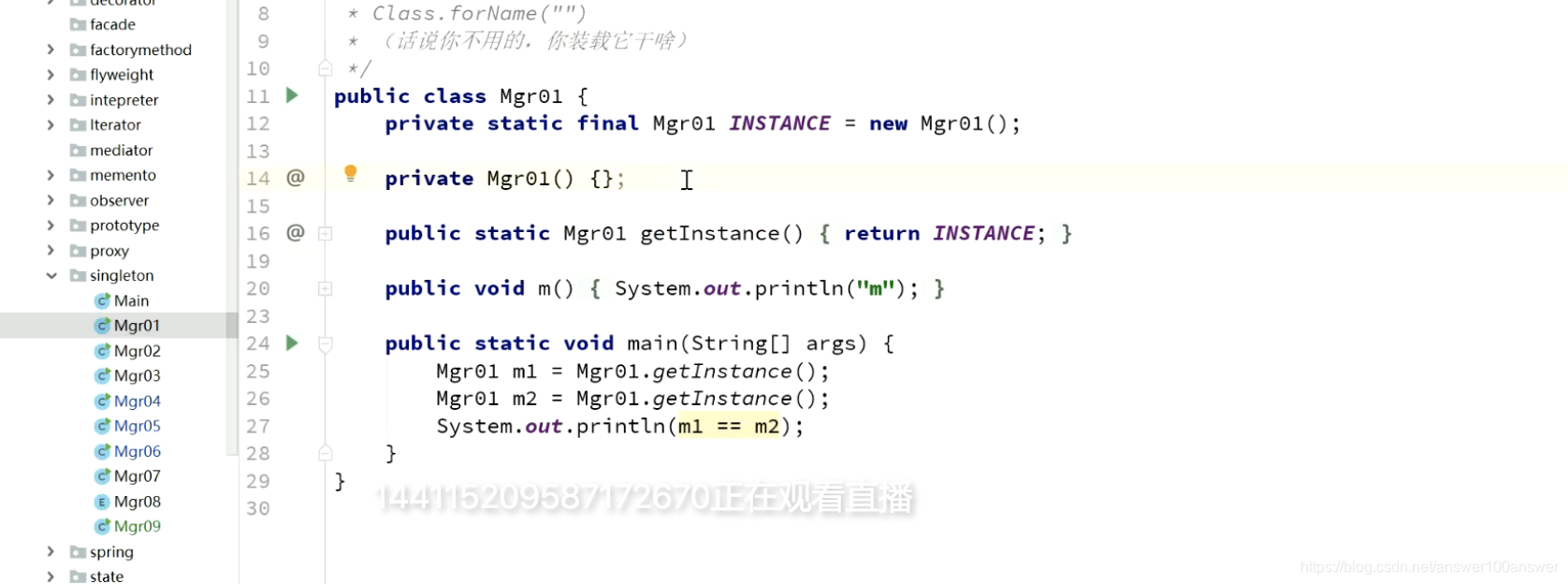
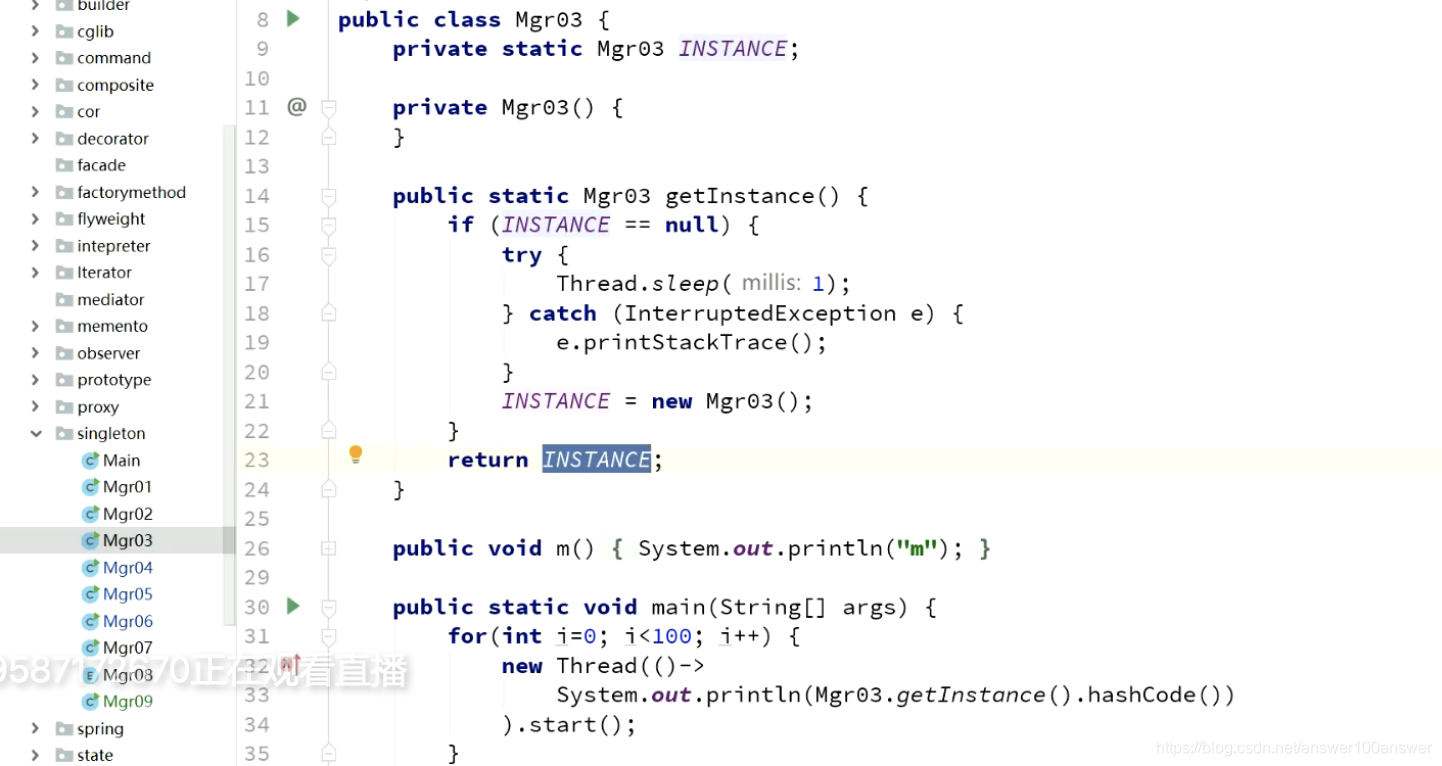

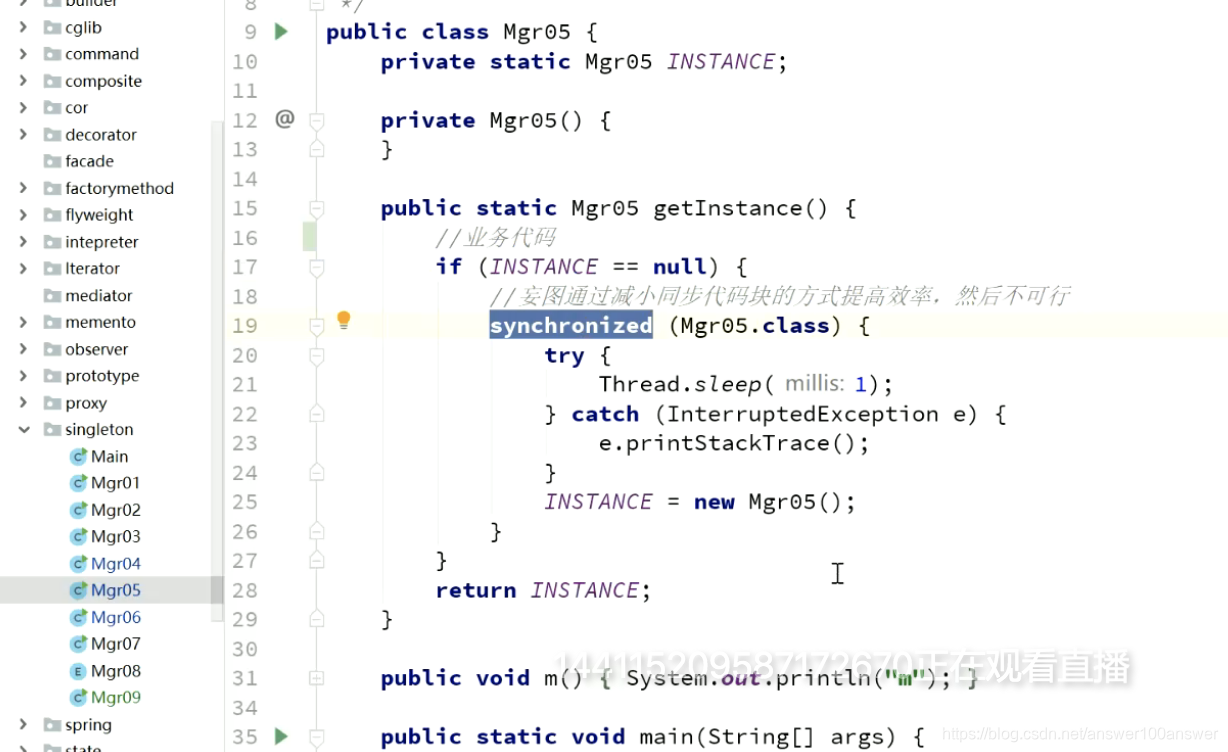

经典的DCL写法。以下写法是完美的。很多代码都会用。
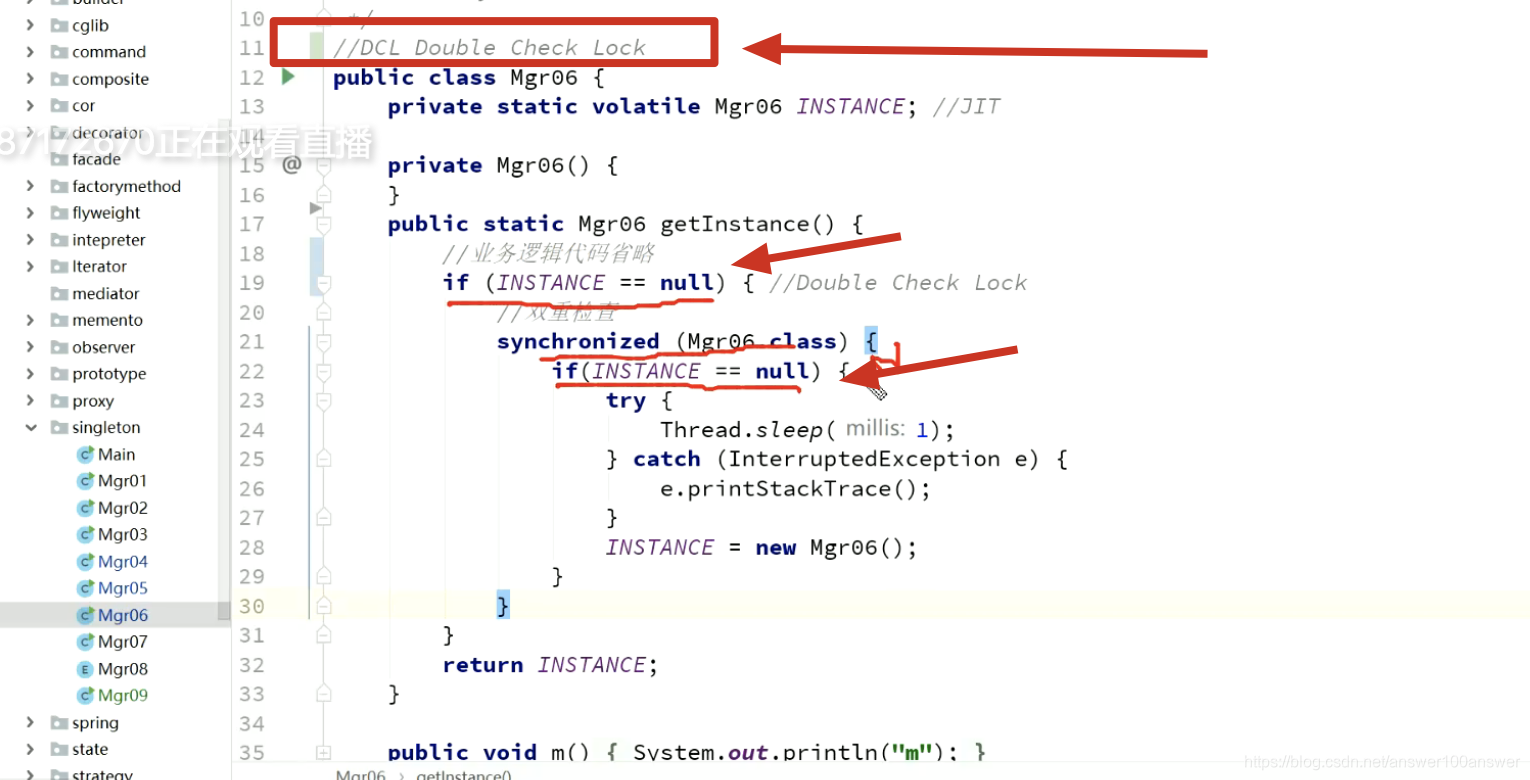
先判断的时间非常短,比直接上锁快很多。
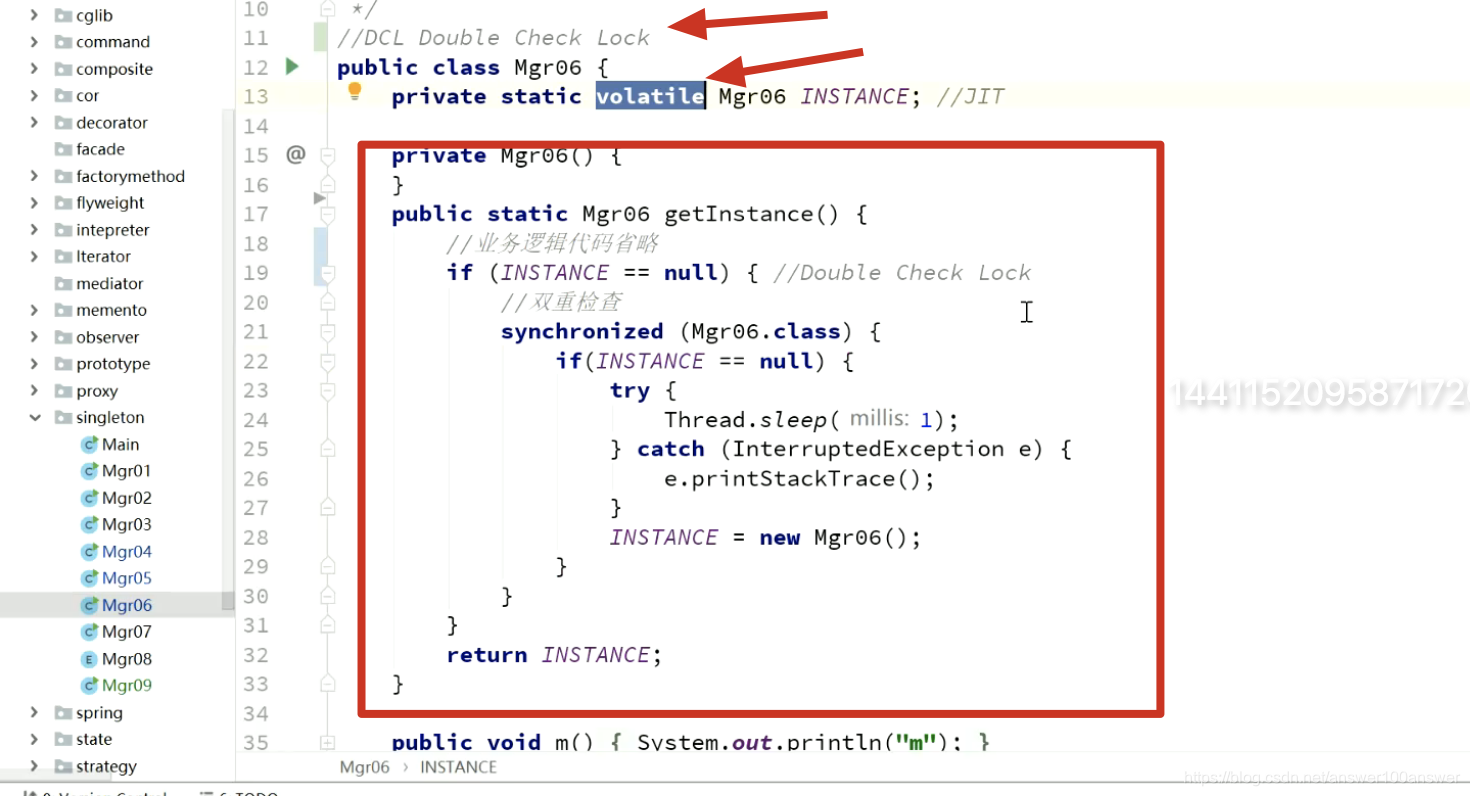
注意上边有一个volatile,必须加!!!
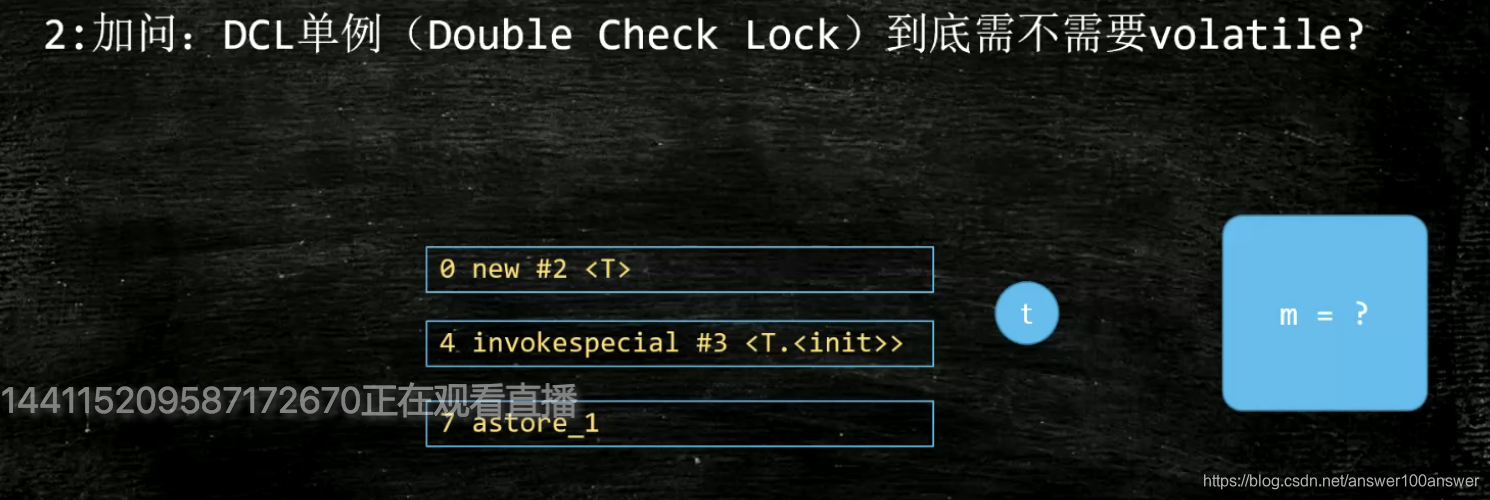
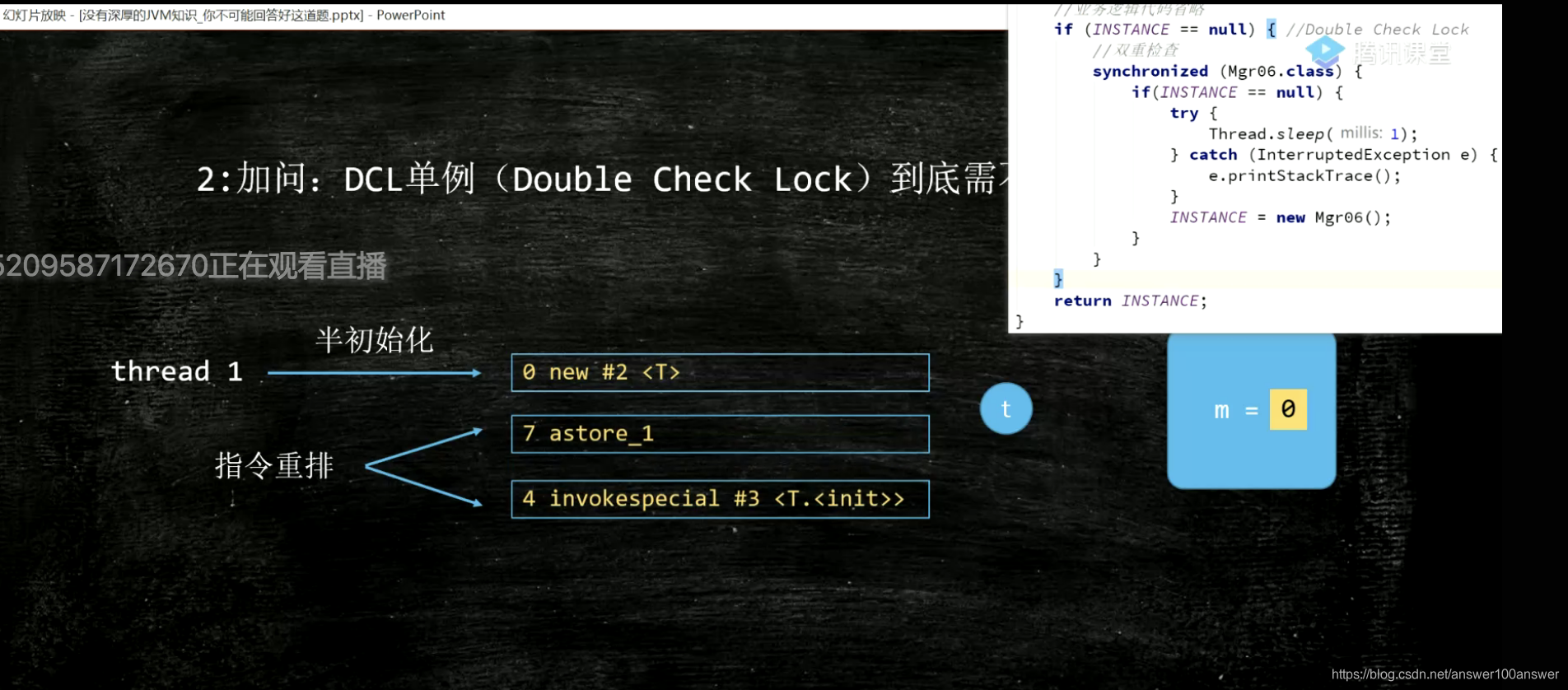

读读;写写;读写;写读;





1.Runnable线程没有返回值。
2.Callable有返回值,返回值是Future。Future拿到结果需要阻塞。
3.Google的包:ListenableFuture。这个可以完美解决。
4.jdk1.8学习ListenableFuture,诞生了CompleteFuture,比ListenableFuture更叼。
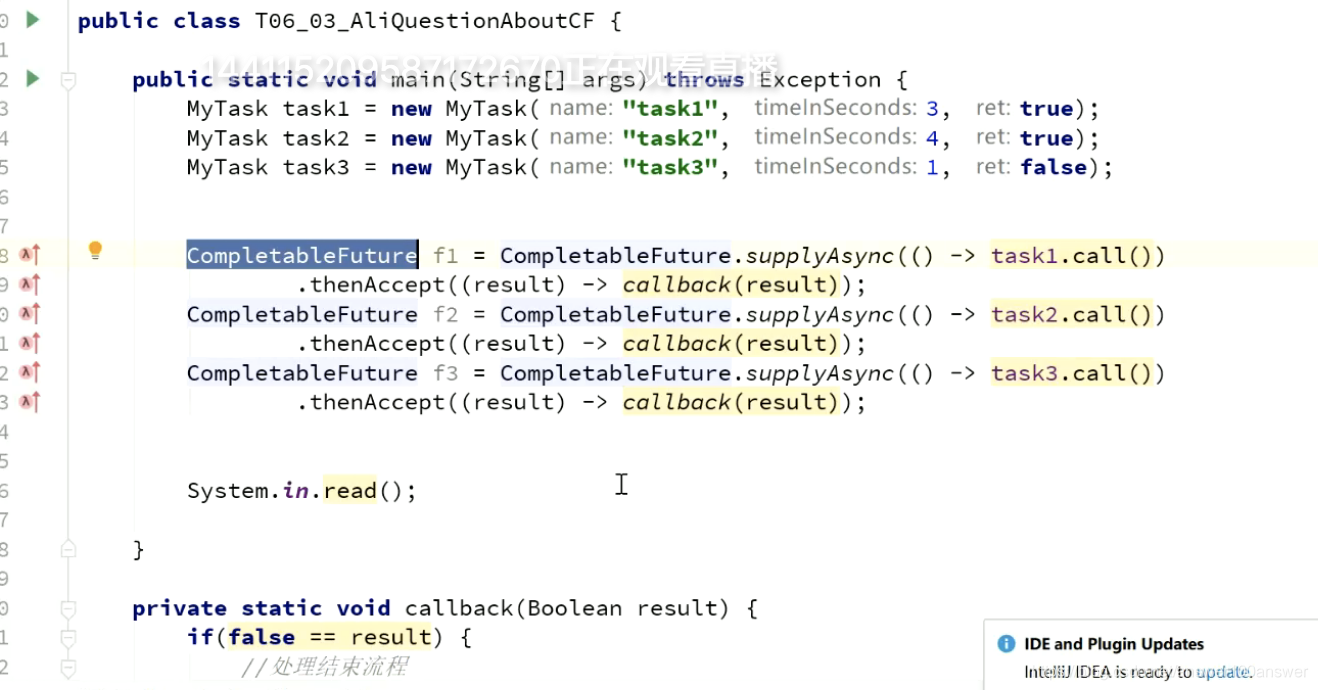
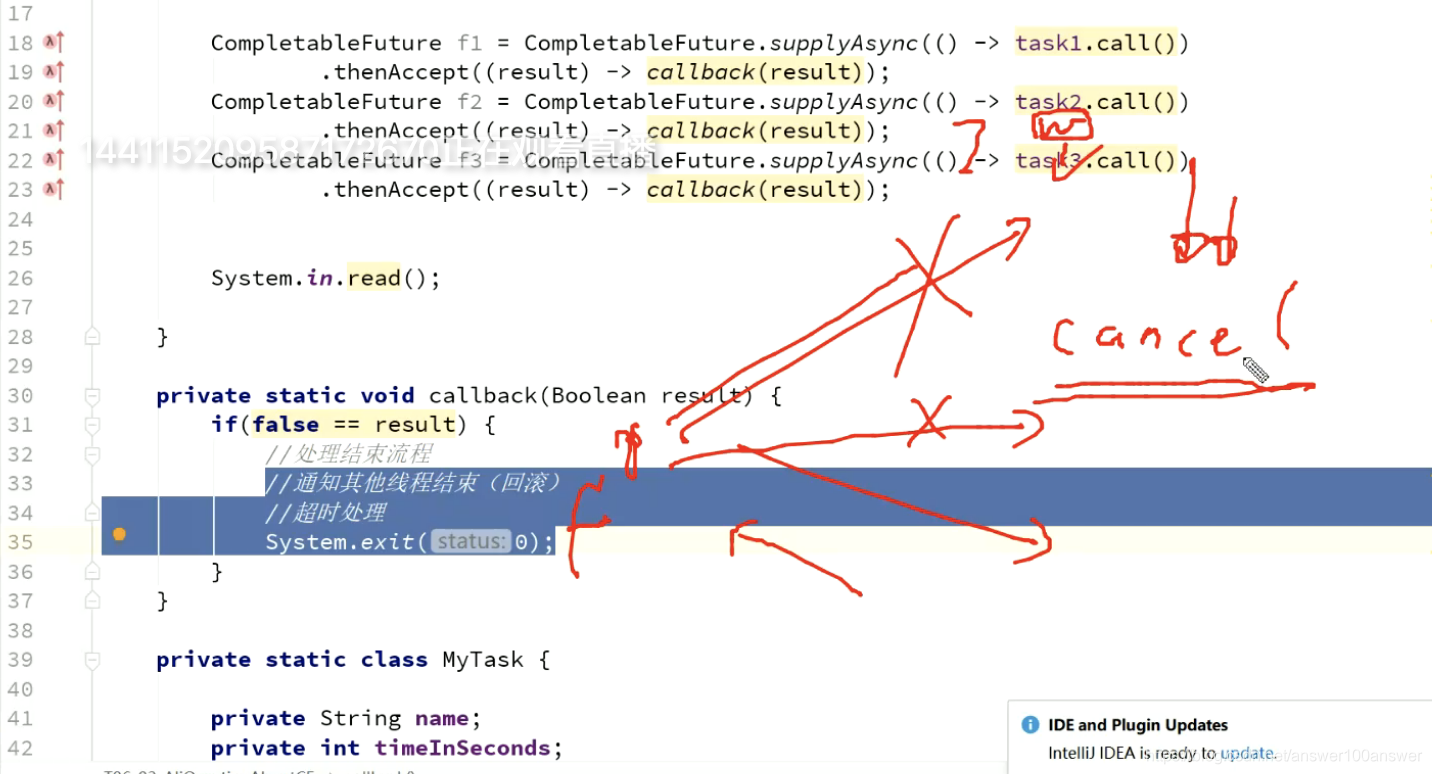
中断时需要cancel方法。

















 2214
2214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









