1.现有quota的设置与使用
1.setQuota客户端到NN的主要流程
setQuota的shell入口示例如下:
hdfs dfsadmin -D fs.defaultFS=DClusterNmg4 -setQuota 1819200 hdfs://ns1/user/prod_xxx
hdfs dfsadmin -D fs.defaultFS=DClusterNmg4 -setSpaceQuota 666T hdfs://ns1/user/prod_xxx
对应的NN端:该shell的执行过程从Client到NN的主要流程如下
——1.DFSAdmin$SetSpaceQuotaCommand#run
——2.DistributedFileSystem#setQuota
——3.DFSClient#setQuota
——4.FSNamesystem#setQuota
——5.FSDirAttrOp#unprotectedSetQuota
——6.INodeDirectory#setQuota
DirectoryWithQuotaFeature特性分为两种:quota数值和使用量:
private QuotaCounts quota;
private QuotaCounts usage;
在设置quota时,直接向客户端传入的long型的数值设置到Feature中。
因此在quota由物理改为逻辑时,setQuota部分无需更改。
quota会落地到fsimage,usage每次加载时动态计算,usage的值的计算逻辑需要更改。
2.count -q / -u 查看quota
hadoop fs -count -q 或 hadoop fs -count -u 命令客户端代码如下:
// Count.java
protected void processPath(PathData src) throws IOException {
StringBuilder outputString = new StringBuilder();
if (showQuotasAndUsageOnly || showQuotabyType) {
QuotaUsage usage = src.fs.getQuotaUsage(src.path);
outputString.append(usage.toString(
isHumanReadable(), showQuotabyType, storageTypes));
} else {
ContentSummary summary = src.fs.getContentSummary(src.path);
outputString.append(summary.toString(
showQuotas, isHumanReadable(), excludeSnapshots));
}
if(displayECPolicy){
ContentSummary summary = src.fs.getContentSummary(src.path);
if(!summary.getErasureCodingPolicy().equals("Replicated")){
outputString.append("EC:");
}
outputString.append(summary.getErasureCodingPolicy());
outputString.append(" ");
}
outputString.append(src);
out.println(outputString.toString());
}
主要计算逻辑直接对应到NN端同名方法。这里会走两个方法:
- src.fs.getQuotaUsage(src.path): 只查看 QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA(物理空间)四个与设置quota有关时使用该方法
- src.fs.getContentSummary(src.path): 除了上述还会额外显示 DIR_COUNT FILE_COUNT CONTENT_SIZE(已用逻辑空间)
注意:getQuotaUsage和getContentSummary会走不同的方法:
- getQuotaUsage:直接取DirectoryWithQuotaFeature中的usage字段,该值是一个缓存值,启动后放在内存中。NN启动时会计算所有子目录求和所得。
- getContentSummary:每次重新计算
2.quota在hadoop中的限制作用
超过quota限制时,NameNode端会返回DSQuotaExceededException异常,如下:
|
// DSQuotaExceededException
public String getMessage() {
String msg = super.getMessage();
if (msg == null) {
return "The DiskSpace quota" + (pathName==null?"": " of " + pathName)
+ " is exceeded: quota = " + quota
+ " B = " + long2String(quota, "B", 2)
+ " but diskspace consumed = " + count
+ " B = " + long2String(count, "B", 2);
} else {
return msg;
}
}
|
搜索该异常的全部调用方如下
——1.DirectoryWithQuotaFeature
- DirectoryWithQuotaFeature#verifyNamespaceQuota
- DirectoryWithQuotaFeature#verifyStoragespaceQuota
——2.DFSOutputStream
- DFSOutputStream#addBlock
- dfsClient.namenode.addBlock
- DFSOutputStream#newStreamForCreate
- dfsClient.namenode.create
——3.DFSClient
DFSClient直接调用NameNode对应的方法,如下
- DFSClient#createSymlink
- DFSClient#callAppend
- DFSOutputStream.newStreamForAppend
- DFSClient#setReplication
- DFSClient#rename
- namenode.rename
- namenode.rename2
- DFSClient#primitiveMkdir
- DFSClient#setQuota
可知,NN在以下情况会做quota校验:
- create
- append
- setReplication
- rename
- mkdirs
- setQuota
其中校验方法为:
- DirectoryWithQuotaFeature#verifyNamespaceQuota
- DirectoryWithQuotaFeature#verifyStoragespaceQuota
static boolean isViolated(final long quota, final long usage,
final long delta) {
return quota >= 0 && delta > 0 && usage > quota - delta;
}
2.SpaceQuota改逻辑空间
1.改动
主要是两方面改动:
- create/mv/setrep等操作时,会判断存储增量(delta),这里将原有的物理空间判断改为逻辑空间判断。其中更新quota的逻辑如下;
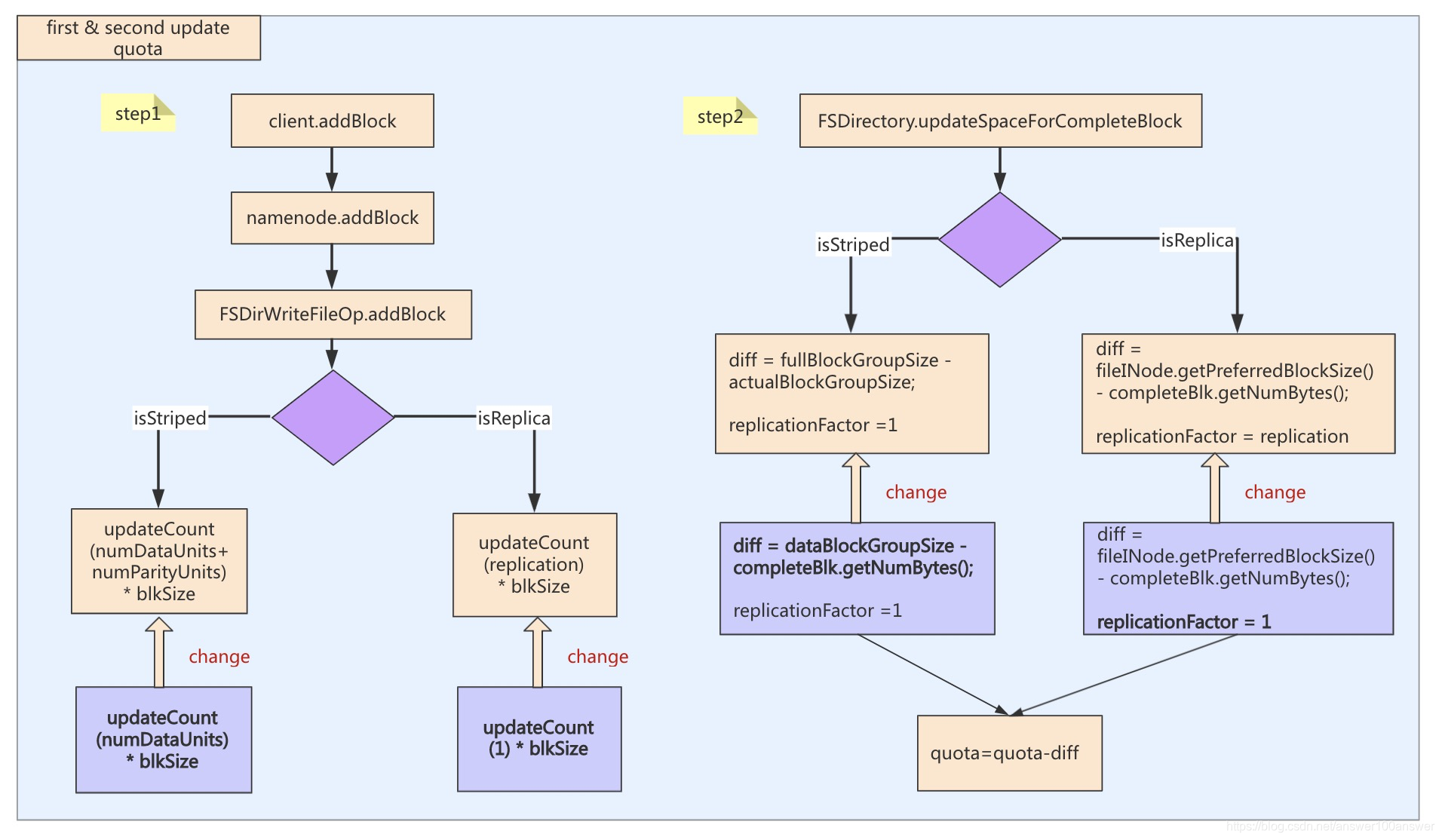
- DirectoryWithQuotaFeature中的usage变量初始化逻辑由物理空间改为逻辑空间。

2.测试
以下为SpaceQuota改成逻辑空间的测试。
|
#新建目录并设quota
[hadoop@cluster-host1 quota]$ hadoop fs -mkdir /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop dfsadmin -setSpaceQuota 1g /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 1 G 1 0 0 /test_quota/quota_1g
#创建100m大小文件
[hadoop@cluster-host1 quota]$ dd if=/dev/zero of=100m bs=1M count=100
#上传文件
[hadoop@cluster-host1 quota]$ hadoop fs -put 100m /test_quota/quota_1g/100m_1
#以-q和-u两种方式查看quota
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 924 M 1 1 100 M /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop fs -count -u -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA PATHNAME
none inf 1 G 924 M /test_quota/quota_1g
#上传第二个
[hadoop@cluster-host1 quota]$ hadoop fs -put 100m /test_quota/quota_1g/100m_2
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 824 M 1 2 200 M /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop fs -count -u -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA PATHNAME
none inf 1 G 824 M /test_quota/quota_1g
#上传中间几个文件,命令省略
[hadoop@cluster-host1 quota]$ hadoop fs -put 100m /quota_1g/100m_8
[hadoop@cluster-host1 quota]$ hadoop fs -put 100m /quota_1g/100m_9
|
put
|
#上传第10个文件出现超额
[hadoop@cluster-host1 quota]$ hadoop fs -put 100m /test_quota/quota_1g/100m_10
put: The DiskSpace quota of /test_quota/quota_1g is exceeded: quota = 1073741824 B = 1 GB but diskspace consumed = 1077936128 B = 1.00 GB
#此时查看quota还剩逻辑空间124M,上传100M文件却出现超额,是因为写数据时要满足最小块大小(测试环境128M)。
#1077936128/1024/1024=1028
#此时查看quota
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 124 M 1 9 900 M /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop fs -count -u -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA PATHNAME
none inf 1 G 124 M /test_quota/quota_1g
|
mv
|
#第一次mv成功,只判断文件大小,不会再判断块
[hadoop@cluster-host1 quota]$ hadoop fs -mv /test/100m /test_quota/quota_1g/100m_10
[hadoop@cluster-host1 quota]$ hadoop fs -count -u -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA PATHNAME
none inf 1 G 24 M /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 24 M 1 10 1000 M /test_quota/quota_1g
#第二次mv失败,需要1100M,但是只有1024M
[hadoop@cluster-host1 quota]$ hadoop fs -mv /test/100m /test_quota/quota_1g/100m_11
mv: The DiskSpace quota of /test_quota/quota_1g is exceeded: quota = 1073741824 B = 1 GB but diskspace consumed = 1153433600 B = 1.07 GB
#1153433600=1100M
|
setrep
|
[hadoop@cluster-host1 quota]$ hadoop fs -setrep 10 /test_quota/quota_1g
Replication 10 set: /test_quota/quota_1g/100m_1
Replication 10 set: /test_quota/quota_1g/100m_10
Replication 10 set: /test_quota/quota_1g/100m_2
Replication 10 set: /test_quota/quota_1g/100m_3
Replication 10 set: /test_quota/quota_1g/100m_4
Replication 10 set: /test_quota/quota_1g/100m_5
Replication 10 set: /test_quota/quota_1g/100m_6
Replication 10 set: /test_quota/quota_1g/100m_7
Replication 10 set: /test_quota/quota_1g/100m_8
Replication 10 set: /test_quota/quota_1g/100m_9
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 24 M 1 10 1000 M /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop fs -count -u -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA PATHNAME
none inf 1 G 24 M /test_quota/quota_1g
# 增加副本数不会受到限制,符合预期
|
du
|
[hadoop@cluster-host1 quota]$ hadoop fs -du -s -h /test_quota/quota_1g
1000 M 9.8 G /test_quota/quota_1g
|
rm
|
[hadoop@cluster-host1 quota]$ hadoop fs -rm /test_quota/quota_1g/100m_10
Deleted /test_quota/quota_1g/100m_10
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 124 M 1 9 900 M /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop fs -count -u -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA PATHNAME
none inf 1 G 124 M /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop fs -rm /test_quota/quota_1g/100m_9
Deleted /test_quota/quota_1g/100m_9
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 224 M 1 8 800 M /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop fs -count -u -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA PATHNAME
none inf 1 G 224 M /test_quota/quota_1g
|
注意:由于重启nn后,quota中的usage会重新计算。在上一版本的测试中发现,重启nn后,使用hadoop fs -count - u查看的剩余量不准(按物理空间量算了)。所以这一部分必须测试。
重启后查看
|
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g
2020-05-20 17:19:22,567 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 224 M 1 8 800 M /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop fs -count -u -v -h /test_quota/quota_1g
2020-05-20 17:19:32,411 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA PATHNAME
none inf 1 G 224 M /test_quota/quota_1g
#正常
|
cp
|
[hadoop@cluster-host1 quota]$ hadoop fs -cp /test/100m /test_quota/quota_1g/100m_9
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g
2020-05-20 17:22:10,908 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 124 M 1 9 900 M /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop fs -count -u -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA PATHNAME
none inf 1 G 124 M /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop fs -cp /test/100m /test_quota/quota_1g/100m_10
cp: The DiskSpace quota of /test_quota/quota_1g is exceeded: quota = 1073741824 B = 1 GB but diskspace consumed = 1077936128 B = 1.00 GB
|
子目录测试
|
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 224 M 1 8 800 M /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop fs -put 100m /test_quota/quota_1g/a/100m_1
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 124 M 2 9 900 M /test_quota/quota_1g
[hadoop@cluster-host1 quota]$ hadoop fs -put 100m /test_quota/quota_1g/a/100m_2
put: The DiskSpace quota of /test_quota/quota_1g is exceeded: quota = 1073741824 B = 1 GB but diskspace consumed = 1077936128 B = 1.00 GB
|
EC测试
|
[hadoop@cluster-host1 quota]$ hadoop dfsadmin -setSpaceQuota 1g /test_quota/quota_1g_2
#设置Ec目录
[hadoop@cluster-host1 quota]$ hdfs ec -setPolicy -path /test_quota/quota_1g_2/ec -policy RS-3-2-1024k
Set RS-3-2-1024k erasure coding policy on /test_quota/quota_1g_2/ec
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g_2
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 1 G 2 0 0 /test_quota/quota_1g_2
#写EC文件
[hadoop@cluster-host1 quota]$ hadoop fs -put 200m /test_quota/quota_1g_2/ec/200m_1
[hadoop@cluster-host1 quota]$ hadoop fs -count -u -v -h /test_quota/quota_1g_2
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA PATHNAME
none inf 1 G 824 M /test_quota/quota_1g_2
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g_2
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 824 M 2 1 200 M /test_quota/quota_1g_2
#写EC文件
[hadoop@cluster-host1 quota]$ hadoop fs -put 200m /test_quota/quota_1g_2/ec/200m_2
[hadoop@cluster-host1 quota]$ hadoop fs -count -q -v -h /test_quota/quota_1g_2
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
none inf 1 G 624 M 2 2 400 M /test_quota/quota_1g_2
[hadoop@cluster-host1 quota]$ hadoop fs -count -u -v -h /test_quota/quota_1g_2
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA PATHNAME
none inf 1 G 624 M /test_quota/quota_1g_2
|
进一步测试
需要对副本、EC文件,小于、等于、大于一个块(块组)的情况进一步测试。
4.可能的问题
1.fsimage中字段无需改动
2.历史quota需要全部找到,在升级版本后,刷成逻辑空间
3.namequota与spacequota的比例
4.quota会按磁盘的type来做精细化限制,内部版本不作考虑。





 本文深入探讨Hadoop中Quota机制的实现细节,包括quota的设置与使用流程,物理空间到逻辑空间的转变,以及各种操作如create、mv、setrep等在不同quota限制下的表现。同时,通过具体测试案例验证了Quota机制的有效性和局限性。
本文深入探讨Hadoop中Quota机制的实现细节,包括quota的设置与使用流程,物理空间到逻辑空间的转变,以及各种操作如create、mv、setrep等在不同quota限制下的表现。同时,通过具体测试案例验证了Quota机制的有效性和局限性。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









