




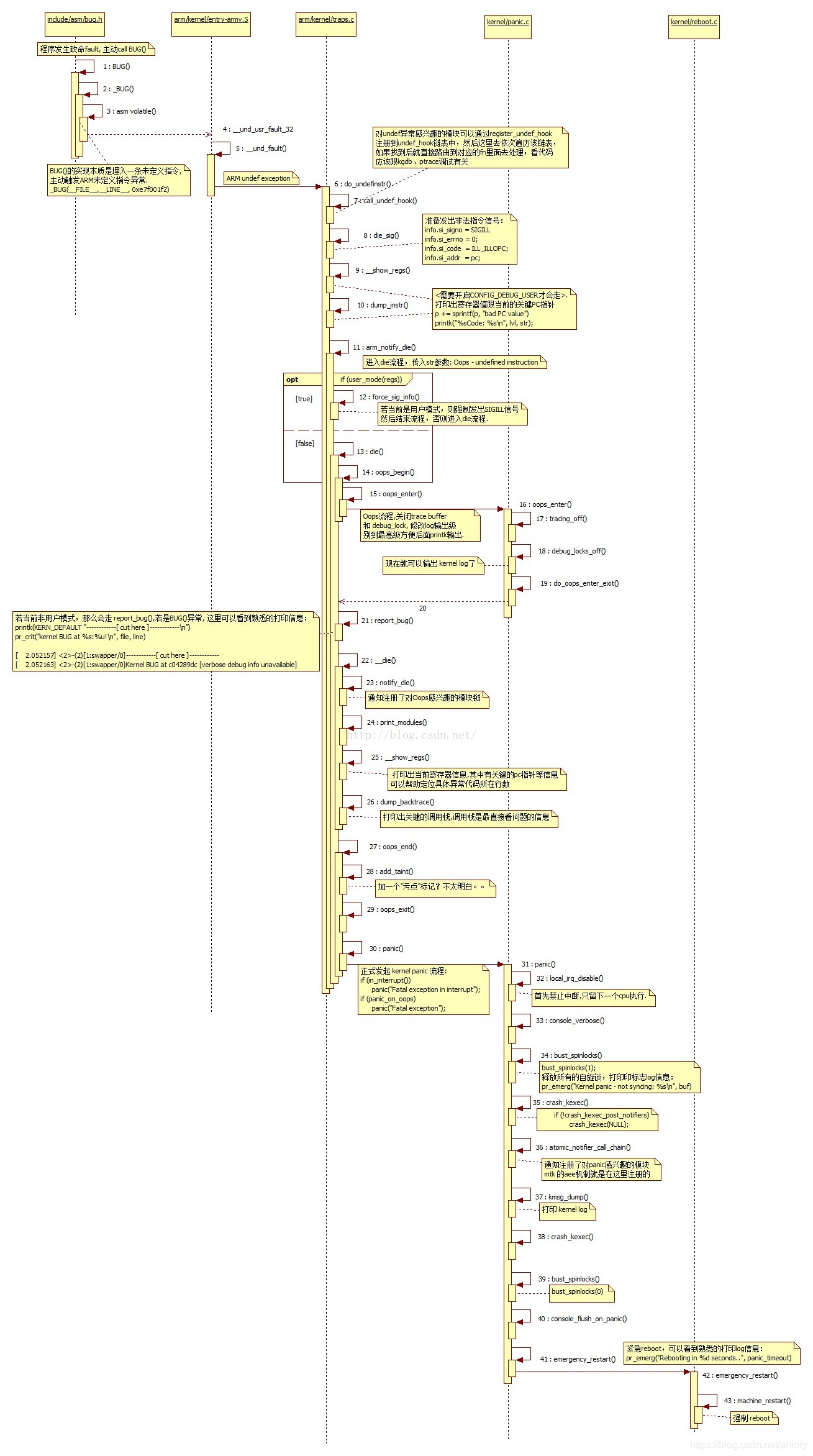
 本文深入探讨Linux内核中的Kernel Panic与Oops现象,解析其触发机制与内核响应过程,包括关中断、打印错误信息、堆栈信息及内核通知链的调用流程。
本文深入探讨Linux内核中的Kernel Panic与Oops现象,解析其触发机制与内核响应过程,包括关中断、打印错误信息、堆栈信息及内核通知链的调用流程。
Kernel Exception 根本原因有两类,
oops
- oops是美国人比较常有的口语。就是有点意外,吃惊,或突然的意思。内核行为表现为通知感兴趣模块,打印各种信息,如寄存器值,堆栈信息…
- 当出现oops时,我们就可以根据寄存器等信息调试并解决问题。
- /proc/sys/kernel/panic_on_oops为1时导致panic。我们默认设置为1,即oops会发生panic。
panic
- Panic – 困惑,恐慌,它表示Linux kernel遇到了一个不知道该怎么继续的情况。内核行为表现为通知感兴趣模块,死机或者重启。
- 在kernel代码里,有些代码加了错误检查,发现错误可能直接调用了panic(),并输出信息提供调试。
在kernel代码里,一般会通过BUG(),BUG_ON(),panic()来拦截超出预期的行为,这是软件主动回报异常的功能。
例如:
if (IS_ERR(clk_cs)) {
pr_err("ERROR: timer input clock not found\n");
BUG();
}
由于BUG_ON调用BUG,原生得BUG直接调用panic
#ifndef HAVE_ARCH_BUG_ON
#define BUG_ON(condition) do { if (unlikely(condition)) BUG(); } while (0)
#endif

下面来只看panic得流程
{
static DEFINE_SPINLOCK(panic_lock);
static char buf[1024];
va_list args;
long i, i_next = 0;
int state = 0;
/*
* Disable local interrupts. This will prevent panic_smp_self_stop
* from deadlocking the first cpu that invokes the panic, since
* there is nothing to prevent an interrupt handler (that runs
* after the panic_lock is acquired) from invoking panic again.
*/
local_irq_disable(); //1. 关中断
/*
* It's possible to come here directly from a panic-assertion and
* not have preempt disabled. Some functions called from here want
* preempt to be disabled. No point enabling it later though...
*
* Only one CPU is allowed to execute the panic code from here. For
* multiple parallel invocations of panic, all other CPUs either
* stop themself or will wait until they are stopped by the 1st CPU
* with smp_send_stop().
*/
if (!spin_trylock(&panic_lock))
panic_smp_self_stop();
console_verbose();
bust_spinlocks(1);
va_start(args, fmt);
vsnprintf(buf, sizeof(buf), fmt, args);
va_end(args);
pr_emerg("Kernel panic - not syncing: %s\n", buf); //打印panic得参数
#ifdef CONFIG_DEBUG_BUGVERBOSE
/*
* Avoid nested stack-dumping if a panic occurs during oops processing
*/
if (!test_taint(TAINT_DIE) && oops_in_progress <= 1)
dump_stack(); //打印堆栈,避免nested crash。
#endif
/*
* If we have crashed and we have a crash kernel loaded let it handle
* everything else.
* If we want to run this after calling panic_notifiers, pass
* the "crash_kexec_post_notifiers" option to the kernel.
*/
if (!crash_kexec_post_notifiers)
crash_kexec(NULL);
/*
* Note smp_send_stop is the usual smp shutdown function, which
* unfortunately means it may not be hardened to work in a panic
* situation.
*/
smp_send_stop();
/*
* Run any panic handlers, including those that might need to
* add information to the kmsg dump output.
*/
atomic_notifier_call_chain(&panic_notifier_list, 0, buf); //内核通知链,通知关注panic得进程,并把panic得参数传递
kmsg_dump(KMSG_DUMP_PANIC); //KMSG dump
/*
* If you doubt kdump always works fine in any situation,
* "crash_kexec_post_notifiers" offers you a chance to run
* panic_notifiers and dumping kmsg before kdump.
* Note: since some panic_notifiers can make crashed kernel
* more unstable, it can increase risks of the kdump failure too.
*/
if (crash_kexec_post_notifiers)
crash_kexec(NULL);
bust_spinlocks(0);
/*
* We may have ended up stopping the CPU holding the lock (in
* smp_send_stop()) while still having some valuable data in the console
* buffer. Try to acquire the lock then release it regardless of the
* result. The release will also print the buffers out. Locks debug
* should be disabled to avoid reporting bad unlock balance when
* panic() is not being callled from OOPS.
*/
debug_locks_off();
console_flush_on_panic();
if (!panic_blink)
panic_blink = no_blink;
if (panic_timeout > 0) {
/*
* Delay timeout seconds before rebooting the machine.
* We can't use the "normal" timers since we just panicked.
*/
pr_emerg("Rebooting in %d seconds..\n", panic_timeout);
for (i = 0; i < panic_timeout * 1000; i += PANIC_TIMER_STEP) {
touch_nmi_watchdog();
if (i >= i_next) {
i += panic_blink(state ^= 1);
i_next = i + 3600 / PANIC_BLINK_SPD;
}
mdelay(PANIC_TIMER_STEP);
}
}
if (panic_timeout != 0) {
/*
* This will not be a clean reboot, with everything
* shutting down. But if there is a chance of
* rebooting the system it will be rebooted.
*/
emergency_restart();
}
#ifdef __sparc__
{
extern int stop_a_enabled;
/* Make sure the user can actually press Stop-A (L1-A) */
stop_a_enabled = 1;
pr_emerg("Press Stop-A (L1-A) to return to the boot prom\n");
}
#endif
#if defined(CONFIG_S390)
{
unsigned long caller;
caller = (unsigned long)__builtin_return_address(0);
disabled_wait(caller);
}
#endif
pr_emerg("---[ end Kernel panic - not syncing: %s\n", buf);
local_irq_enable();
for (i = 0; ; i += PANIC_TIMER_STEP) {
touch_softlockup_watchdog();
if (i >= i_next) {
i += panic_blink(state ^= 1);
i_next = i + 3600 / PANIC_BLINK_SPD;
}
mdelay(PANIC_TIMER_STEP);
}
}
流程图:

















 1654
1654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









