




迟滞比机器
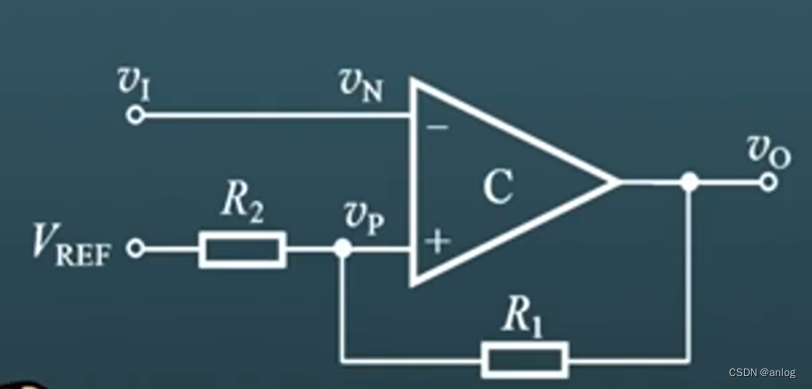
仿真电路
【免费】迟滞比较器仿真电路,2024年5月18日资源-优快云文库 https://download.youkuaiyun.com/download/anlog/89323116如下图:
https://download.youkuaiyun.com/download/anlog/89323116如下图:
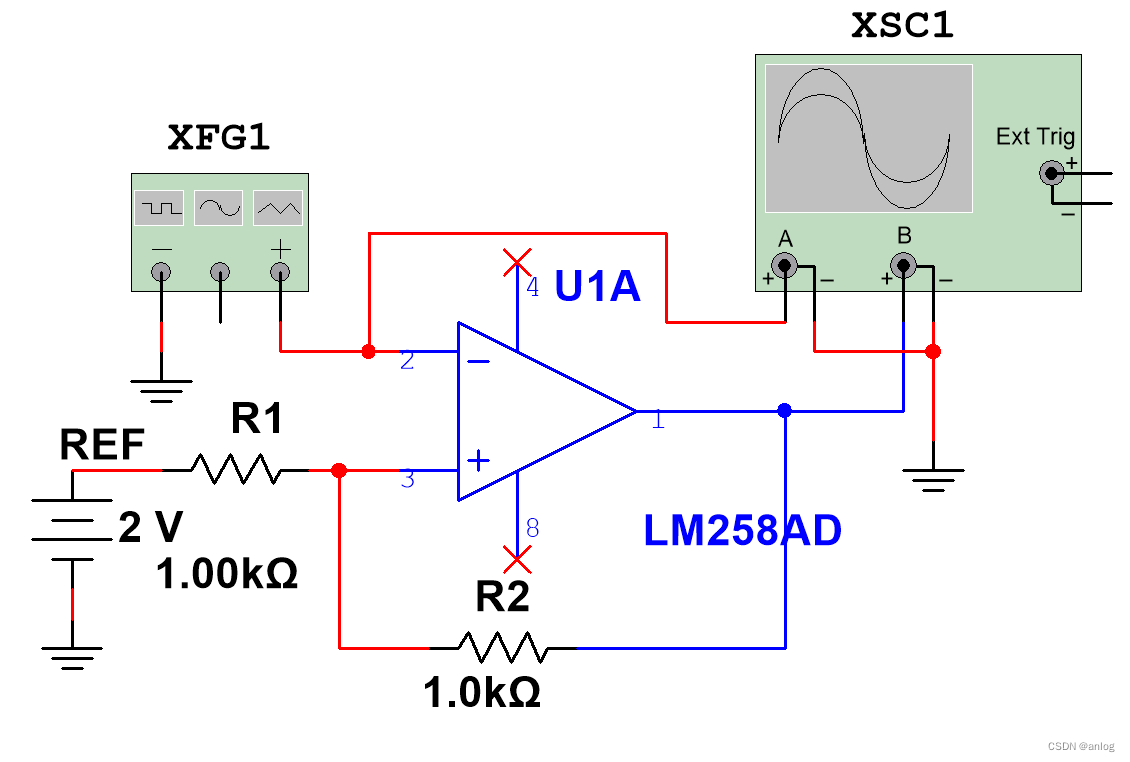
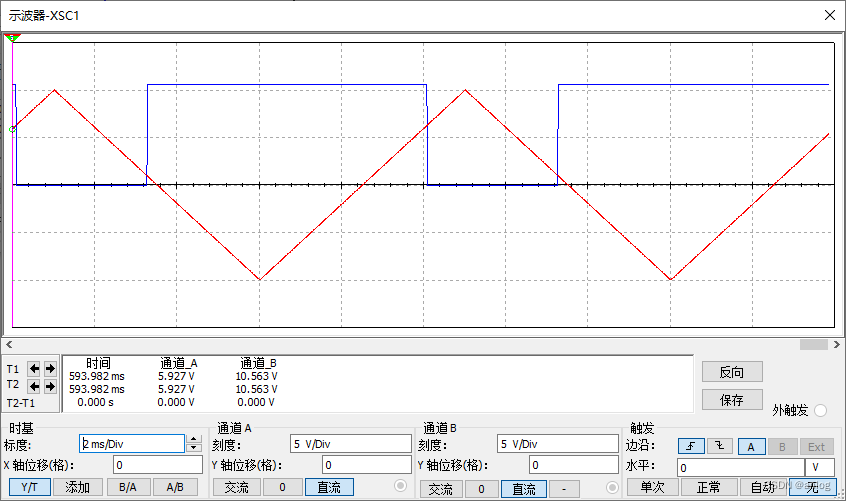
运行结果
参考链接:
迟滞比较器仿真-优快云博客https://blog.youkuaiyun.com/anlog/article/details/126116037
迟滞比较器_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1CD421T78C/?spm_id_from=333.788.top_right_bar_window_history.content.click&vd_source=e821a225c7ba4a7b85e5aa6d013ac92e 聊聊运算放大器---施密特与迟滞比较器_施密特触发器和滞回比较器区别-优快云博客https://blog.youkuaiyun.com/daxing198612/article/details/123424469
迟滞比较器仿真-优快云博客https://blog.youkuaiyun.com/anlog/article/details/126116037
特此记录
anlog
2024年5月18日

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









