




 该论文提出了一种通过深度强化学习(DRL)框架改进代码自动摘要的方法,结合了词法和语法级别的代码表示,利用混合注意力层和actor-critic网络,以生成准确、流畅和一致的代码注释。实验表明,该模型在与基线模型的比较中表现出优越性能。
该论文提出了一种通过深度强化学习(DRL)框架改进代码自动摘要的方法,结合了词法和语法级别的代码表示,利用混合注意力层和actor-critic网络,以生成准确、流畅和一致的代码注释。实验表明,该模型在与基线模型的比较中表现出优越性能。
Improving Automatic Source Code Summarization via Deep Reinforcement Learning
1 本文背景
软件维护占据软件开发生命周期很大一部分,提供代码执行任务的描述对于软件维护来说是必须的,然而注释代码仍然是一项劳动密集型的任务,使得真实的软件项目很少具备充分的代码文档以减少未来的维护成本。
本文作者提出:一个好的注释论至少应该具备以下特征: a)正确性:正确地阐明代码的意图。b)流利:流畅的自然语言,易于维护者阅读和理解。c)一致性:遵循标准的样式/格式。
代码摘要是一项试图理解代码并直接从源代码自动生成描述的任务。
本文将一个抽象语法树结构以及代码片段的顺序内容合并到一个深度强化学习(DRL)框架中(具体: actor-critic网络)。
2 模型架构
2.1 总体工作流程
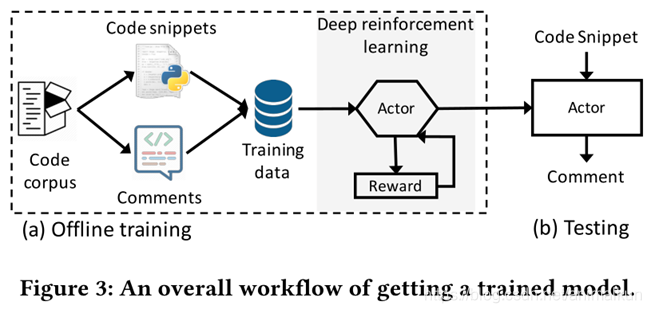
a) 离线培训阶段
语料库 → < code,comment> → 深度强化学习模型→ actor network
b) 在线总结阶段
给定一个代码片段,注释经过训练后的actor network生成。
2.2 模型具体框架
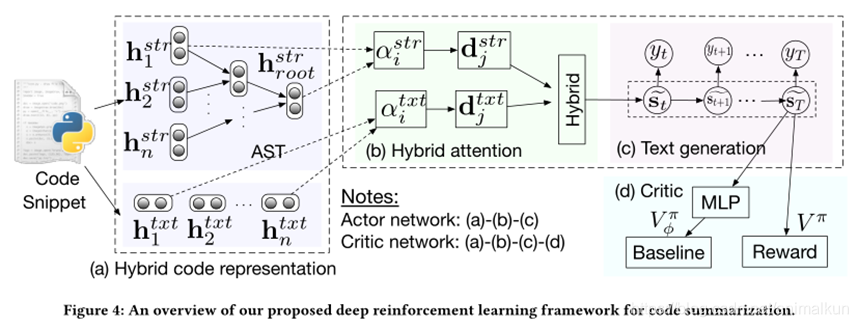 a) 混合代码表示:将源代码表示为隐藏空间,即编码器。
a) 混合代码表示:将源代码表示为隐藏空间,即编码器。
b) 混合注意力层:在将已编码的隐藏空间译码到注释空间时,利用注意力层对代码片段的token分配不同的权重,以便更好地进行生成。
c) 文本生成:RNN生成网络,根据当前生成的单词生成下一个单词。
d) critic:评估生成词的好坏。
a) 混合代码表示
这一层使用LSTM来表示代码的词法,使用基于AST的LSTM来表示代码的语法。
词法级表示
源代码的词法级表示的关键:注释总是从代码的词法中提取,比如函数名、变量名等等。本文使用LSTM来表示源代码的序列信息。
语法级表示
AST作为一种中间代码,表示程序的层次语法结构。本文从AST嵌入的角度,提出一个基于AST的LSTM来表示源代码的语法层次,公式如下所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1834
1834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









