






Seaborn是基于matplotlib的图形可视化python包。Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。
Matplotlib的API是按照图形的种类进行设计的,比如直方图、散点图等等; 而Seaborn不同,它的绘图API的设计初衷是为了更好的展示数据之间的关系,我们查看Seaborn的官方文档就能很直观的发现这一点。
Seaborn的官方文档和版本号API文档 https://seaborn.pydata.org/api.html
历史版本API文档 https://seaborn.pydata.org/archive.html
数据可视化—— seaborn
-
需要画图的场景
-
对外要做数据分析报告, 做文档, 为了直观的向听众、客户、同事说明自己的观点,可以在输出结论的时候配上图表
-
对自己来说, 如果业务不是很熟悉, 想快速的找到数据之间的规律,可以画图
-
-
seaborn 和 matplotlib ,pandas 的区别 和联系
-
seaborn是基于matplotlib 的,是对matplotlib 绘图的封装, 对pandas 的df支持的也很好
-
区别:
-
seaborn 的某些绘图方法, 先做了一些统计的计算, 再画图
-
seaborn 的 API 套路
-
import seaborn as sns
-
sns.XXXplot(data = 绘图要使用的dataframe对象, x = '列名', y =‘列名’ )
-
-
-
1.1 散点图
seaborn绘制散点图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
tips_df = pd.read_csv('C:/Develop/顺义48/day01/02_代码/data/tips.csv')
# 使用小费的数据
tips_df['sex'].value_counts()
# 查看性别列取值情况
tips_df['smoker'].value_counts()
# 查看是否抽烟这一列 数据取值情况
tips_df['time'].value_counts()
# 查看用餐时间这一列 数据取值情况 dinner 晚餐 lunch 午餐
tips_df['size'].value_counts()
# 用餐人数 1-6
plt.figure(figsize=(16,10))
sns.scatterplot(x='total_bill', y='tip', data=tips_df)
plt.show()
#plt.figure(figsize=(16,10)) seaborn绘图区域的大小会发生变化, 说明seaborn画图还是使用了matplotlib
sns.scatterplot(x='total_bill', y='tip', data=tips_df,hue='sex',style='smoker',size='time')
plt.show()
seaborn api 通用的几个参数
data 数据对应的df
x,y 传入df中的列名
hue 通过这个参数传入一个类别型变量, 会自动区分颜色,画图
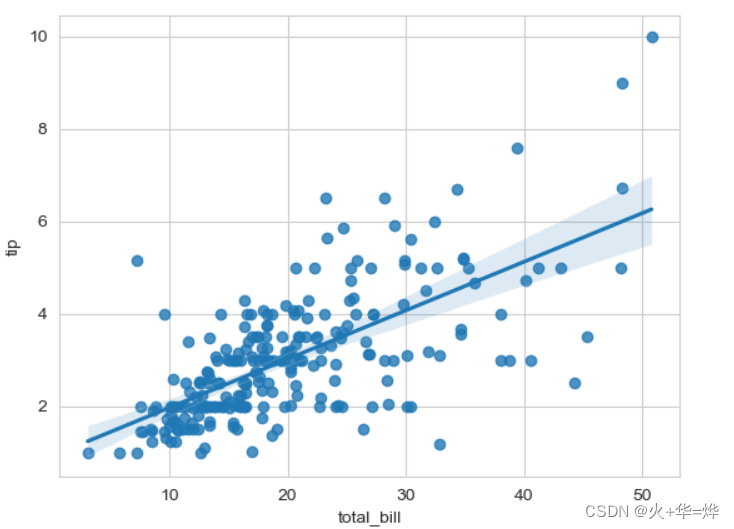
关系散点图
sns.regplot(data=tips_df,x='total_bill',y='tip')
分类散点图
f = plt.figure() f.add_subplot(2,1,1) # 按照x属性所对应的类别分别展示y属性的值,适用于分类数据 # 不同饭点的账单总金额的散点图 sns.stripplot(data=tips_df, x='time', y='total_bill') f.add_subplot(2,1,2) # hue通用参数按颜色划分 # jitter=True 当数据点重合较多时,尽量分散的展示数据点 # dodge=True 拆分分类 sns.stripplot(data=tips_df, x='time', y='total_bill', jitter=True, dodge=True, hue='day') plt.show()
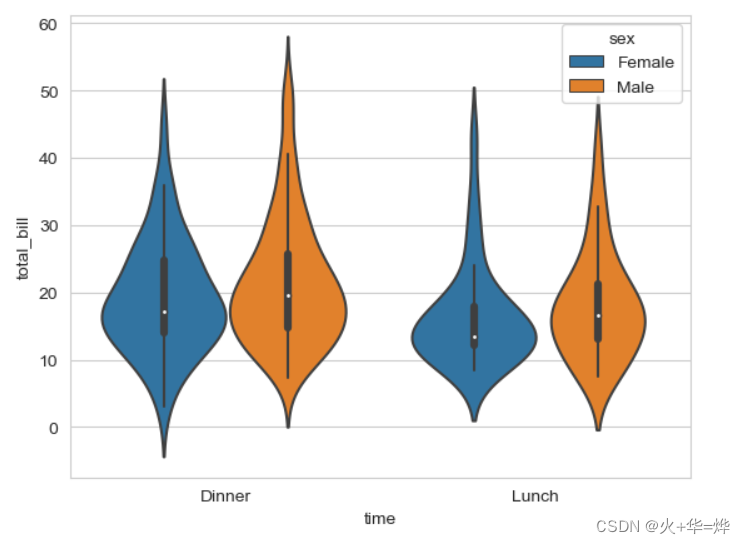
1.2 提琴图
sns.violinplot(data=tips_df, x='time', y='total_bill',hue='sex')
作用和箱线图类似, 比箱线图多显示出数据的整体分布情况, 突出的部分说明样本分布的比较多
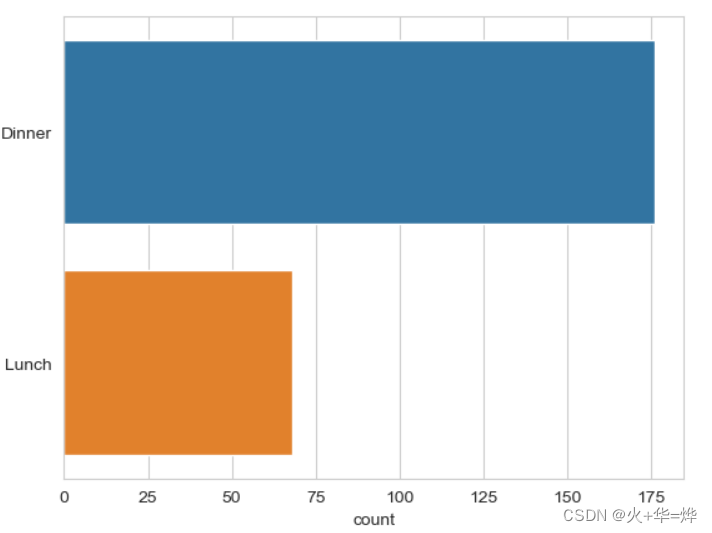
1.3 柱状图
sns.countplot(data=tips_df, y='time')
sns.countplot(data=tips_df, x='time') # 绘制竖直的柱状图
相当于先对time计数,再画柱状图
tips_df['time'].value_counts().plot.bar()
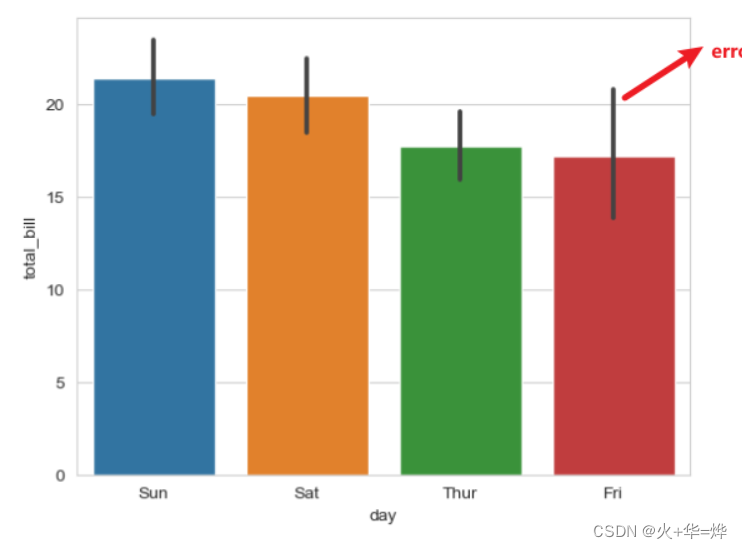
sns.barplot(data=tips_df, x='day', y='total_bill',estimator='mean',errorbar=None)
estimator 默认是mean 对x进行分组, 对y计算平均 可以换其它的聚合方法比如sum max min
tips_df.groupby(['day'])['total_bill'].mean().sort_values(ascending=False).plo1t.bar(),errorbar=None 可以关闭, 默认柱子上会有一个误差棒, 黑色的线
如果数据是从海量数据中采样出来的, 使用采样的数来估计海量样本的整体情况,这个时候errorbar 显示了这个统计量可能得分布范围,
1.4 热力图
最常用的使用场景, 对相关性进行可视化
sns.heatmap(tips_df.corr())
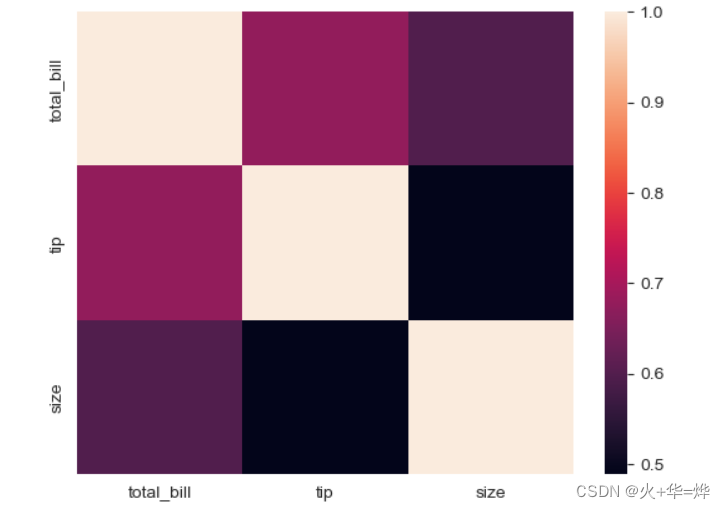
1.5 成对关系图
一张图中表示多个变量(数值型)之间的两两关系
sns.pairplot(tips_df)
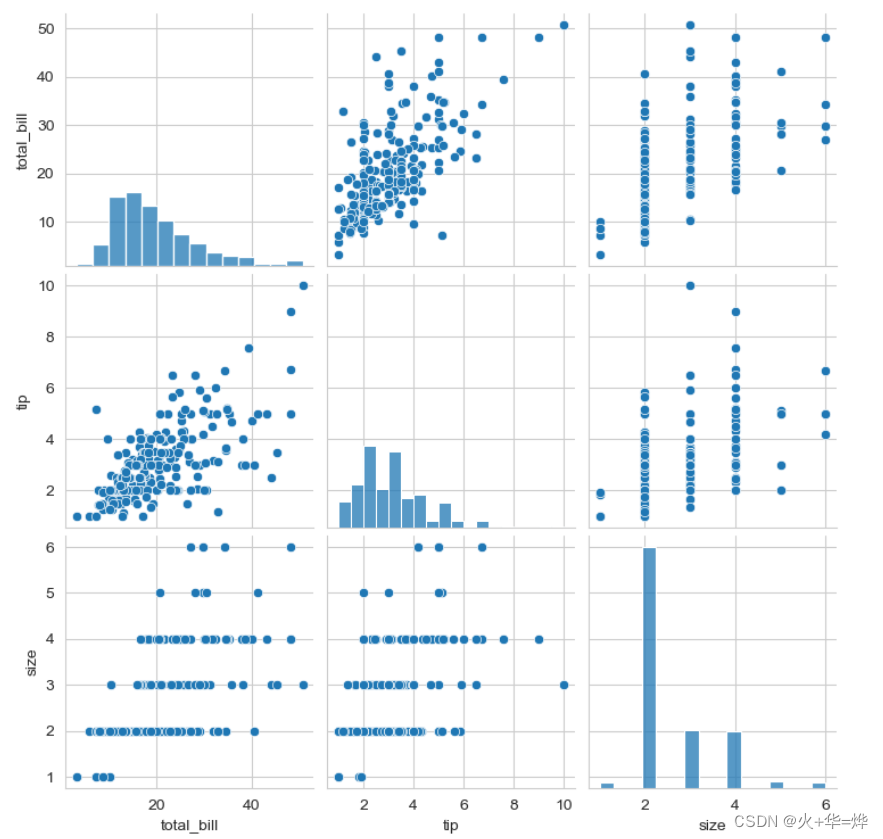
可以通过PairGrid 来控制成对关系图不同位置使用哪种API来绘图
pair_grid = sns.PairGrid(tips_df) pair_grid.map_upper(sns.kdeplot) # 设置 成对关系图, 右上角的部分使用的绘图方法 pair_grid.map_diag(sns.histplot) # 设置 成对关系图, 对角线的部分使用的绘图方法 pair_grid.map_lower(sns.scatterplot) # 设置 成对关系图, 左下角的部分使用的绘图方法
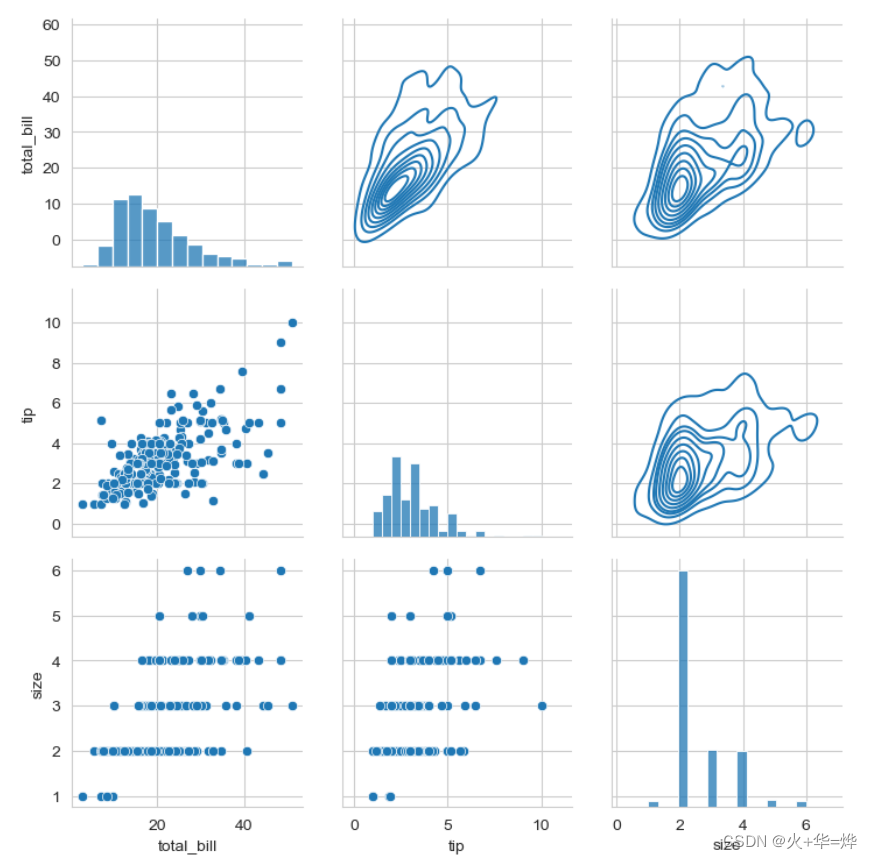
1.5 通用样式配置
sns.set(
context='paper',
style='darkgrid',
palette='muted',
font='sans-serif',
font_scale=1
)
plt.figure(figsize=(16,10))
# context: 参数控制着默认的画幅大小,分别有 {paper, notebook, talk, poster} 四个值。其中,poster > talk > notebook > paper。
# style:参数控制默认样式,分别有 {darkgrid, whitegrid, dark, white, ticks},你可以自行更改查看它们之间的不同。
# palette:参数为预设的调色板。分别有 {deep, muted, bright, pastel, dark, colorblind} 等,你可以自行更改查看它们之间的不同。
# font:用于设置字体
# font_scale:设置字体大小
sns.scatterplot(data=tips_df, x='total_bill', y='tip', hue='sex', style='smoker', size='time')
plt.show()
2 数据分析业务
2.1 重要指标
活跃: DAU、MAU 日活月活
留存: 次留、七留 通过这个指标可以考察渠道
转化率、转发率:
-
点击转化率 点击次数/展示次数
-
电商转化率 购买人数/进店的人数
-
转发率 : 好多运营是以转发为最终目标的, 转发的人数/访问人数
GMV 总交易金额
PV/UV 网站时代留下来的流量指标 PV点击 UV 独立访客数
广告费用
-
CPM 千次展示首费
-
CPC 点击 点一次收一次钱
2.2 数据分析思维模型介绍
电商黄金公式
销售额 = 访客数 * 转化率 * 客单价
GROW
阿里AIPL, 字节5A模型 京东4A模型
-
使用这些思维模型,把用户划分成不同的阶段, 从刚注册 → 成为忠实用户
-
可以考察不同时间 处于不同阶段的用户量
-
考核 处于每个阶段用户数量的转化率
-
利用模型 进行目标拆解和追踪
3 Excel自动化报表
当数据在很多excel文件中保存, 每张表处理逻辑类似,或者数据在多张表保存, 固定的操作逻辑经常要重复进行, 这样的场景就适合用Pandas的代码把整个过程自动化, 优势:
-
代码写好了之后, 再有类似的需求只需要运行一下代码就可以搞定
-
出错的概率很低的
如果需求是处理很多不同的表格,每张表处理的逻辑一样, 先把一张表处理的逻辑的代码写好, 再遍历所有的Excel文件, 重复执行相同的逻辑
import pandas as pd
name = '睡袋&睡袋.xlsx'
data_dir = 'C:/Develop/顺义48/day01/02_代码/data/report/'
df = pd.read_excel(data_dir + name,parse_dates=[0])
df.info()
df.head()
df.describe()
# 上面几行就是了解数据的分布情况
# 提取2023年的数据
df['年份'] = df['日期'].dt.year
df_2023 = df[df['年份']==2023]
# 计算销售额
df_2023['销售额'] = df_2023['访客数']*df_2023['转化率']*df_2023['客单价']
# 计算每个品牌在2023年的销售额
pd.set_option('display.float_format', lambda x: '%.2f' % x)
df_sum = df_2023.groupby('品牌')['销售额'].sum().reset_index()
#%%
# name = '睡袋&睡袋.xlsx'
df_sum['行业'] = name.replace('.xlsx','')
df_sum.head()
把上面的代码应用到整个文件夹,
import os
result_df = pd.DataFrame() # 创建一个空白的DF 用来保存结果
for name in os.listdir(data_dir):
df = pd.read_excel(data_dir + name,parse_dates=[0])
# 提取2023年的数据
df['年份'] = df['日期'].dt.year
df_2023 = df[df['年份']==2023]
# 计算销售额
df_2023['销售额'] = df_2023['访客数']*df_2023['转化率']*df_2023['客单价']
# 统计每个品牌的全年销售额
df_sum = df_2023.groupby('品牌')['销售额'].sum().reset_index()
# name = '睡袋&睡袋.xlsx'
df_sum['行业'] = name.replace('.xlsx','')
result_df = pd.concat([result_df, df_sum])
result_df.groupby('品牌')['销售额'].sum().reset_index().sort_values('销售额',ascending= False).head()
os.listdir(data_dir)
传入一个目录的路径, 返回这个目录下的所有文件,通过一个列表返回
把在notebook中的代码, 移到.py文件里, 再有类似的需求, 直接运行这个.py文件, 就可以了
4 广告效果分析
4.1 漏斗分析
什么时候用:业务流程相对规范、周期较长、环节较多
怎么用: 对于电商业务来说
-
计算每个阶段的转化率,漏斗环节中, 后一个阶段的人数/前一个阶段人数
-
搜索打开转化率 搜索人数/打开应用人数
-
搜索列表→详情转化 打开详情页人数/ 搜索人数
-
-
计算整体的转化率 购买的人数/访客数
漏斗分析的作用
-
当最关心的目标, 比如电商GMV 有波动的时候, 能够快速定位哪个环节有异常
-
做不同人群漏斗的对比, 找到针对不同人群问题

















 1969
1969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









