




 本文深入解析决策树模型,包括ID3、C4.5、CART的原理与区别,探讨了随机森林、GBDT及XGBoost的构建与优化策略,详细阐述了各类模型在分类与回归任务中的应用。
本文深入解析决策树模型,包括ID3、C4.5、CART的原理与区别,探讨了随机森林、GBDT及XGBoost的构建与优化策略,详细阐述了各类模型在分类与回归任务中的应用。
决策树
决策树是一个有监督的分类模型,其本质是选择一个能带来最大信息增益的特征值进行树的分割,直到到达结束条件或者叶子结点纯度到达一定阈值。
按照分割指标和分割方法,决策树的经典模型可以分为ID3、C4.5以及CART
ID3:以信息增益为准则来选择最优划分属性
信息增益的计算要基于信息熵(度量样本集合纯度的指标)
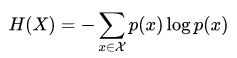
信息熵越小,数据集X的纯度越大
因此,假设于数据集D上建立决策树,数据有K个类别:

公式(1)中:
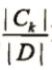
表示第k类样本的数据占数据集D样本总数的比例
公式(2)表示的是以特征A作为分割的属性,得到的信息熵:
Di表示的是以属性A为划分,分成n个分支,第i个分支的节点集合
因此,该公式求的是以属性A为划分,n个分支的信息熵总和
公式(3)为分割后与分割前的信息熵的差值,也就是信息增益,越大越好
但是这种分割算法存在一定的缺陷:
假设每个记录有一个属性“ID”,若按照ID来进行分割的话,由于ID是唯一的,因此在这一个属性上,能够取得的特征值等于样本的数目,也就是说ID的特征值很多。那么无论以哪个ID为划分,叶子结点的值只会有一个,纯度很大,得到的信息增益会很大,但这样划分出来的决策树是没意义的。由此可见,ID3决策树偏向于取值较多的属性进行分割,存在一定的偏好。为减小这一影响,有学者提出C4.5的分类算法。
C4.5:基于信息增益率准则选择最优分割属性的算法
信息增益比率通过引入一个被称作分裂信息(Split information)的项来惩罚取值较多的属性。
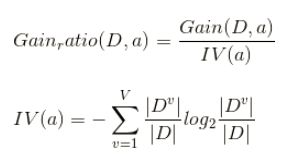
上式,分子计算与ID3一样,分母是由属性A的特征值个数决定的,个数越多,IV值越大,信息增益率越小,这样就可以避免模型偏好特征值多的属性,但是聪明的人一看就会发现,如果简单的按照这个规则来分割,模型又会偏向特征数少的特征。因此C4.5决策树先从候选划分属性中找出信息增益高于平均水平的属性,在从中选择增益率最高的。
对于连续值属性来说,可取值数目不再有限,因此可以采用离散化技术(如二分法)进行处理。将属性值从小到大排序,然后选择中间值作为分割点,数值比它小的点被划分到左子树,数值不小于它的点被分到又子树,计算分割的信息增益率,选择信息增益率最大的属性值进行分割。
CART:以基尼系数为准则选择最优划分属性,可以应用于分类和回归
CART是一棵二叉树,采用二元切分法,每次把数据切成两份,分别进入左子树、右子树。而且每个非叶子节点都有两个孩子,所以CART的叶子节点比非叶子多1。相比ID3和C4.5,CART应用要多一些,既可以用于分类也可以用于回归。CART分类时,使用基尼指数(Gini)来选择最好的数据分割的特征,gini描述的是纯度,与信息熵的含义相似。CART中每一次迭代都会降低GINI系数。
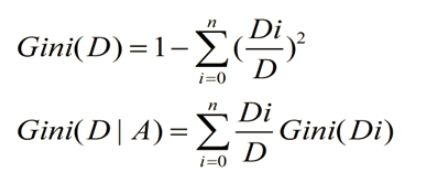
Gini(D)反映了数据集D的纯度,值越小,纯度越高。我们在候选集合中选择使得划分后基尼指数最小的属性作为最优化分属性。
CART
分类树和回归树
提到决策树算法,很多想到的就是上面提到的ID3、C4.5、CART分类决策树。其实决策树分为分类树和回归树,前者用于分类,如晴天/阴天/雨天、用户性别、邮件是否是垃圾邮件,后者用于预测实数值,如明天的温度、用户的年龄等。
作为对比,先说分类树,我们知道ID3、C4.5分类树在每次分枝时,是穷举每一个特征属性的每一个阈值,找到使得按照feature<=阈值,和feature>阈值分成的两个分枝的熵最大的feature和阈值。按照该标准分枝得到两个新节点,用同样方法继续分枝直到所有人都被分入性别唯一的叶子节点,或达到预设的终止条件,若最终叶子节点中的性别不唯一,则以多数人的性别作为该叶子节点的性别。
回归树总体流程也是类似,不过在每个节点(不一定是叶子节点)都会得一个预测值,以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是最大熵,而是最小化均方差–即(每个人的年龄-预测年龄)^2 的总和 / N,或者说是每个人的预测误差平方和 除以 N。这很好理解,被预测出错的人数越多,错的越离谱,均方差就越大,通过最小化均方差能够找到最靠谱的分枝依据。分枝直到每个叶子节点上人的年龄都唯一(这太难了)或者达到预设的终止条件(如叶子个数上限),若最终叶子节点上人的年龄不唯一,则以该节点上所有人的平均年龄做为该叶子节点的预测年龄。
随机森林
组合分类器的概念,将多个分类器的结果进行多票表决或者是取平均值,以此作为最终的结果。
构建组合分类器的好处:
- 提升模型精度:整合各个模型的分类结果,得到更合理的决策边界,减少整体错误,实现更好的分类效果;
- 处理过大或过小的数据集:数据集较大时,可以将数据集划分成多个子集,对子集构建分类器;数据集较小时,可通过多种抽样方式(bootstrap)从原始数据集抽样产生多组不同的数据集,构建分类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









