




 本文深入探讨了GBDT算法的原理,包括其背后的数学理论、梯度提升思想以及与Adaboost的区别。通过实例展示了GBDT在回归和分类任务中的应用,并比较了GBDT、Xgboost和LightGBM三种模型的性能。此外,还提供了基于Mnist数据集的代码实现,以及LightGBM在饭店流量预测中的实际案例。
本文深入探讨了GBDT算法的原理,包括其背后的数学理论、梯度提升思想以及与Adaboost的区别。通过实例展示了GBDT在回归和分类任务中的应用,并比较了GBDT、Xgboost和LightGBM三种模型的性能。此外,还提供了基于Mnist数据集的代码实现,以及LightGBM在饭店流量预测中的实际案例。
Gradient Boosting
以梯度为优化目标,以提升将整个架构串在一起,用决策树当做模型细节中的每一个小部分
分类回归树(CART)
数据集: { ( ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) ) ) } \begin{Bmatrix} ((x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),...,(x^{(m)},y^{(m)})) \end{Bmatrix} { ((x(1),y(1)),(x(2),y(2)),...,(x(m),y(m)))}
衡量标准:
s 2 ⋅ m = ( y ( 1 l e f t ) − y ˉ l e f t ) 2 + . . . + ( y ( n l e f t ) − y ˉ l e f t ) 2 + ( y ( 1 r i g h t ) − y ˉ r i g h t ) 2 + . . . + ( y ( m − n l e f t ) − y ˉ r i g h t ) 2 s^2 \cdot m= (y^{(1_{left})}-\bar{y}_{left})^2+...+(y^{(n_{left})}-\bar{y}_{left})^2+(y^{(1_{right})}-\bar{y}_{right})^2+...+(y^{(m-n_{left})}-\bar{y}_{right})^2 s2⋅m=(y(1left)−yˉleft)2+...+(y(nleft)−yˉleft)2+(y(1right)−yˉright)2+...+(y(m−nleft)−yˉright)2
Adaboost算法概述
原数据集:
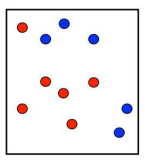
第一次划分:
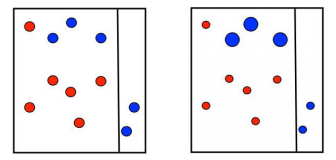
在第一次划分完成后,对于分类正确的数据降低权重,分类错误的值增加权重
第二次划分:
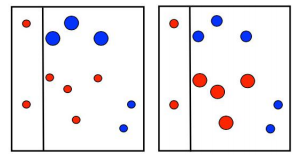
在第二次划分完成后,同样是对于分类正确的数据降低权重,分类错误的值增加权重
第三次划分:
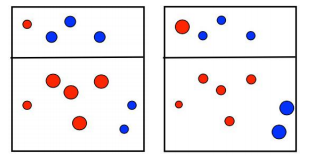
在第三次划分完成后,同样是做权重调整工作
最终,对三次分类进行整合,不同的分类精度对应不同的 α \alpha α 权重,将其加和得到最后结果
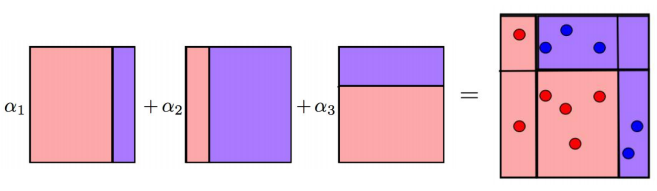
GB算法
优化的目标:
a r g m i n f ( x ) E x , y [ L ( y , f ( x ) ) ] \underset{f(x)}{arg min}E_{x,y}[L(y,f(x))] f(x)argminEx,y[L(y,f(x))]
L ( y , f ( x ) ) L(y,f(x)) L(y,f(x))是一个损失函数, f ( x ) f(x) f(x) 是一个模型,我们需要找到一个模型 f ( x ) f(x) f(x) 使得损失函数最小
其实目标还是去找最合适的参数:
θ ^ = a r g m i n θ E x , y [ L ( y , f ( x , θ ) ) ] \hat{\theta} =\underset{\theta }{arg min}E_{x,y}[L(y,f(x,\theta ))] θ^=θargminEx,y[L(y,f(x,θ))]
结果依旧是需要迭代得出:
θ ^ = ∑ i = 1 M θ ^ i \hat{\theta} = \sum_{i=1}^{M}\hat{\theta}_i θ^=i=1∑Mθ^i
梯度的思想
找到最合适的参数:
( ρ t , θ t ) = a r g m i n ρ , θ E x , y [ L ( y , f ^ ( x ) + ρ ⋅ h ( x , θ ) ) ] (\rho _t,\theta _t)=\underset{\rho ,\theta }{argmin}E_{x,y}[L(y,\hat{f}(x )+\rho \cdot h(x,\theta))] (ρt,θt)=ρ,θargminEx,y[L(y,f^(x)+ρ⋅h(x,θ))]
残差的计算(负梯度):
r i t = − [ ∂ L ( y , f ( x i ) ) ∂ f ( x i ) ] f ( x i ) = f ^ ( x ) r_{it}=-[\frac{\partial L(y,f(x_i))}{\partial f(x_i)}]_{f(x_i)=\hat{f}(x )} rit=−[∂f(xi)∂L(y,f(xi))]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









