







 本文深入讲解了决策树算法,包括ID3、C4.5和CART,并介绍了集成学习的基本概念和方法,如随机森林、Bagging、Boosting以及AdaBoost。特别是,文章详细阐述了GBDT(梯度提升决策树)的工作原理、优缺点和XGBoost的改进,如损失函数的二阶导数使用和正则化项。此外,还提及了LightGBM在处理类别特征上的优势。
本文深入讲解了决策树算法,包括ID3、C4.5和CART,并介绍了集成学习的基本概念和方法,如随机森林、Bagging、Boosting以及AdaBoost。特别是,文章详细阐述了GBDT(梯度提升决策树)的工作原理、优缺点和XGBoost的改进,如损失函数的二阶导数使用和正则化项。此外,还提及了LightGBM在处理类别特征上的优势。
信息熵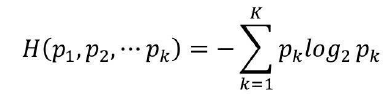
经验信息熵
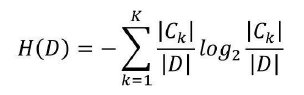
条件熵
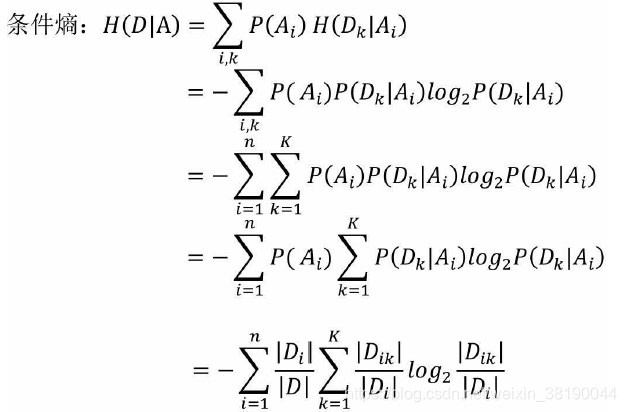
信息增益
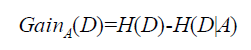
1 ID3
ID3算法使用信息增益指标实现根节点或中间节点的字段选择,那个属性的信息增益大,选择那个属性作为分隔的节点,但是该指标存在一个非常明显的缺点,即信息增益会偏向于取值较多的字段。
2 C4.5算法
信息增益率,C4.5使用
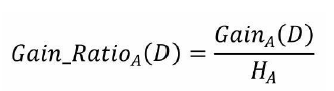
HA参考
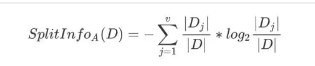
就是在信息增益的基础上进行相应的惩罚。其中,HA为事件A的信息熵。事件A的取值越多,GainA(D)可能越大,但同时HA也会越大,这样以商的形式就实现了GainA(D)的惩罚。
3 CART算法

条件基尼指数的计算公式可以表示为:
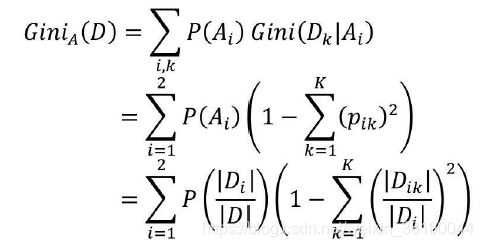
决策树中的C4.5算法使用信息增益率指标实现根节点或中间节点的字段选择,但该算法与ID3算法一致,都只能针对离散型因变量进行分类,对于连续型的因变量就显得束手无策了。为了能够让决策树预测连续型的因变量,Breiman等人在1984提出了CART算法,该算法也称为分类回归树。
集成
集成学习
根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类?即个体学习器问存在强依赖关系、必须串行生成的序列化方法?以及个体学习器间不存在强依赖关系、可同时生成的并行化方法;前者的代表是 Boosting,后者的代表是 Bagging 和"随机森林" (Random Forest)。
常见的集成学习框架有三种:Bagging,Boosting 和 Stacking。三种集成学习框架在基学习器的产生和综合结果的方式上会有些区别,我们先做些简单的介绍。
Bagging 和 Stacking 中的基模型为强模型(偏差低,方差高),而Boosting 中的基模型为弱模型(偏差高,方差低)。
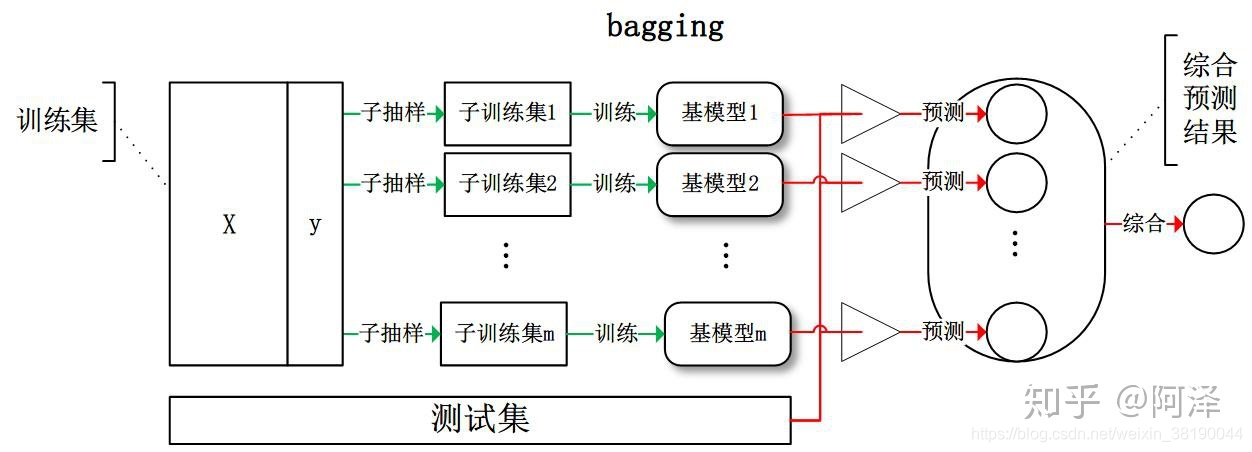
1.1 Bagging
Bagging 全称叫 Bootstrap aggregating,看到 Bootstrap 我们立刻想到著名的开源前端框架(抖个机灵,是 Bootstrap 抽样方法) ,每个基学习器都会对训练集进行有放回抽样得到子训练集,比较著名的采样法为 0.632 自助法。每个基学习器基于不同子训练集进行训练,并综合所有基学习器的预测值得到最终的预测结果。Bagging 常用的综合方法是投票法,票数最多的类别为预测类别。
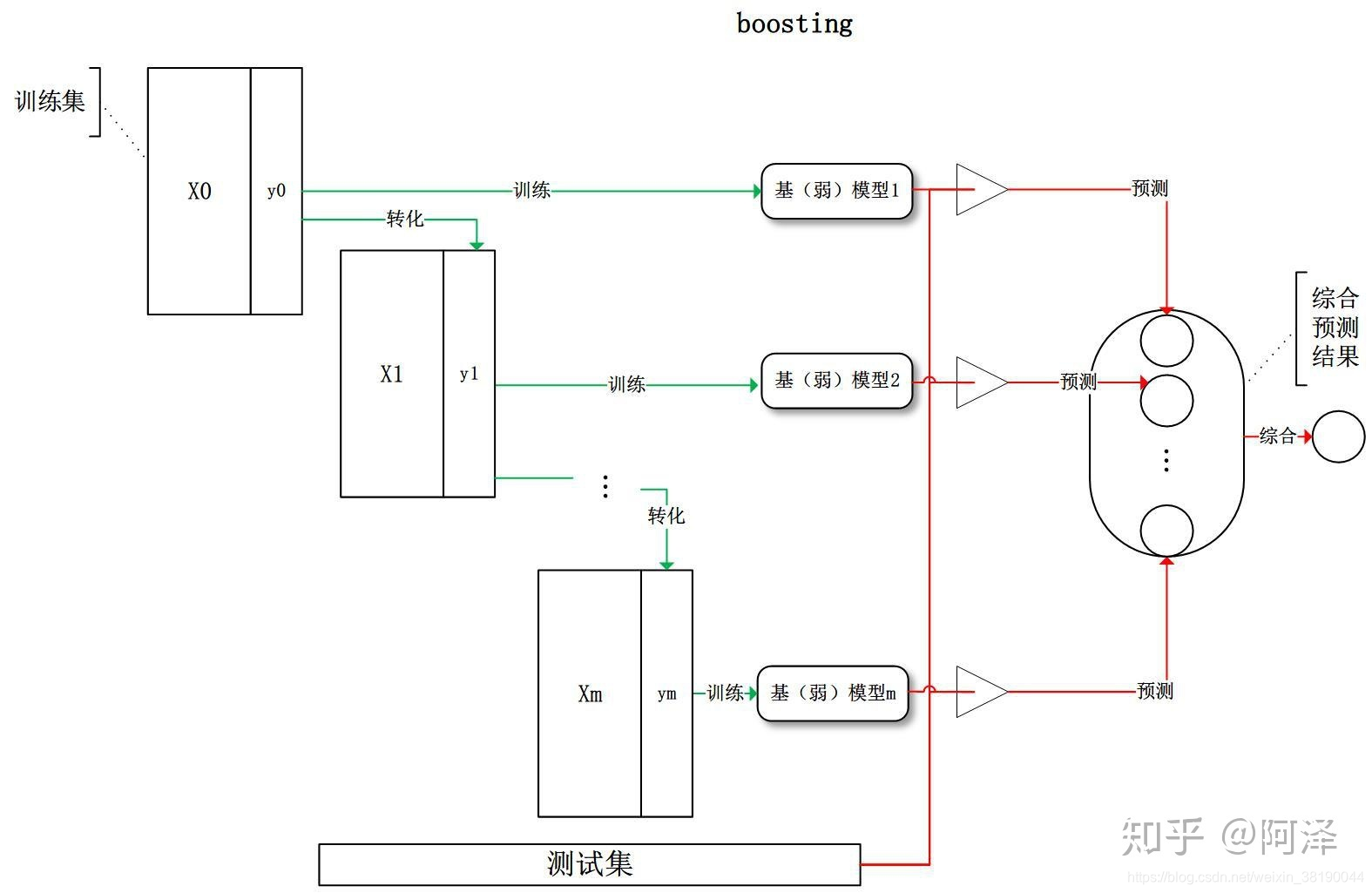
1.2 Boosting
Boosting 训练过程为阶梯状,基模型的训练是有顺序的,每个基模型都会在前一个基模型学习的基础上进行学习,最终综合所有基模型的预测值产生最终的预测结果,用的比较多的综合方式为加权法。
1.3 Stacking
Stacking 是先用全部数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3935
3935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









