







 本文档详细介绍了在Windows环境下如何部署ChatGLM3-6B模型。首先,需要安装git工具并从GitHub下载代码。接着,安装C/C++编译环境TDM-GCC,并确保开启OpenMP支持。之后,设置ChatGLM-6B的运行环境,包括PyTorch的安装。完成环境准备后,通过streamlit运行模型测试。由于CPU资源限制,模型运行速度较慢,推荐使用量化部署以提高效率,例如int4量化版本,但更优的方案是在GPU环境下运行。
本文档详细介绍了在Windows环境下如何部署ChatGLM3-6B模型。首先,需要安装git工具并从GitHub下载代码。接着,安装C/C++编译环境TDM-GCC,并确保开启OpenMP支持。之后,设置ChatGLM-6B的运行环境,包括PyTorch的安装。完成环境准备后,通过streamlit运行模型测试。由于CPU资源限制,模型运行速度较慢,推荐使用量化部署以提高效率,例如int4量化版本,但更优的方案是在GPU环境下运行。
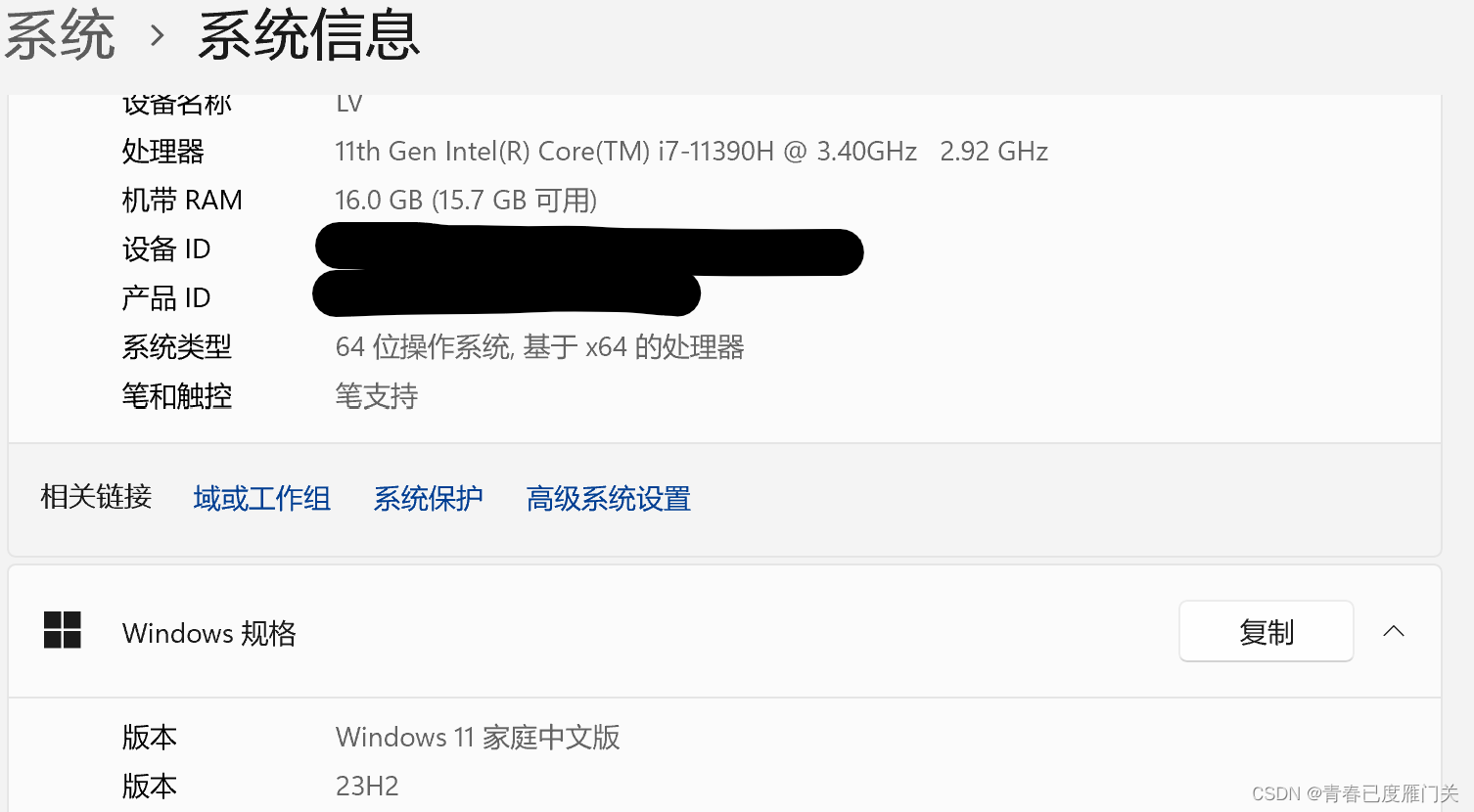
Window硬件配置
1 安装git工具
下载地址:Git - Downloading Package
一路next默认安装即可。
2 下载chatGLM3-6B
2.1 从github上下载代码
下载地址:https://github.com/THUDM/ChatGLM3
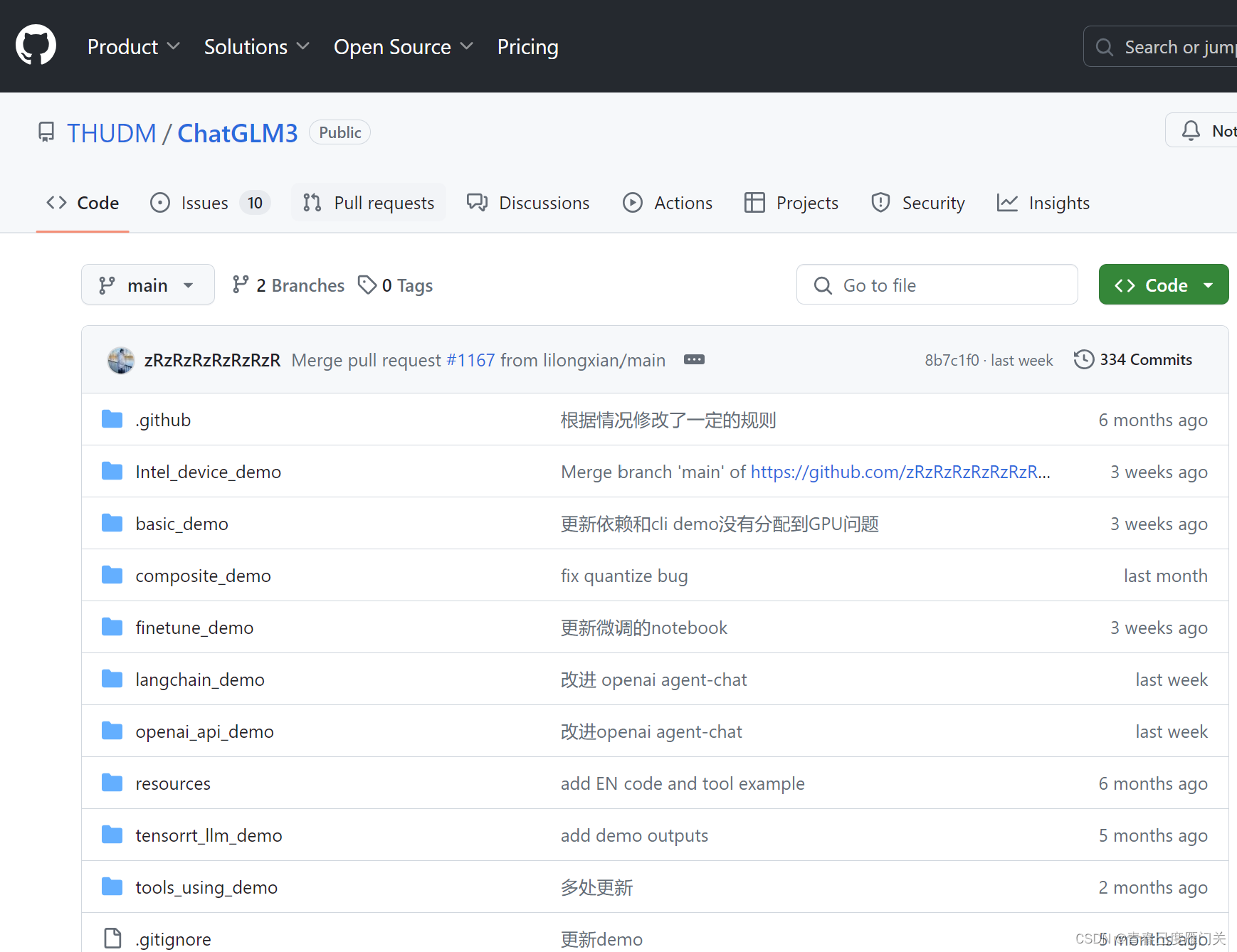
下载命令:
git clone https://github.com/THUDM/ChatGLM3
下载完毕后,安装依赖包:
cd ChatGLM3
pip install -r requirements.txt等待安装完毕:
2.2 下载模型文件
下载地址:魔搭社区
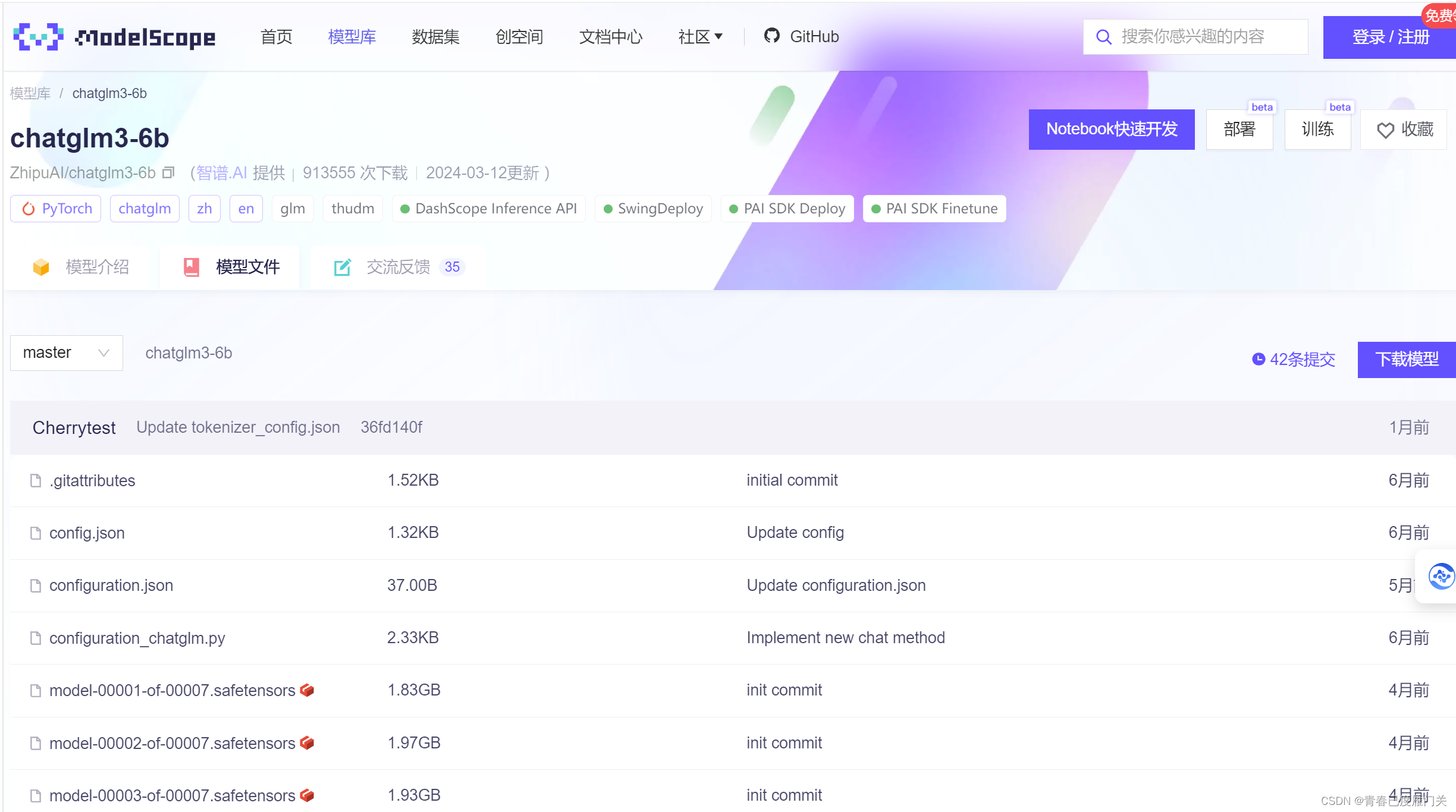
下载命令:
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git 3 C/C++编译环境安装
开始安装软件,点击Create
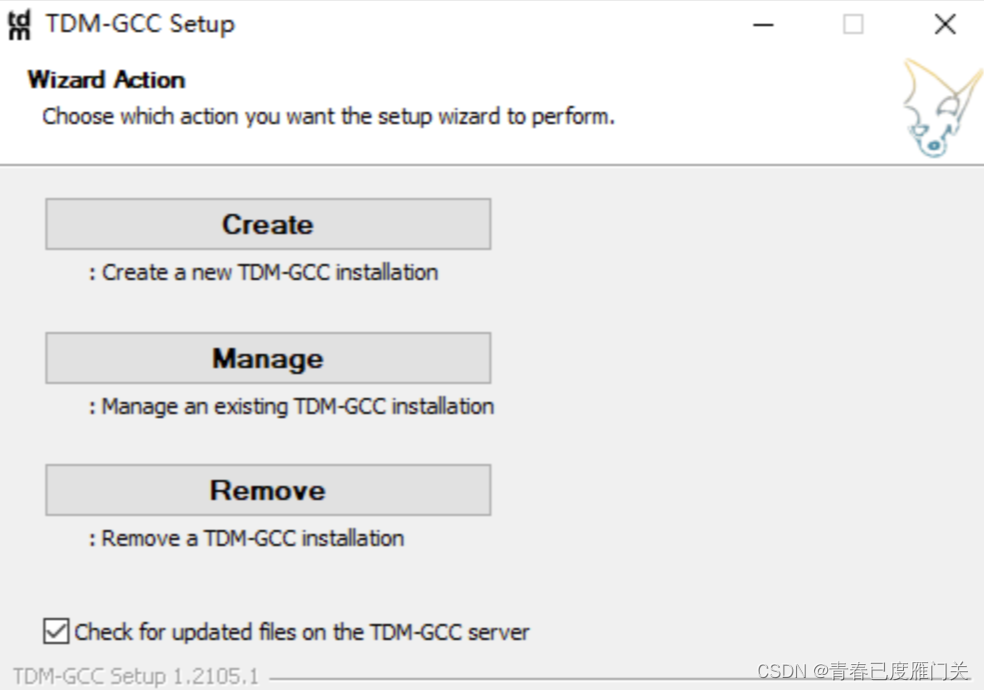
选择安装版本,然后Next
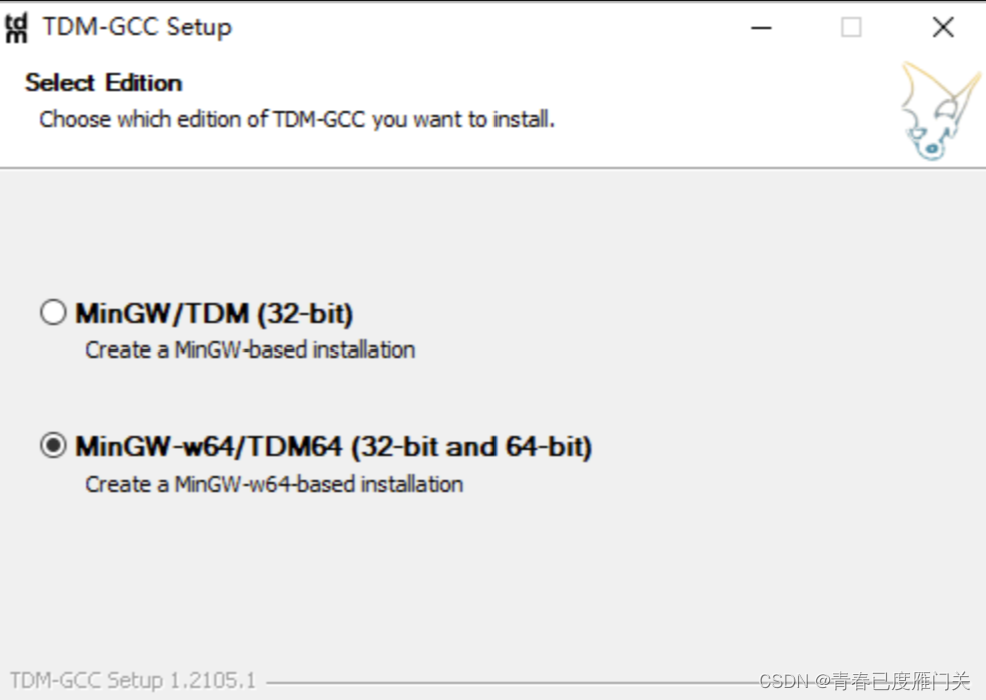
选择安装路径,然后Next
打开gcc选项,向下找openmp
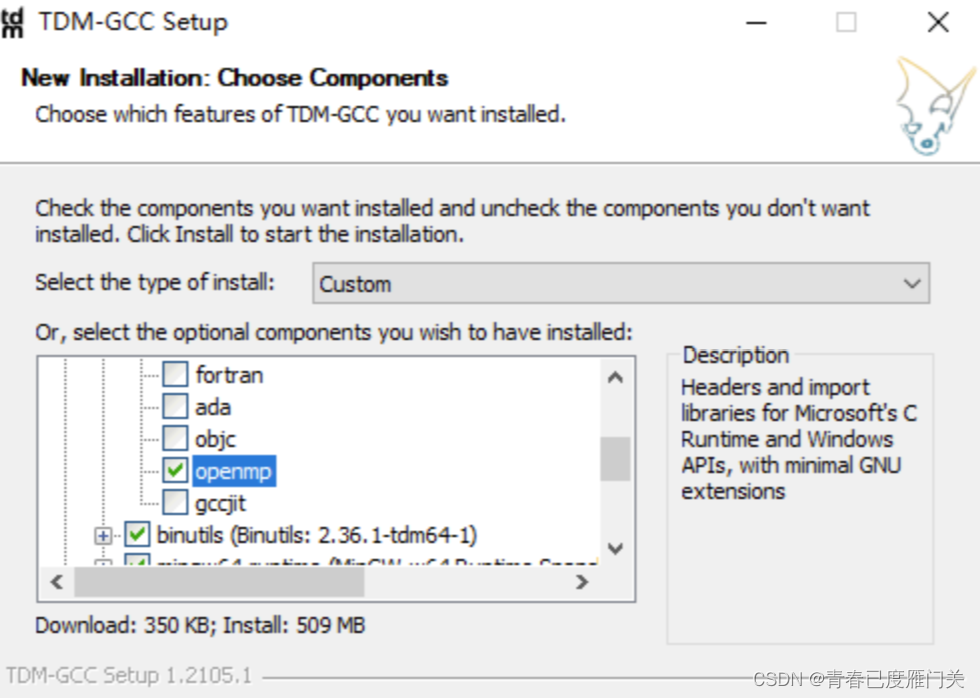
勾选openmp,然后Install
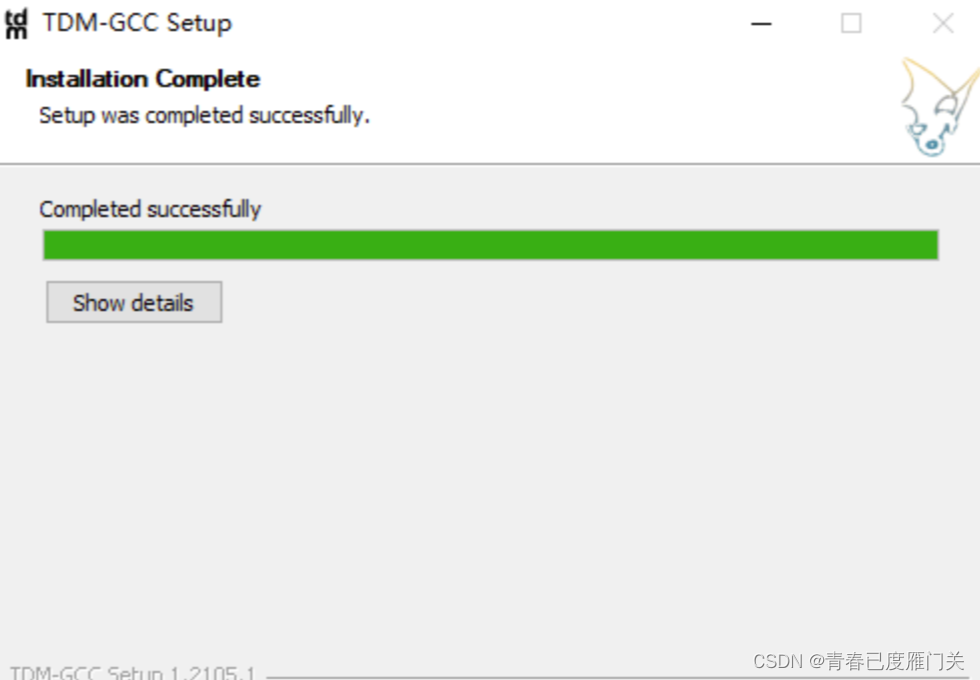
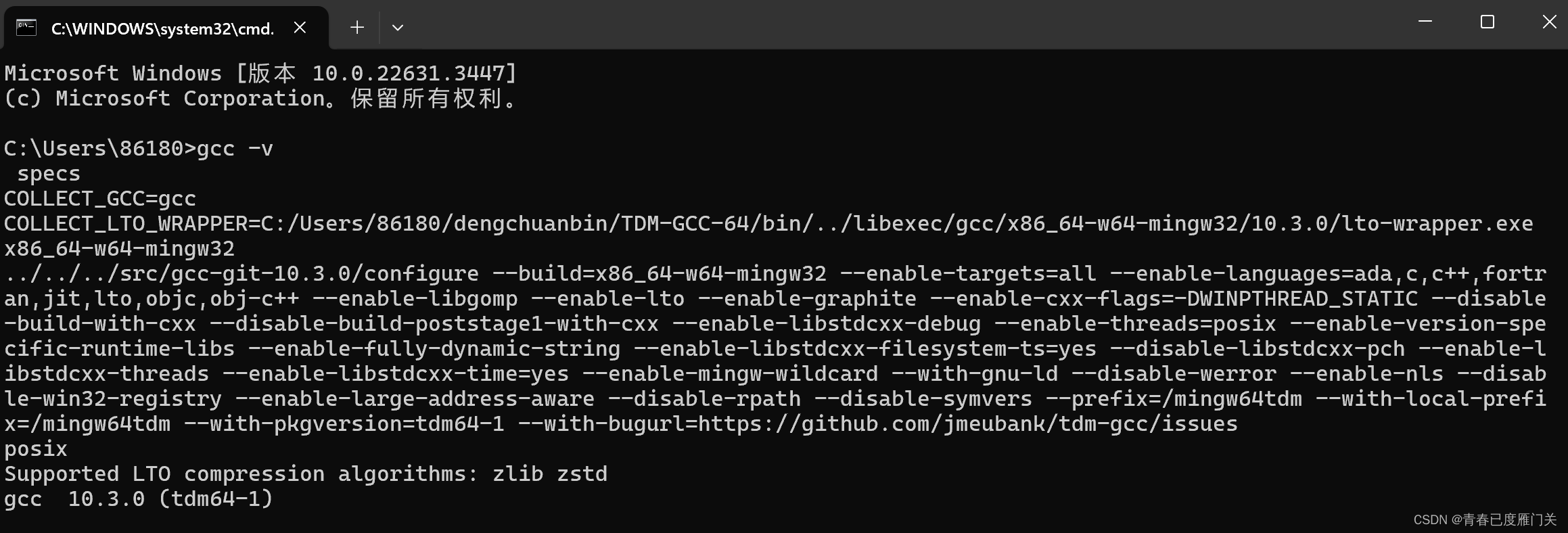
检查是否安装成功
4 ChatGLM-6B运行环境
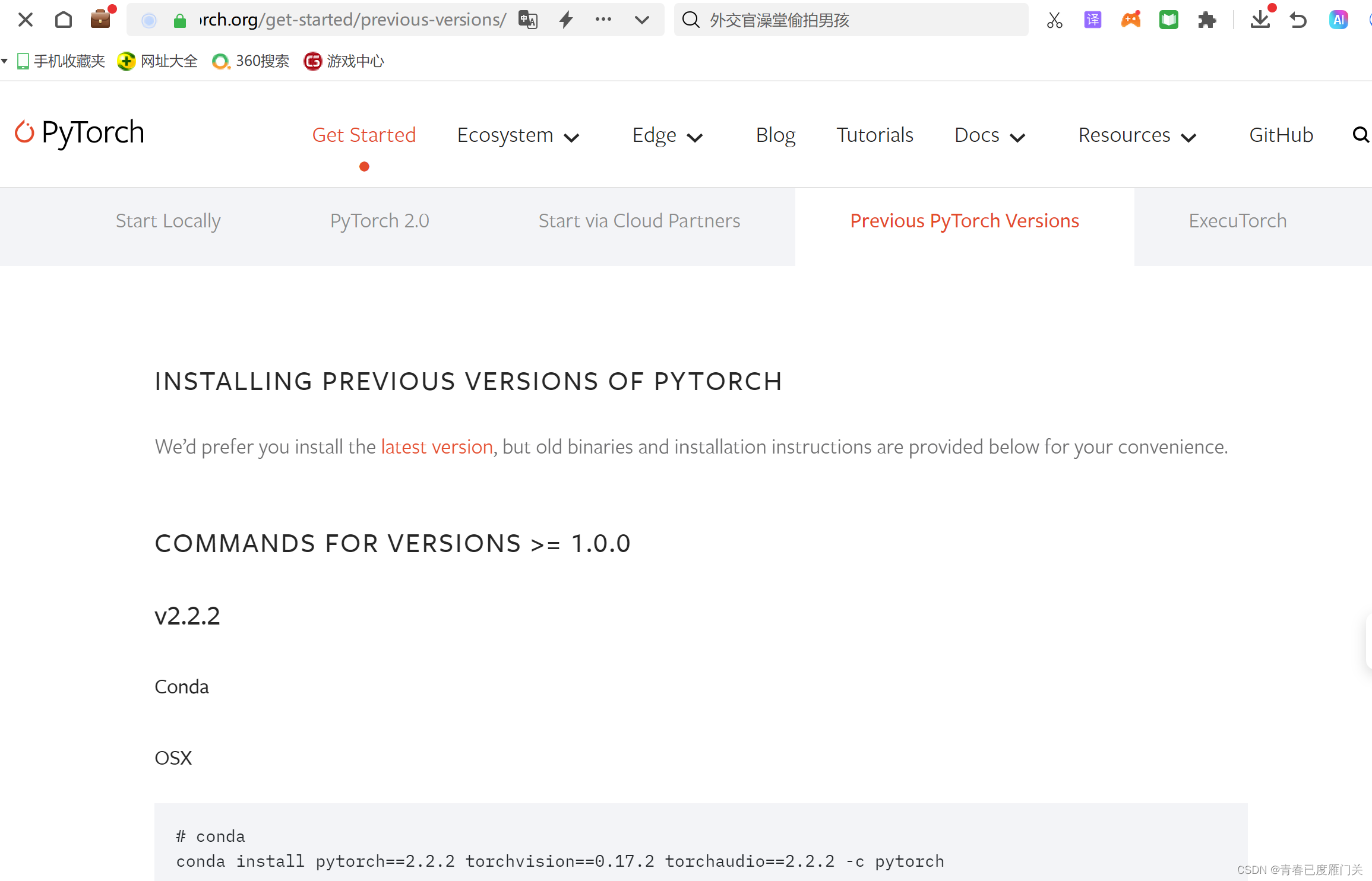
进入pytorch官网,查找安装指令
5 开始运行测试
准备好环境后,便可以进行测试,运行代码如下
import os
import streamlit as st
import torch
from transformers import AutoModel, AutoTokenizer
MODEL_PATH = os.environ.get('MODEL_PATH', './chatglm3-6b')#MODEL_PATH为模型文件所在目录
TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", MODEL_PATH)
st.set_page_config(
page_title="AI_ChatGLM_Assistant",
page_icon=":robot:",
layout="wide"
)
@st.cache_resource
def get_model():
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)
# model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True, device_map="auto").half()
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).float()
return tokenizer, model
tokenizer, model = get_model()
if "history" not in st.session_state:
st.session_state.history = []
if "past_key_values" not in st.session_state:
st.session_state.past_key_values = None
max_length = st.sidebar.slider("max_length", 0, 32768, 8192, step=1)
top_p = st.sidebar.slider("top_p", 0.0, 1.0, 0.8, step=0.01)
temperature = st.sidebar.slider("temperature", 0.0, 1.0, 0.6, step=0.01)
buttonClean = st.sidebar.button("清理会话历史", key="clean")
if buttonClean:
st.session_state.history = []
st.session_state.past_key_values = None
if torch.cuda.is_available():
torch.cuda.empty_cache()
st.rerun()
for i, message in enumerate(st.session_state.history):
if message["role"] == "user":
with st.chat_message(name="user", avatar="user"):
st.markdown(message["content"])
else:
with st.chat_message(name="assistant", avatar="assistant"):
st.markdown(message["content"])
with st.chat_message(name="user", avatar="user"):
input_placeholder = st.empty()
with st.chat_message(name="assistant", avatar="assistant"):
message_placeholder = st.empty()
prompt_text = st.chat_input("请输入您的问题")
if prompt_text:
input_placeholder.markdown(prompt_text)
history = st.session_state.history
past_key_values = st.session_state.past_key_values
for response, history, past_key_values in model.stream_chat(
tokenizer,
prompt_text,
history,
past_key_values=past_key_values,
max_length=max_length,
top_p=top_p,
temperature=temperature,
return_past_key_values=True,
):
message_placeholder.markdown(response)
st.session_state.history = history
st.session_state.past_key_values = past_key_values
行时是使用streamlit运行web的方式,在终端输入命令如下
streamlit run app.py
等待模型文件加载完成:

模型文件加载完成后,打开 http://localhost:8501或http://192.168.31.93:8501
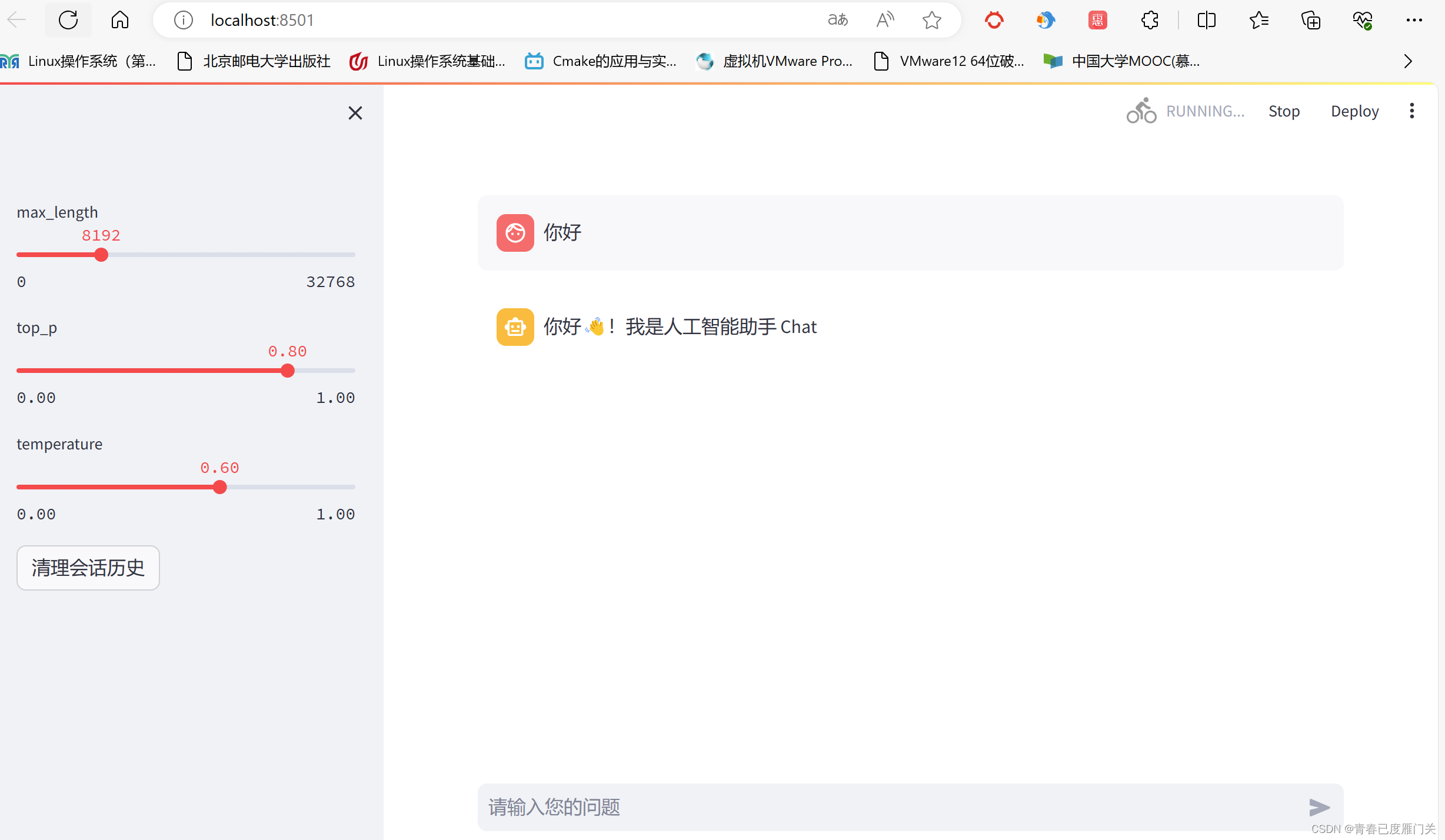
支持chatGLM3-6B已经在本地CPU环境正常启动,可以尝试问一些问题进行验证。
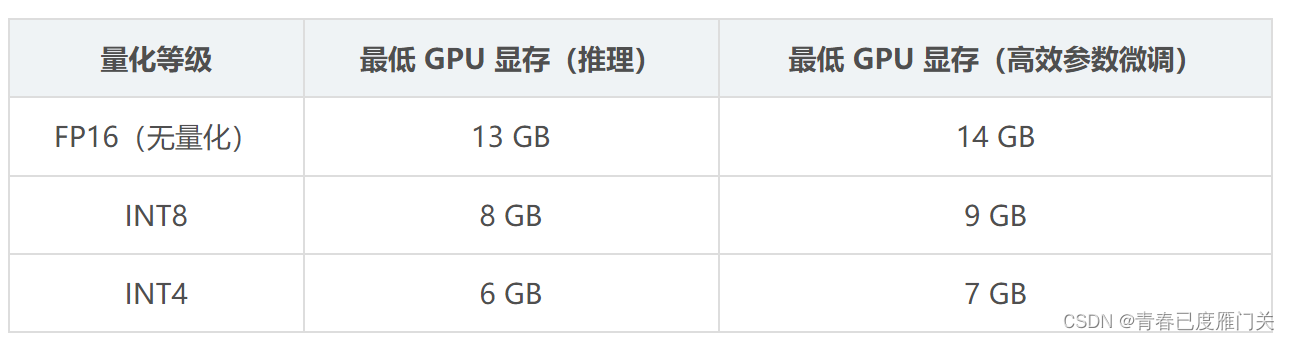
大模型进行正常交互,由于CPU资源有限,大模型处理速度非常慢,需要进行优化部署。以下是不同量化等级版本需要的硬件资源
6 int4量化部署
首先下载int4量化版本,下载链接:
下载命令:
git lfs install
git clone https://huggingface.co/THUDM/chatglm-6b-int4更改加载的模型目录:
model = AutoModel.from_pretrained("./chatglm2-6b-int4",trust_remote_code=True).float()运行脚本加载模型:
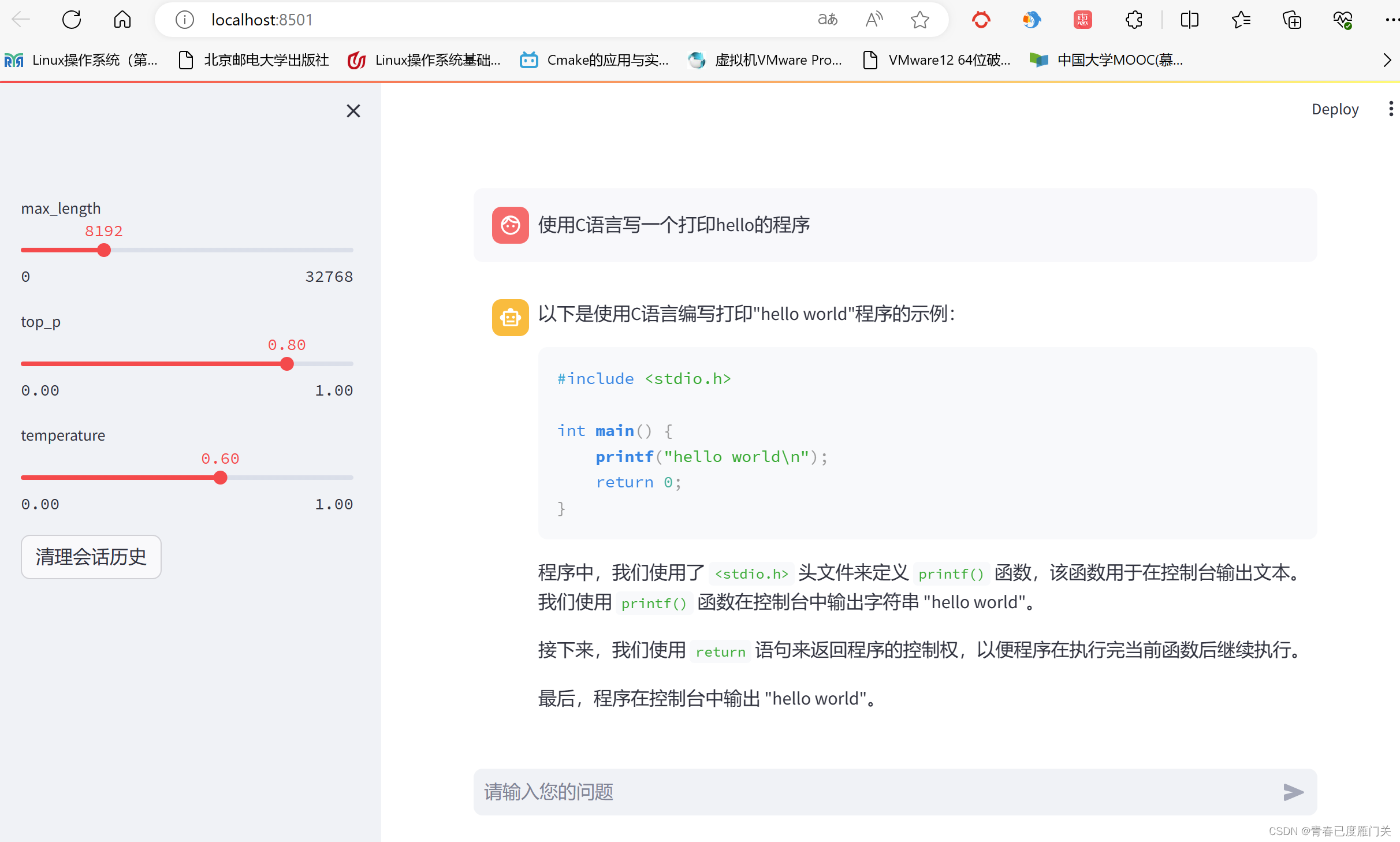
加载和推理速度有所提升,但如果需要规模使用需要在GPU 上运行。
注意在量化部署的时候,如果出现以下错误:
AttributeError: 'ChatGLMTokenizer' object has no attribute 'sp_tokenizer'需要找到模型文件目录下的tokenization_chatglm.py文件,将文件中的223行:
self.sp_tokenizer = SPTokenizer(vocab_file, num_image_tokens=num_image_tokens)
移动到super()初始化之前:
class ChatGLMTokenizer(PreTrainedTokenizer):
"""
Construct a ChatGLM tokenizer. Based on byte-level Byte-Pair-Encoding.
Args:
vocab_file (`str`):
Path to the vocabulary file.
"""
vocab_files_names = {"vocab_file": "ice_text.model"}
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask", "position_ids"]
def __init__(
self,
vocab_file,
do_lower_case=False,
remove_space=False,
bos_token='<sop>',
eos_token='<eop>',
end_token='</s>',
mask_token='[MASK]',
gmask_token='[gMASK]',
padding_side="left",
pad_token="<pad>",
unk_token="<unk>",
num_image_tokens=20000,
**kwargs
) -> None:
# 移动到此处
self.sp_tokenizer = SPTokenizer(vocab_file, num_image_tokens=num_image_tokens)
super().__init__(
do_lower_case=do_lower_case,
remove_space=remove_space,
padding_side=padding_side,
bos_token=bos_token,
eos_token=eos_token,
end_token=end_token,
mask_token=mask_token,
gmask_token=gmask_token,
pad_token=pad_token,
unk_token=unk_token,
num_image_tokens=num_image_tokens,
**kwargs
)
self.do_lower_case = do_lower_case
self.remove_space = remove_space
self.vocab_file = vocab_file
self.bos_token = bos_token
self.eos_token = eos_token
self.end_token = end_token
self.mask_token = mask_token
self.gmask_token = gmask_token
# 此处注释掉
# self.sp_tokenizer = SPTokenizer(vocab_file, num_image_tokens=num_image_tokens)
""" Initialisation """
@property
def gmask_token_id(self) -> Optional[int]:
if self.gmask_token is None:
return None
return self.convert_tokens_to_ids(self.gmask_token)

















 7425
7425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









