



 本文介绍了一种通过编程方式在字母方阵中查找并定位九个特定首都名称的方法。使用了C语言实现,包括字符串匹配技术和方向移动量的定义。
本文介绍了一种通过编程方式在字母方阵中查找并定位九个特定首都名称的方法。使用了C语言实现,包括字符串匹配技术和方向移动量的定义。
有如图5.1字母方阵:
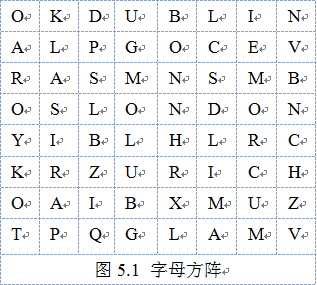
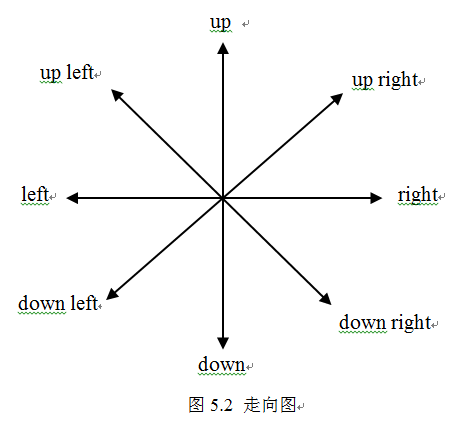
字母方阵中藏着九个首都名:DUBLIN、TOKYO、LONDON、ROME、BONN、PARIS、ZURICH、OSLO、LIMA,试设计一程序指出首都名的起始字母在字母方阵中行号和列号及字母的走向(如图5.2)。
比如下结果:

解题思路:
设字母方阵的左上角为坐标原点,令一维整型数组b[8]表示八个方向,一维整型数组di[8]和dj[8]分别表示行方向和列方向的移动量。那么在某点进行搜索时的八个方向移动量如下图5.8所示。
另外还要定义二维的字符数组A[8][8]用来存储字母方阵,用二维的字符数组C[9][7]存储九个首都名,用一维整型数组N[9]存储九个首都名的长度,用二维字符数组D[8][11]存储八个方向符号,用一维的字符数组E[7]存储从字母方阵中的某个字符出发沿某个方向取到的字符串。
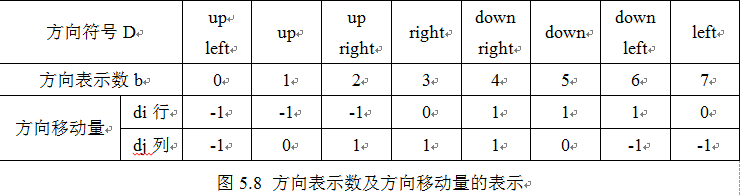
方向移动量用到了模式匹配,代码未列出,直接用数组来储存变化
源代码如下:
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
int main()
{
int i,j,k,l,m,n,p,q;
int N[9];
char E[7],M[9];
char A[8][8]={'O', 'K', 'D', 'U', 'B', 'L', 'I', 'N',
'A', 'L', 'P', 'G', 'O', 'C', 'E', 'V',
'R', 'A', 'S', 'M', 'N', 'S', 'M', 'B',
'O', 'S', 'L', 'O', 'N', 'D', 'O', 'N',
'Y', 'I', 'B', 'L', 'H', 'L', 'R', 'C',
'K', 'R', 'Z', 'U', 'R', 'I', 'C', 'H',
'O', 'A', 'I', 'B', 'X', 'M', 'U', 'Z',
'T', 'P', 'Q', 'G', 'L', 'A', 'M', 'V'};
char C[9][7]={"DUBLIN","TOKYO","LONDON","ROME","BONN","PARIS","ZURICH","OSLO","LIMA"};
char D[8][11]={"up left","up","up right","right","down right","down","down left","left"};
int b[8]={0,1,2,3,4,5,6,7};
int di[8]={-1,-1,-1,0,1,1,1,0};
int dj[8]={-1,0,1,1,1,0,-1,-1};
printf(" —————————————\n");
printf("| 字母表 |\n");
printf("| O K D U B L I N |\n");
printf("| A L P G O C E V |\n");
printf("| R A S M N S M B |\n");
printf("| O S L O N D O N |\n");
printf("| Y I B L H L R C |\n");
printf("| K R Z U R I C H |\n");
printf("| O A I B X M U Z |\n");
printf("| T P Q G L A M V |\n");
printf(" —————————————\n");
for (i=0;i<=8;i++) /*按首都名依次搜索*/
{
N[i]=strlen(C[i]);
for (j=0;j<=7;j++) /*扫描A中的每个字符*/
for (k=0;k<=7;k++)
{
q=0;
for (l=0;l<=7;l++) /*扫描每一个方向*/
{
m=0;n=0;p=0;
while((m+j)<8&&(n+k)<8&&p<N[i])
{
E[p]=A[m+j][n+k];
m=m+di[l];
n=n+dj[l];
p=p+1;
}
E[p]='\0';
if(strcmp(E,C[i])==0)
{
q=1;
break;
}
}
if(q==1)
printf("\n%s\t\t%d,%d\t%s ",C[i],j+1,k+1,D[l]); /*输出结果*/
}
}
printf("\n");
system("pause");
}

















 4679
4679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









