



▐ 摘要
阿里妈妈的联盟营销生态刻画了商品在淘客和用户间的推广和传播路径,形成了庞大的时空网络传播图。淘客推广者 (Promoter) 对商品的推广量,反应了淘客推广商品的积极性,决定了淘客推广所需要花费的渠道资源和可能获得的收益。如何准确预测商品在淘客的推广量,决定了营销预算分配,以及最优预算分配下平台可获得的引流和成交。
目前,业界主流的评估与预测体系普遍关注推广者直接带来的销量(Self-sales),我们称之为“直接贡献”评估范式。这种范式虽然直观,但其存在着明显的局限性:它忽视了推广者在其社交网络中通过转发、分享所产生的链式传播价值,即其间接贡献。这种对传播价值的系统性忽视,导致了次优的资源配置和不公平的激励机制。为了克服“直接贡献”评估范式的瓶颈,更全面地衡量推广者的综合价值,阿里妈妈技术提出从“直接贡献”评估到“传播价值”评估的建模范式迁移。具体地,我们首次定义了衡量推广者间接贡献的新指标—传播规模(Propagation Scale),并致力于解决其预测这一具有挑战性的时序预测任务。
然而,直接预测“传播规模”是极其困难的,因为它作为在推广网络中的节点信号,本身就不够平滑,并且其所依赖的推广网络更是高度动态变化的。为此,我们设计了一个创新的两阶段解耦预测框架DNTS。我们不再试图直接拟合复杂的目标,而是将其解耦为预测更平稳的基础信号(自销量)和预测动态的推广网络结构(传播关系)这两个子任务,最后再通过合成机制得到“传播规模”的精准预估。
目前DNTS框架在联盟商品推荐系统业务中,取得了GMV +2.52% 和销量 Sales+2.40% 的显著业务增益。
基于该工作整理的论文已发表在CIKM 2025,欢迎阅读。
论文:Dynamic Network-Based Two-Stage Time Series Forecasting for Affiliate Marketing
作者:Wang zhe, Yaming Yang, Ziyu Guan, Bin Tong, Rui Wang, Wei Zhao, Hongbo Deng
链接:https://arxiv.org/pdf/2510.11323
1. 背景
联盟营销(Affiliate Marketing)是现代数字营销的关键模式之一。它构建了一个由商家、推广者和消费者构成的三方共赢生态。其基本流程如下图所示:商家发布商品,推广者从中挑选商品并生成专属推广链接,分享至自己的私域渠道。当消费者通过该链接完成购买后,平台会将这笔订单归因于该推广者,并支付其相应佣金。
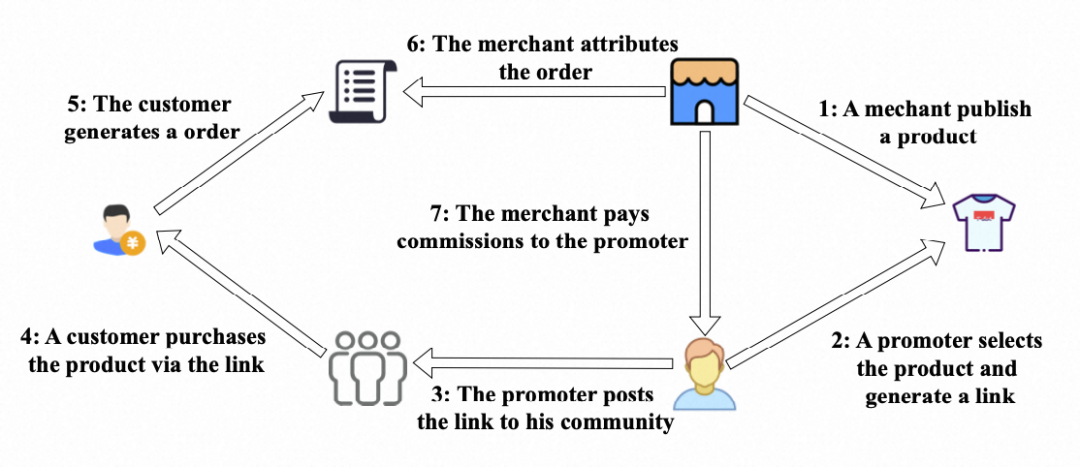
推广者在联盟营销生态中扮演着至关重要的角色,是商家与消费者之间的桥梁。衡量并量化推广者对特定商品的推广能力,有助于商家评估和有效配置推广渠道资源,同时解决佣金分配的公平性问题。目前主流的做法是以推广者直接带来的销售额,即自销量 (Self-sales),作为其贡献的衡量标准。
然而,这种“直接贡献”的评估范式存在一个明显的局限性:它是一个“原子化”的视角,完全忽略了推广者在推广活动中的传播价值。
例如,如下图(a)所示,推广者的销量贡献表示为 a/b, 其中 a 对应推广者的自销量,b 对应推广者的传播销量。图中 在“直接贡献”的评估范式下,他可能被判定为无效推广者。但事实上,正是由于他的转发行为,才激活了下游的推广者 ,并最终生成订单。 作为这条有效推广链路上的关键枢纽,其传播价值被忽略,这可能会带来以下两个问题:
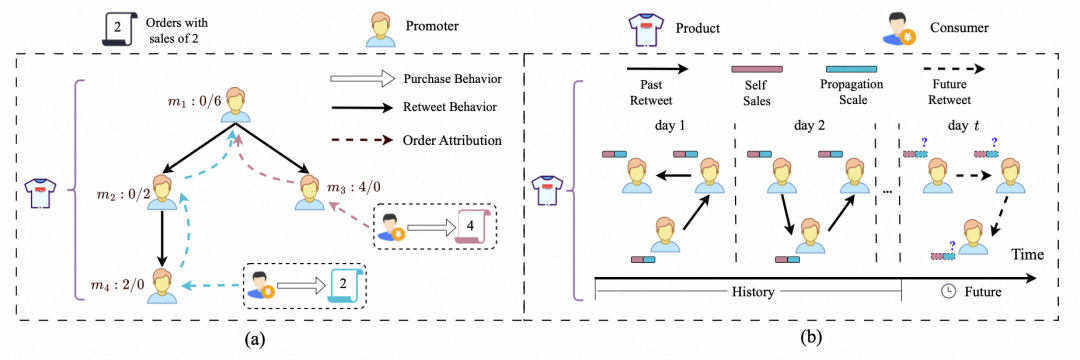
价值衡量偏差: 平台错误地将 这样的“播种者”、“连接者”等同于没有任何贡献的“无效推广者”,无法识别出真正具备传播价值的关键节点。
资源分配失准: 平台会将更多资源和激励倾斜给像 这样的“收割者”,而忽视了对 这类“播种者”的培育和激励,长此以往将损害生态的多元性和健康度。
基于此,我们首次提出并定义了一个新颖的、衡量推广者间接传播价值的指标——传播规模 (Propagation Scale)。我们致力于实现一次建模范式的迁移:从单一的“直接贡献”评估,升级到更全面的“传播价值”评估,我们提出了Propagation Scale的时序预测任务,如图(b)所示。
我们将连续动态变化的推广网络以天为粒度进行离散化处理,即每一天对应一个推广网络快照。我们的目标是基于历史的传播销量时序数据与动态的推广网络,来预测未来时刻推广者的传播销量。
2. 方案
2.1 Propagation Scale定义
为了科学地量化推广者的间接传播价值,我们首先需要从原始的订单数据中,通过归因分析,追溯出每一笔订单所对应的完整推广链路(即,从最初选品的推广者到最终促成购买的推广者)。一个推广者的“传播规模”,就是所有其参与过的推广链路最终所产生的订单的销量总和。我们首先给出传播规模的形式化定义:
其中 代表着订单, 代表着推广者 直接或间接参与促成的订单集合。对于任意一个订单 ,其对应的销量 。为了更清晰地阐述该定义,我们以图1(a)中的一个具体案例进行说明:
链路一(红色路径): 推广者 将商品分享给 , 最终促成了一笔销量为 的订单,我们记为 。因此,这条订单的归因链路是 。
链路二(蓝色路径): 推广者 将商品分享给 , 再分享给 , 最终促成了一笔销量为 的订单,我们记为 。因此,这条订单的归因链路是 。
对于推广者 : 由于他同时出现在了订单 和 的推广链路上,因此他的相关订单集合为 。其传播规模为这两笔订单的销量之和:
对于推广者 : 由于他只出现在了订单 的推广链路上,因此他的相关订单集合为 。其传播规模为:
2.2 方法框架
我们的目标是基于每个推广者历史的Propagation Scale时序数据,来预测该推广者未来的Propagation Scale值。然而,这并不是一个简单的任务,有着以下两个难点:
a. 信号不平滑:Self-Sales相对平稳,而Propagation Scale受到整个下游推广网络的影响,呈现出剧烈的、难以预测的波动。
b. 推广高度动态:商品在每一天的推广网络都不同,形成了一个庞大(|商品| x |天数|)且动态演化的网络集合。传统的基于GNN的时序预测方法,通常假设图结构是静态的(尽管连边权重是动态的),并不能解决该问题。
由于难点一的存在,我们难以直接对Propagation Scale进行预测。我们的核心洞察是:Propagation Scale预测任务可以被拆解为两个更简单、更稳定的基础元素的组合—每个节点的“自销量”预测和节点间的网络结构预测。随后我们通过合成机制来完成最终Propagation Scale的预测。
2.3 方法细节
在接下来的阐述中,我们将遵循以下符号约定:
表示推广者集合 中的某一推广者个体
表示商品集合 中的某一商品
代表着时间跨度(以天为单位)
代表着嵌入向量,其中 代表着推广者 的嵌入, 代表着商品 的嵌入
代表着可学习的投影矩阵
代表着推广网络上的初始信号矩阵,存储着每个淘客在 天内的自销量。
代表着标签向量,存储着每个淘客未来的传播规模。
与传统基于GNN的时序预测方法不同,DNTS为网络信号和网络结构设计了独立的预测通路。
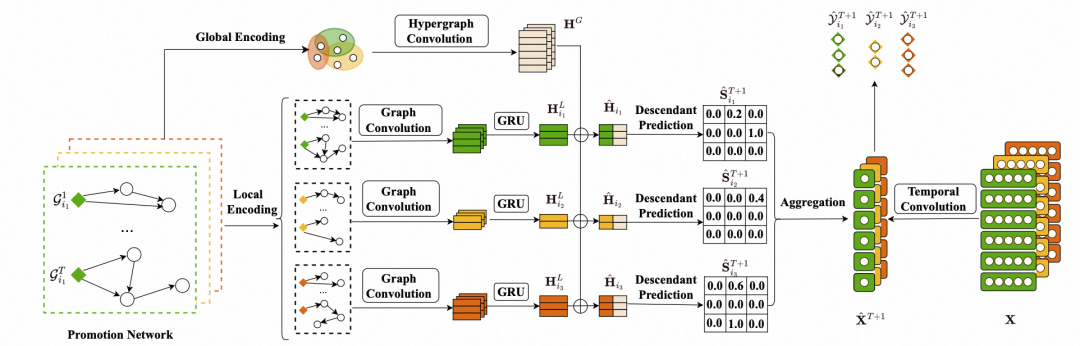
基础信号预测: 预测每个推广者未来的自销量。采用一维时间卷积模块,通过多尺度卷积核的Inception策略,从历史自销量序列中提取多样的时序模式,通过门控机制融合后得到未来自销量的预测值,记为 。
结构预测通路:预测未来的推广网络。针对推广高度动态这一难点(对应难点二),我们不预测完整的推广图,而是简化为预测节点间的后代关系。为此,我们设计了“局部+全局”的双重编码器来学习推广者的动态表征:
局部动态编码:重建 个推广网络并不切实际。因为在实际工业场景中,商品的规模很容易达到亿级别,但是识别每个推广者的潜在后代是切实可行的。因此,我们采用深度优先搜索 (DFS) 算法,以预处理的方式获取每个推广者的后代集 ,表示如下:
其中 代表着m与d之间至少存在着一条连通路径。
随后我们基于注意力机制聚合后代信息以及利用GRU来捕捉时态模式。
全局动态编码: 引入超图卷积,将同一天内所有商品的推广网络整合为一个超图,从而捕捉跨商品的全局推广偏好。具体来说,我们收集第 天所有商品的促销网络,得到 。然后,我们将 中的推广者视为节点,将其在商品促销中的参与关系视为超边,从而得到关联矩阵 , 表示 。令 表示参与推广 的推广者组成的超边, 表示 的表示。我们先后执行节点到超边聚合 超边到节点更新来完成超图卷积:
其中, ,同样,我们利用 GRU 对 天内的时间依赖关系建模:
最后,我们可以得到推广者最终的结构表示:
其中 代表着在商品 对应的推广网络下淘客 更新后的局部嵌入。进一步的,我们可以得到推广者最终的结构嵌入矩阵 。
Propagation Scale合成:在编码阶段,我们得到了预测的自销量 与更新后的结构表征 。在解码阶段,我们通过一个可微分的合成模块计算出最终的Propagation Scale。该模块首先预测一个贡献系数矩阵:
其中 代表着后代关系概率矩阵, 代表着节点自销量的激活率矩阵,Gumbel-Softmax是一种可微采样技术,用于采样出可能的后代集合。最后,我们通过矩阵乘法聚合机制来最终合成propagation scale:
在这种方式下,自销售不为零但激活率为零的后代,以及自销售量为零的后代,都会被自动排除在外,只留下激活率和自销售量均大于零的后代,而这些后代正是合成传播规模的有效成分,这确保传播规模的准确预测。
3. 在线部署
在DNTS的实际部署中,我们还面临着两大真实的工业级挑战,分别为:
数据稀疏性:线上商品数量亿万,但每个商品相关的推广者只是其中一小部分。
高波动性:由于运营策略的变化,商品推广热度可能会在几天内爆发,而推广者对该商品的推广活动在大部分时间里是“沉默”的,这给预测任务带来了难度。
我们为此设计了专门的解决方案:
针对挑战一的解决方案:构建商品级推广者子表。 我们为每个商品动态维护一个相关的“推广者子集”,所有图计算都在这个子集上进行,既保证了效率,又缓解了稀疏问题。
针对挑战二的解决方案:设置一个推广者激活预测辅助任务。 我们增加了一个辅助任务,专门预测在未来某个时间点,哪些推广者会是“活跃”的。其预测的激活状态会作为门控,过滤掉“沉默”的推广者,从而缓解波动性对预测任务的影响。
4. 实验
我们通过在阿里妈妈的大规模工业数据集上进行的一系列实验,来系统性地回答以下问题:
1) 我们提出的DNTS框架,相较于现有的SOTA基于GNN的时序预测模型,是否具有优势?
2) 性能的提升究竟源自何处?是“两阶段解耦”这一新范式本身,还是其中某个具体的模型组件?
3) 离线指标的提升,能否最终转化为线上真实的业务收益?
4.1 实验设置
数据集:我们从阿里妈妈的真实业务场景中构建了三个不同时间跨度的大规模工业级数据集: 、 和 。其中 数据集包含了超过近10万名推广者和近600万条推广连边。
对比基线 : 我们选择了能够处理图结构的时序预测模型作为基线,包括DCRNN[1]、STGCN[2]、LSGCN[3]、以及在最近在相关领域表现卓越的MTGNN[4]和TPGNN[5]。
评估指标 (Evaluation Metrics): 我们采用通用的MAPE (平均绝对百分比误差) 和MSLE (均方对数误差)作为核心评估指标。MSLE尤其适合我们这种销售额数值范围跨度巨大的场景,因为它对异常大值不敏感,能更公允地评估模型的整体预测性能。两个指标都是值越低性能越好。
4.2 离线实验
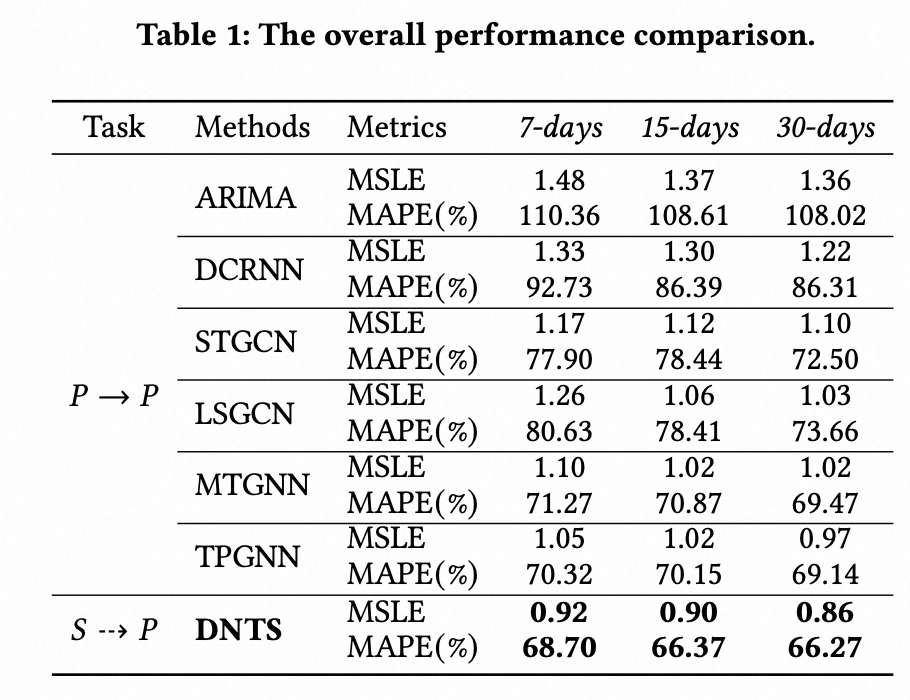
从表一的实验结果中,我们可以看到:DNTS取得了全方位的性能领先:在所有三个数据集上,DNTS的核心指标均显著优于所有基线模型。相较于表现最好的基线TPGNN,DNTS在30-days数据集上取得了11.3%的MSLE相对提升和4.1%的MAPE相对提升。所有模型在 数据集上的表现普遍优于 ,这符合预期,证明了模型能够有效利用更丰富的历史信息。尽管TPGNN等模型通过引入图自学习、时间多项式等技术不断优化,但它们仍然在传统的“信号-图卷积”端到端范式下运行,面对我们定义的这个新问题时,明显表现乏力,而我们的两阶段预测方法能更好的处理层级预测任务。
总体性能的领先证明了DNTS的“有效性”,但我们更关心其背后的“原因”。我们提出的“两阶段解耦”范式,究竟是不是性能提升的关键?为了回答这个问题,我们设计了一组的诊断性实验。我们将预测任务分为三种模式,并分别考察在每种模式下,GNN模块的引入是带来“增益”还是“拖累”:
模式一 ( ): 传统端到端范式。输入是历史propagation scale时序数据,直接预测未来propagation scale。
模式二 ( ):基础信号预测。输入是历史self-sales数据,预测未来的self-sales。
模式三 ( ): 我们的两阶段范式。输入是历史propagation scale时序数据,通过预测中间的推广网络和自销量,最终合成propagation scale。
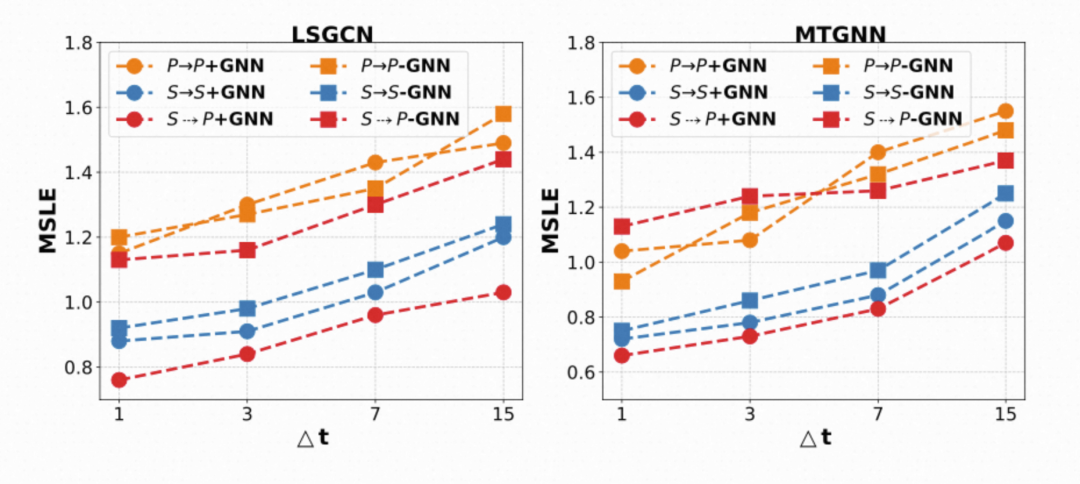
根据上图可以发现:
发现1(基础信号的可预测性): 的预测任务性能要明显优于 的预测(指标为MAPE,因此可以进行比较),这说明了self-sales相对于propagation scale时序规律更明显,因此更容易预测。
发现2 (传统范式的失效):在 模式下,GNN的引入几乎没有带来任何性能提升,甚至在LSGCN上还导致了性能下降!这说明直接在这种高度非平滑的图信号上采用图卷积,几乎是无效的。这也说明了传统基于GNN的时序预测方法难以泛化到我们的场景。
发现3 :在我们的范式下,GNN的引入带来了显著的提升。这说明,GNN虽然不擅长直接处理非平滑的propagation scale信号,但它擅长我们分配给它的新任务—预测动态的网络结构。这三个发现共同佐证了我们二阶段预测方案的动机是合理的。
4.3 在线实验
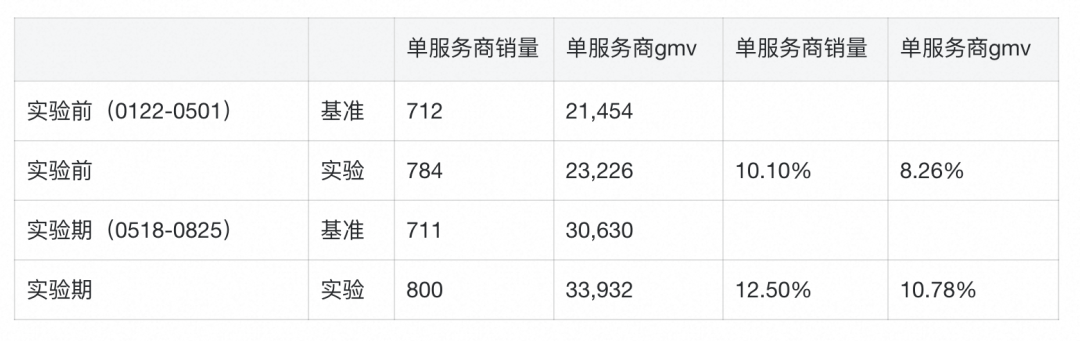
我们在阿里妈妈推荐平台上部署了DNTS,对日常召回阶段进行优化。具体来说,推广者 𝑝 对商品 𝑖 的召回率 更新为 ,其中 , 是 DNTS 预测的推广规模。我们进行了为期三个月的性能评估,并测量了两个关键指标,GMV 和销售额。如下表所示,我们可以发现,DNTS能够更精准地预测推广者针对特定商品的传播规模,提升了实验桶的召回质量,最终使得GMV和销售额都获得显著提升。
5. 参考文献
[1] Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting, ICLR 2018.
[2] Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic,IJCAI 2018.
[3] LSGCN: Long Short-Term Traffic Prediction with Graph Convolutional Networks,IJCAI 2020.
[4] Connecting the Dots: Multivariate Time Series Forecasting with Graph Neural Networks, KDD 2020.
[5] Multivariate Time-Series Forecasting with Temporal Polynomial Graph Neural Networks,NIPS 2022.
🏷 关于我们
阿里妈妈联盟算法团队依托淘宝联盟与内容营销业务,基于海量时空传播图网络,构建多Treatment价量关系等先进营销算法模型,实现智能选品、智能权益投放;在程序化流量中深耕个性化排序与匹配策略,在内容营销中覆盖企划、投放到评估的全链路智能化,包括站外趋势预测、增量人群挖掘、多触点增量预估等关键技术。团队持续突破AI前沿,探索基于强化学习与大语言模型(LLM)的多模态表征、智能文案生成及营销AI Agent,并广泛应用于同款比价、内容理解、选品出价等场景。
欢迎对智能营销与算法创新感兴趣的同学加入我们!
📮 投递简历邮箱:tongbin.tb@taobao.com
END

也许你还想看
NeurIPS'25|淘宝首猜提出回归纠偏:走近TranSUN与GTS理论
阿里妈妈营销隐私计算平台SDH:隐私安全下的数据流通与营销实践案例
阿里妈妈展示&内容广告算法,用AI推动信息流场景流量价值最大化
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~


















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









