







✍🏻 本文作者:俊广、卓立、凌潼、青萤
1. 背景
随着在搜索、推荐、广告技术上多年的迭代积累,业界逐步形成了召回(匹配)、粗排、精排这一多阶段的系统架构。其中,召回作为链路的最前端,决定了业务效果的天花板。召回阶段的主要目的是从全量广告库中高效筛选高质量top-k集合给后链路进一步打分&排序。近年来,随着机器学习,尤其是深度学习技术的发展,学术界及工业界已经全面进入到了 model-based 召回算法的研究与应用阶段。其中阿里妈妈代表性的工作有:TDM 系列算法[1-3]、二向箔索引算法[4]。在model-based的召回模型中,主要基于离散ID来描述广告和用户,这种方式直接针对最终目标进行优化,具有很高的优化效率,也非常适合个性化推荐的需求。但是,只使用离散ID模态进行个性化推荐存在以下几方面的问题:
信息不全:真正给用户展现的是商品创意、标题等图、文、视频模态信息,而非离散ID。
泛化性不强:ID类特征无泛化性,因此完全基于离散ID特征的推荐系统在长尾商品、冷启广告等低频ID上存在预估不准的问题。
与ID模态相反,图像、文本等内容内容模态泛化性强,对新广告友好,更接近用户感知,但是内容模态的个性化能力差,不容易针对广告召回的目标进行优化。例如在淘宝上可能存在多个商家使用相同的图片,但是这些店铺的信誉度有好有差,广告主的出价有高有低,内容模态都无法将其有效区分开。
离散ID模态和内容模态在分布、形态、优势上均存在明显的差异,在本文中我们将探索在展示广告的召回模型中如何将ID模态和内容模态进行融合,并提出了混合模态专家模型的设计。
2. 模型召回的形式化目标及检索方法介绍
图文内容模态主要反映了用户的兴趣偏好,因此我们这里重点介绍在以用户兴趣作为目标的召回模型中引入多模态的方法。用户兴趣召回模型是展示广告召回的主力通道之一,一方面它保障了召回的结果满足用户的兴趣和需求,另一方面避免系统陷入数据循环,保障系统的长期健康。
在用户兴趣建模中,为用户 从全库候选集 挑选出商品 的概率为:
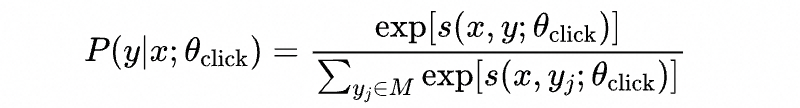
其中 表示用户 对商品 的兴趣分,对应的优化目标为:
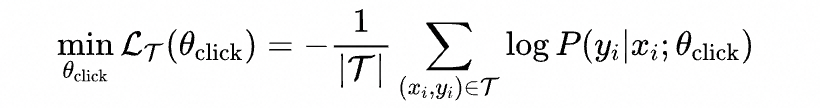
其中 表示用户在全域中的兴趣行为(点击为主,也包括购买、收藏、加购)。
推理时的目标是从候选集中找到用户点击概率最高的一个子集:
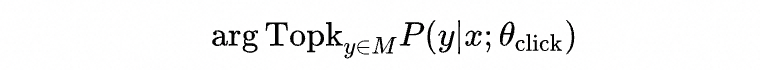
为了降低在线serving时的推理时间,我们采用了二向箔检索框架[3]来减少模型打分量。如下图所示,在推理时,首先会对Layer=2层的所有商品 计算兴趣分 ,从中挑选出兴趣分较高的商品,然后在HNSW层次化图结构进行扩展,得到Layer=1层的候选集,之后继续对扩展出的商品候选 计算兴趣分,这个过程迭代进行,直至抵达Layer=0层。通过二向箔检索,我们可以将千万级别的候选库打分量降低至万级别,同时检索精度依然接近90%。二向箔检索框架使得我们可以用相对复杂的模型结构来建模用户对商品的兴趣分,这也是我们后面引入混合模态专家召回模型的重要基础。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









