



 阿里巴巴在NeurIPS2022会议上发布GBA(GlobalBatchGradientsAggregation)训练模式,解决了同步和异步训练模式切换的问题。GBA允许在高性能和普通资源间平滑切换,保持模型效果稳定,提高训练效率。通过全局梯度聚合,GBA在保持同步训练效果的同时,利用异步训练的资源利用率,已在多个广告业务场景中应用并取得效果提升。
阿里巴巴在NeurIPS2022会议上发布GBA(GlobalBatchGradientsAggregation)训练模式,解决了同步和异步训练模式切换的问题。GBA允许在高性能和普通资源间平滑切换,保持模型效果稳定,提高训练效率。通过全局梯度聚合,GBA在保持同步训练效果的同时,利用异步训练的资源利用率,已在多个广告业务场景中应用并取得效果提升。
丨目录:
· 搜推广增量迭代挑战
· GBA的诞生
· GBA的收敛性分析
· GBA工程实现
· GBA实验效果
· 未来展望
近日,阿里巴巴在国际顶级机器学习会议NeurIPS 2022上发表了新的自研训练模式Gloabl Batch gradients Aggregation GBA(论文链接:https://arxiv.org/abs/2205.11048),由阿里妈妈事业部搜索广告团队和智能引擎事业部XDL训练引擎团队联合探索和研发。GBA的提出对阿里巴巴搜推广稀疏模型的训练范式带来了架构性的跨越式升级。本文将从GBA的设计思路、收敛性分析及工程实现等方面展开介绍,欢迎阅读交流。
在过去一段时间内,高性能同步训练架构在阿里巴巴稀疏场景的全面落地,解决了稀疏场景无法充分利用GPU,以及缺乏高效的同步训练方案两个“硬骨头”。从资源性能角度,使得不同场景的深度学习任务训练加速比(每天训练样本日期数量)提高5~10倍,并利用GPU带来3~5倍的成本优势,节省训练开销可达每年千万量级;从业务效果角度,同步训练模式优化给部分广告业务带来了CTR指标百分位的提升。在这个时间点,GBA通过对同步和异步训练自由切换的技术突破,使得低配集群的资源也充分利用起来。GBA算法使得高性能资源和普通资源具有通用性,使业务在高性能资源紧张的环境下,也可以不断享受GPU算力提升的红利,是深度学习帮助业务持续发展的重要基石。更进一步,GBA基于阿里巴巴统一资源池资源混部的环境,为所有推荐系统业务用好云打下基础。目前,GBA/同步切换这种新的训练范式已经普遍应用到阿里妈妈广告模型的迭代中,并开始在全集团推广。
▐ 搜推广增量迭代挑战
搜推广模型既需要高训练加速比回追数据的能力,也需要高并行的定性实验和日常增量训练的能力。主流搜推广稀疏大模型通常采用异步或同步的训练模式。在异步训练中,训练通常采用PS(Parameter server)架构并以高并发的方式执行,每个计算节点所需的资源量不大,可以利用阿里巴巴内部混部策略下的海量资源,适合定性实验和日常增量训练。同步训练一般采用AllReduce架构,参数直接放置在计算节点上并在节点间通过集合通讯方式进行交换。在高性能集群中,同步模式能够充分用满计算、通信硬件资源,进而获得更高的训练性能表现,理论上可以远高于同等成本下的异步训练任务。
在过去两年间,XDL训练引擎推出的HPC(High-performance computing)同步训练已经在阿里巴巴内部搜索、推荐、广告业务上得到了大量的推广,相关开源训练框架HybridBackend也受到了业界广泛的关注。但是基于搜推广模型迭代特点,以及当前资源现状,既要有HPC模式的高训练加速比,也需要有日常实验迭代的高并发实验能力。如何实现同步和异步训练的自由切换,可以充分利用HPC高性能资源以及海量混部资源,成为提高迭代效率的重要问题。并且为了避免模型迭代过程中浪费时间和浪费资源的调参,以及保证模型效果稳定,对于训练模式的切换需要做到以下几点:
【效果】同步模式切换异步模式后效果不变,获得同步训练的效果;
【性能】在混部的不稳定的资源环境下,同步模式切换异步模式后,获得异步训练资源利用效率;
【鲁棒性】无需切换优化器,无需调节优化器等一系列超参;
【扩展性】可以缓解异步训练由于worker数量增长,staleness增大对于效果的影响。
然而在实践中我们发现,直接切换训练模式无法实现上述目标,要达到上述能力也有着较大挑战:
考虑到实际业务对精度损失的低容忍性,工业界和学术界目前没有针对生产混部环境尝试训练模式切换的成熟解决方案,因此并没有明确可以走通的方案路线。
切换引发的效果问题,不是简单调整学习率或其他超参就能解决的。两种训练模式在batch大小、相同数据下更新步数、优化器选择上都有显著差异,这会导致参数更新实际上趋向于不同的收敛点。切换后短期内精度损失(甚至直接训崩)以及在每个训练阶段结束时精度潜在的不一致性,是在日常迭代开发中无法容忍的。
从高效迭代的角度,需要一种在高性能同步训练和高并发异步训练之间自由切换、无需用户中途调整超参的训练模式。桥接两种训练模式的核心问题是,如何能让两种模式训练时,梯度分布大体相同,使得模型会向一致或类似的收敛方向更新。我们观察到梯度分布、梯度延迟性是影响效果的重要突破口。基于此,我们提出了基于全局梯度聚合(GBA)的训练模式,通过先累积若干梯度、直到总batch size大小相同时再执行梯度更新。实验证明,GBA与同步训练之间是可以自由切换的,无需超参调整。
业界相关工作
近年来,业界一直在探索一种介于同步与异步之间的“半同步”训练模式,在避免慢节点的影响的同时避免效果损失。例如,在Tensorflow中已经集成的Backup Worker方式,每次同步更新时自动忽略指定个数慢节点的梯度;又如XDL中原有的限制节点间梯度版本的方式,容许有限的梯度过期。同时还有一些“半异步”训练模式相关的工作,例如每聚合若干个batch的梯度进行一次更新,或是稀疏参数的获取及更新完全去相关,都是有效缓解慢节点影响的方式。然而,尽管这些训练模式在开源数据集上都汇报出了理想的效果,但在实际工业生产场景,丢数据、严重的梯度过期对业务精度的影响是无法接受的,且快慢节点速度差异巨大是普遍情况,所以为了真正落地,现有的这些学术设计还是远远不够的。
▐ GBA的诞生
源于生产实验的观测与启示
直接切换训练模式后,效果出现严重损失
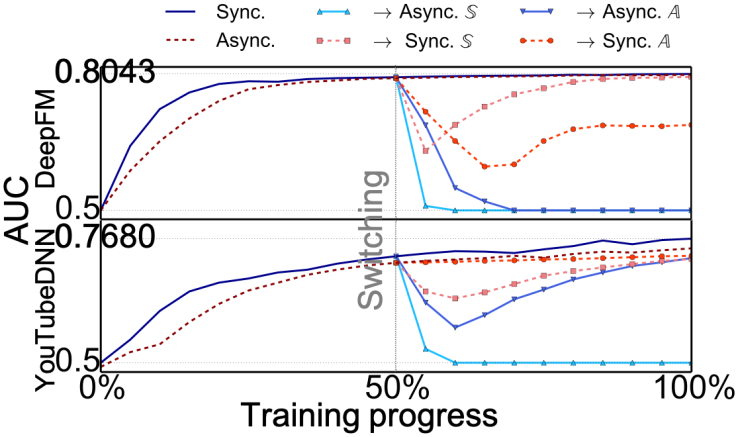
我们在Criteo竞赛数据集和生产数据集上分配执行DeepFM和双塔模型的训练任务。最初我们选择同步或异步进行训练,在数据集消费一半后切换为另外一种训练模式继续训练。图1中绘制了不同训练阶段的测试AUC,每5%的训练进度进行一次测试。可以看到,在训练模式切换刚刚发生后,无论是哪个方向的切换,都会出现一个非常明显效果损失,而后慢慢回追效果,或是直接AUC降到0.5不可恢复。这说明如果没有特殊设计或精细的调参,训练模式的切换对于模型效果将会是灾难性的打击。
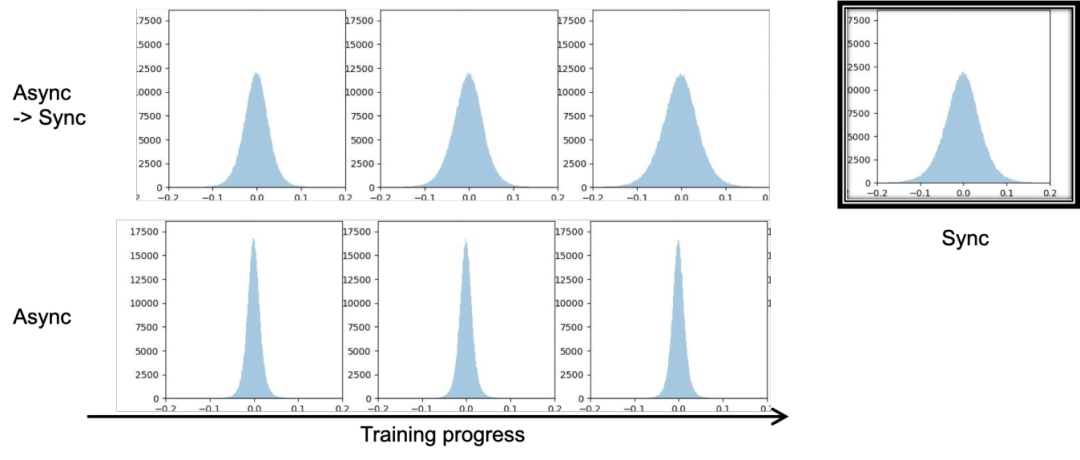
进一步的观察说明,异步和同步训练本质上会导致模型向不同的收敛方向更新,如图2所示,异步和同步训练后某层参数的分布截然不同,而异步切换为同步训练一段时间后,参数分布是被强行训练更新到了类似同步的分布上。这意味着为了获得平滑的切换,保证参数分布不变是一个值得考虑的出发点。
梯度的分布与更新梯度时实际的batch大小有关
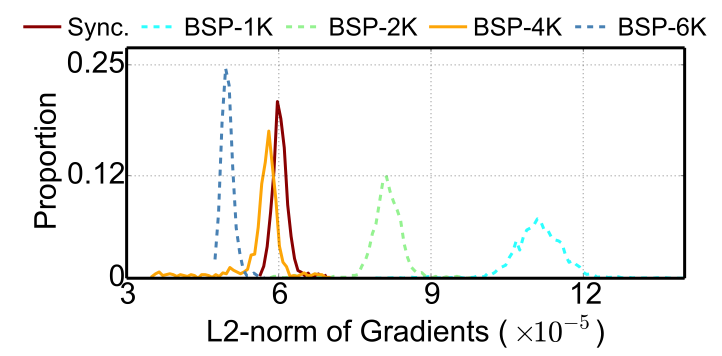
参数分布相似的前提是梯度分布也是相似的。我们使用异步梯度聚合的方式进行了大量的实验,发现当Batch大小与同步训练的全局Batch大小相同时,两种训练模式的梯度分布会比较接近(如图3所示)。考虑到集群的整体硬件资源紧张程度是变化的,在一天的不同时段执行的结果略有不同,资源紧张会带来不同计算节点执行速度更大的方差,进而带来更高的平均梯度过期程度。我们发现,梯度过期程度与两种实验中梯度分布的偏离呈正相关。这个发现启示使用相同大小的Batch进行梯度更新,且保证梯度过期程度较小,是实现平滑切换的一种潜在方案。
全局梯度聚合机制
基于上述实验分析,我们引入全局Batch大小(Global batch size)的概念,定义为梯度实际更新所聚合的样本量大小。我们定义同步训练模式下Local batch size (即每个 worker 处理 batch size的大小)大小和 worker 的数量分别为 和 。同步训练中的 Global batch size 定义为 ,并且 = × 。根据分析和观察中的结论,我们在进行训练模式切换时,GBA 会保持 Global batch size 大小不变。XDL基于PS架构,设计了全局梯度聚合机制。在这种机制下,每个计算节点各自消费数据并计算梯度,而后将梯度发送至PS节点。梯度不会被立即应用,而是会在累积到和同步全局Batch大小一致时聚合执行一次参数更新。于是计算节点不会被梯度更新阻塞,快节点可以消费更多的数据,慢节点只需要消费更少的数据,算力被充分调动。
对于每一步更新,所有的稠密层参数都会被更新,但是稀疏层参数(即Embedding参数)只有少数一部分被更新,两种参数的梯度过期程度是不一致的,因此比较难以用参数版本进行控制。我们这里将梯度过期程度统一定义为训练过程中数据的过期程度。数据的 staleness 表示某一个 worker 从开始训练这个它的 local batch 时的 global step 和它进行梯度更新时的 global step 的差距。同步训练过程中,数据的 staleness 始终为 0。基于数据 staleness,我们在 PS 架构上实现了 token-controled 的 GBA 机制,实现梯度聚合以及应对稀疏模型在异步训练过程中的梯度过期问题。
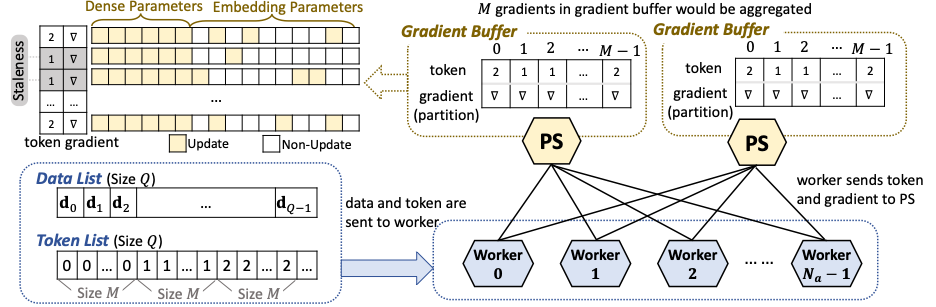
图4给出了GBA中最为核心的Token控制机制。在传统的PS角色上,我们设置了一个名为Token List的队列,该队列中包含了按序的Token,队列中每种Token初始为Worker数个。每次worker请求参数时会取得一个Token,在计算完梯度后,将Token和反向相关的数据全部传回PS。PS上还设置了一个Gradient Buffer,用户缓存梯度而不立即更新。每当累积到batch size和同步全局batch size一致时,PS会对Gradient Buffer中的梯度进行聚合并进行参数更新。Gradient Buffer里不会关注梯度来自于哪个Worker,但会关注Token版本。如果Buffer中的某个Token相较于当前Token List已经发出的最新Token已经落后大于一个给定阈值的版本数,那么我们认为这个梯度过期较为严重,需要丢弃而不是参与到梯度更新中。如此,GBA既保证了实际更新梯度时的Batch size,又避免了慢节点和严重过期的梯度带来的不利影响。
在论文中我们结合稀疏参数与稠密参数具有不同梯度延迟敏感性的特点进行了GBA的偏差分析,结合训练多步后的误差期望证明了GBA训练模式不会影响模型收敛性。
▐ GBA收敛性分析
业界有许多针对同步和异步训练收敛性分析的工作,我们参考了一些工作将同步的收敛性公式形式化为在训练了步后 error 的期望:
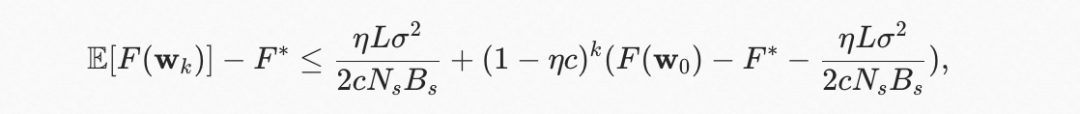
其中,表示第步的参数,表示 learning rate,表示 Lipschitz constant,表示梯度的标准差。是一个 empirical risk 函数,并且假设是 strongly convex 系数为 。是训练结果和最优解之间的 gap。公式中的第一项表示了 error 的上界,并且表示了 error 的衰减速率。
我们提出的 GBA 是一种基于异步梯度聚合的方案,我们假设当存在并且
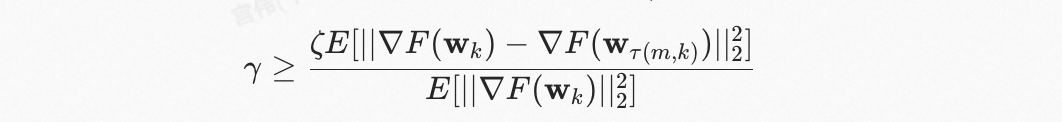
这里,是梯度过期带来参数更新影响的度量因子,更小的代表梯度过期对于模型效果的影响越小。除此之外,表示参数同时在第的 token index 和第的 token index 被更新的概率。对于一个稀疏模型,将是一个远小于 1 的数,并且对于 dense 参数这个数值为 1。GBA 的 error 公式可以表示为:
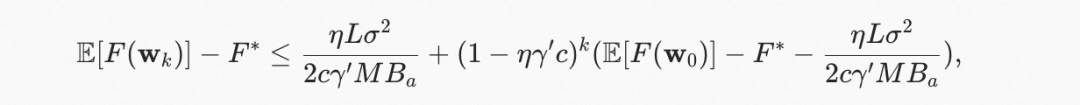
其中,并且 是 token index 等于 global step 的概率下界,即非梯度过期的概率下界,。
考虑同步和异步收敛性公式,如果将设置为与相近的数值,可以让 GBA 获得与同步相似的收敛特性。这也与我们 GBA 中设置的 global batch size 的方案一致。特别是对于稀疏模型,使得比 CV 或者 NLP 模型更小,那么在稀疏模型场景使用 GBA 也会获得和同步更小的收敛性差异。
▐ GBA工程实现
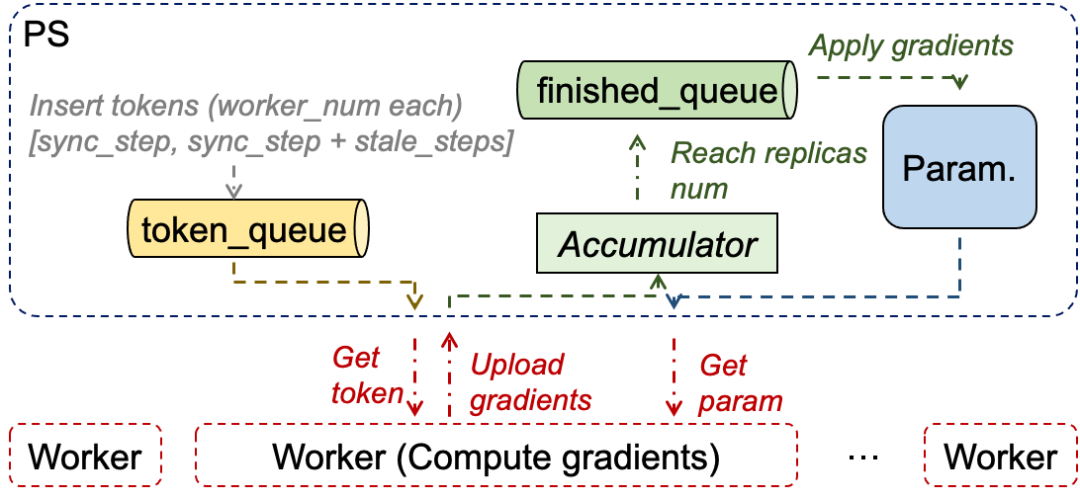
图5给出了GBA的整体工程实现架构。PS侧主要包括三部分逻辑:生成Token并根据token控制staleness(黄色部分逻辑)、累积梯度并异步聚合更新参数(绿色部分逻辑)、无等待响应worker请求(蓝色部分逻辑)。Worker侧主要流程(红色部分逻辑)是,每次请求参数和Token(依TF设计,训练第0步时无需请求token),在节点内计算获得梯度后,上传至PS,并无等待地开始下一个batch的流程。
1.如何保证GBA获得同步的效果和异步的速度?
首先 GBA 的梯度聚合并不要求梯度来自不同 worker,GBA 定义同一步梯度为参数两次更新之间任意 worker 发送的梯度。系统每步会发 worker_num 个 token,此步所有 token 均可由任意 worker 获取,即使存在超慢节点,此步 token 仍能被全部取走,触发下一步 token 分发。因此只要任务存在 worker 运行,token 生产与消费即可正常运转。GBA通过ps的梯度聚合操作保证梯度按照global batch更新,获得同步的效果;通过worker无需任何等待的执行任务,获得异步的速度。
2.GBA模式会不会丢很多梯度,速度和数据完整性如何权衡?
因为 token queue 是优先队列,任何 worker 取到的 token 均是当时队列最小 token。假设慢 worker 拿到 sync_step 后相对其他 worker 慢了 10 步,再次取 token,取到的是 sync_step + 10,因为 [sync_step + 1, sync + 9] 已被其他 worker 代跑。因此只有这个慢worker比其他快worker慢很多倍的情况下,才会出现梯度丢弃。但是由于这个慢worker的梯度过期严重,丢弃梯度也并非是一件坏事。并且对于每天大量样本的搜推广模型,少量梯度的丢弃也不会影响效果。
▐ GBA实验效果
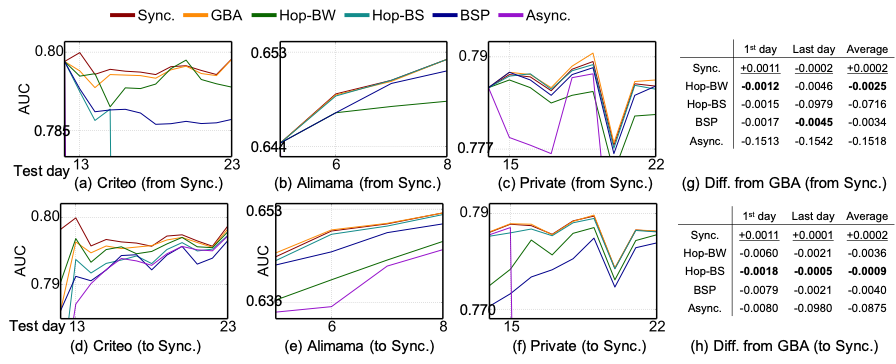
我们分别在Criteo-1TB数据集上实现了DeepFM、在阿里妈妈开源CTR数据集上实现了DIEN、在生产数据集上实现了简化的生产双塔模型,使用GBA和其他半同步/半异步方式进行训练,并与同步训练进行双向切换,以观察GBA的实际表现。图6展示了在切换发生后AUC的变化趋势。与保持同步训练相比,GBA的整体趋势相同,而其他方式则至少在某个任务上出现明显的降低,特别是切换自同步时,其他训练模式出现了明显的“重新收敛”的过程。从数据上看,在继承后第一天、数据集最后一天、多天均值三个指标上,GBA都取得了最佳的表现,实现了与同步训练之间的平滑切换。
在阿里巴巴集团内部,已有多个广告业务场景使用了GBA/同步切换的方式开展实验与迭代。在这些业务模型上,同步训练和GBA模式训练的离线效果是对齐的。从异步改为GBA/同步切换的训练范式后,在一些模型上我们观察到千分位上的AUC提升,这对于搜推广模型离线和在线效果的提升是非常显著的;同时继承参数续训已经不是唯一选择,从零开始训过去一年的数据仅需两周,使得GBA/同步切换成为了很受欢迎的方案。
▐ 未来展望
在GBA/同步切换的训练范式下,当模型版本改变需要大量回追数据训练时,使用高性能HPC资源执行训练,尽快拿到实验结果及模型参数;而在日常天级迭代或ODL训练时,则可以切换到GBA模式,利用普通计算节点执行训练及交付任务。特别是对于创新探索的场景,HPC同步+GBA的组合模式可以帮助算法工程师摆脱对“祖传参数”的强依赖,最大程度释放可探索的空间。当前,XDL也在设计自动化地进行训练模式迁移的方案,希望可以成为一种标准化普惠化的方案,服务于更多的大规模搜推广稀疏模型训练。欢迎对本篇工作以及搜推广算法迭代、训练框架等方面感兴趣的研究人员及工程师们与我们交流,我们非常期待能与大家一起探讨相关领域未来的发展方向,产出更多有价值的落地成果。
END

也许你还想看

喜欢要“分享”,好看要“点赞”哦ღ~
↓欢迎留言参与讨论↓


















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









