




 文章介绍了如何将Laf与Sealos云操作系统集成,通过Sealos模板市场部署Elasticsearch实现向量数据库,用于高效的知识库搜索。这种方法提升了Laf的后端能力和资源利用率,使其成为更强大的Serverless平台。
文章介绍了如何将Laf与Sealos云操作系统集成,通过Sealos模板市场部署Elasticsearch实现向量数据库,用于高效的知识库搜索。这种方法提升了Laf的后端能力和资源利用率,使其成为更强大的Serverless平台。
Laf 已成功上架 Sealos 模板市场,可通过 Laf 应用模板来一键部署!
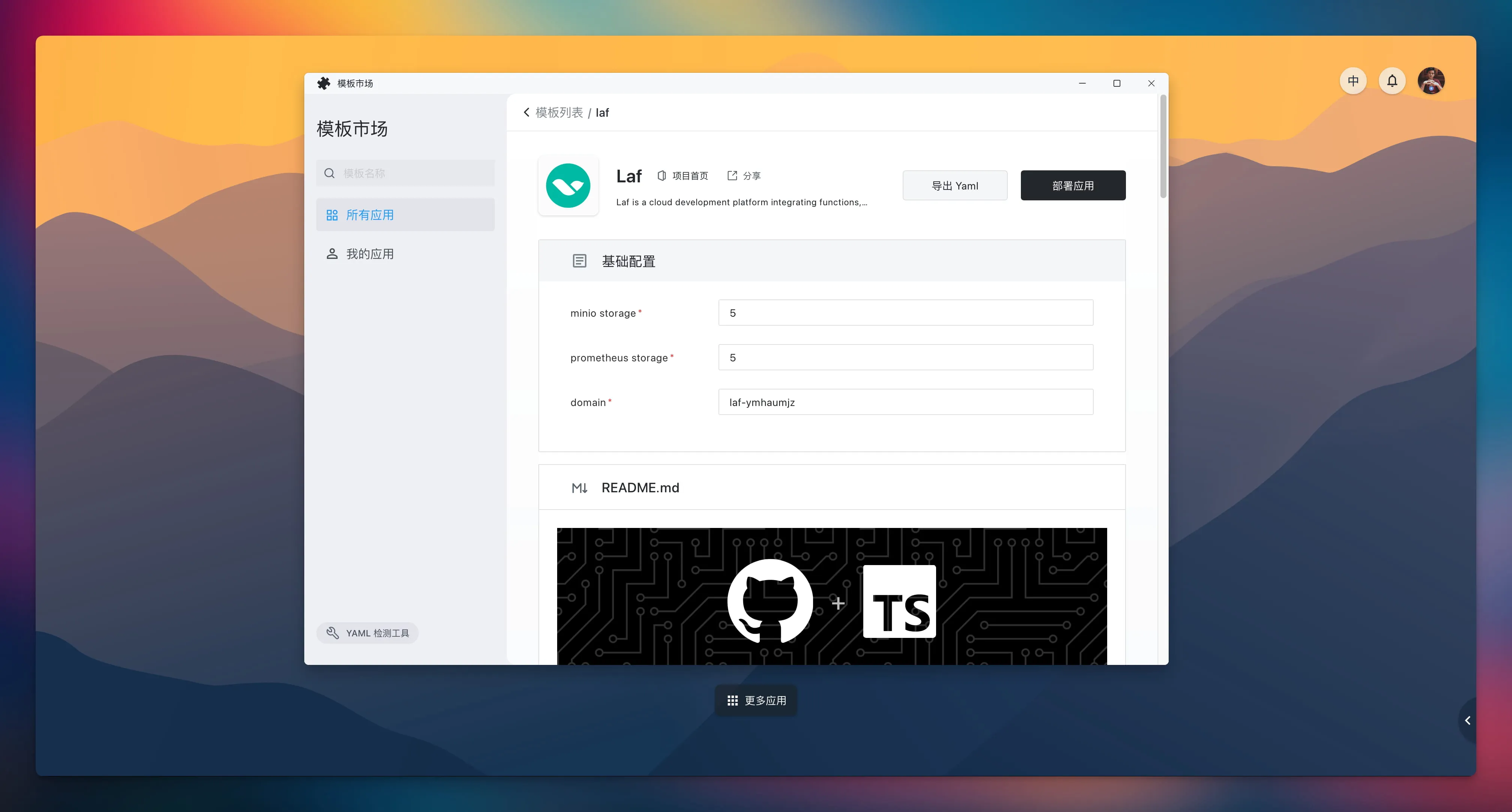
这意味着 Laf 在私有化部署上的扩展性得到了极大的提升。
Sealos 作为一个功能强大的云操作系统,能够秒级创建多种高可用数据库,如 MySQL、PostgreSQL、MongoDB 和 Redis 等,也可以一键运行各种消息队列和微服务,甚至 GPU 集群上线后还可以跑各种 AI 大模型。
将 Laf 一键部署到 Sealos 中,我们就可以在 Laf 中直接通过内网调用 Sealos 提供的所有这些能力。无论用户需要什么样的后端支持,只需在 Sealos 上运行相应的服务即可。这种集成模式不仅提高了资源的利用效率,而且还提供了无缝的技术集成,使得 Laf 成为一个更加强大和多功能的 Serverless 平台,弥补了传统 Serverless 平台在后端能力方面的不足。
Sealos 强大的模板市场提供了丰富的应用生态,用户可以在模板市场中一键部署各种应用。本文以 Elasticsearch 为例,展示如何在 Laf 中调用 Sealos 模板市场中部署的 Elasticsearch 来搭建一个向量数据库,提供定制化知识库搜索能力。
背景知识
如果我们想往大模型里边注入知识,最先能想到的就是对大模型进行微调,大模型有很好的根据上文来回答问题的能力。
假设一个场景,我有个问题是:“请给我介绍一下万能青年旅店这支乐队 “(假设模型内部并没有存储万青的相关信息),然后我有个 100w 字的文档,里边包含了世界上所有乐队的介绍。如果模型对无限长的输入都有很好的理解能力,那么我可以设计这样一个输入 “以下是世界上所有乐队的介绍:[插入 100w 字的乐队简介文档],请根据上文给我介绍一下万青这支乐队”,让模型来回答我的问题。但模型支持的输入长度是很有限的,比如 ChatGPT 只支持 32K Token 长度的输入 (大约 50 页文本)。
实际上,如果想让大模型根据文档来回答问题,必须要精简在输入中文档内容的长度。一种做法是,我们可以把文档切成若干段,只将少量的和问题有关的文档片段拿出来,放到大模型的输入里。至此,”大模型外挂数据库 “的问题转换成了 “文本检索的问题” 了,目标是根据问题找出文档中和问题最相关的片段,这已经和大模型本身完全无关了。
文本检索里边比较常用的是利用向量进行检索,我们可以把文档片段全部向量化 (通过语言模型,如 bert 等),然后存到向量数据库 (如 Annoy、FAISS、hnswlib 等) 里边,来了一个问题之后,也对问题语句进行向量话,以余弦相似度或点积等指标,计算
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2482
2482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









