







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
本文记录学习RNN-LSTM-GRU-Attention-self Attention-transformer的过程及遇到的问题。
一、RNN
1.为什么需要RNN?
将神经网络模型训练好之后,在输入层给定一个x,通过网络之后就能够在输出层得到特定的y,那么既然有了这么强大的模型,为什么还需要RNN(循环神经网络)呢?
比如:苹果 一词多义,利用之前的模型只是把单词的特征向量输入模型中,语料库中**有的是水果,有的是公司,**这将导致模型在训练的过程中,预测的准确程度,取决于训练集中哪个label多一些,这样的模型对于我们来说完全没有作用。
即没有结合上下文去训练模型,而是单独的训练apple这个单词的label。
过渡:在使用RNN之前,语言模型主要是采用N-Gram,N可以是一个自然数,比如2,或3,他的含义是假设一个词出现的概率只与前面N个词相关。
如果我们想处理任一长度的句子,N设置多少都不合适;另外模型的大小和N的关系是指数级的,4-GRAM的模型就会占用海量的存储空间。并且N-gram无法捕捉序列之间的顺序关系,而顺序关系是处理NLP任务中的重要组成部分。(N-gram自己可以找其他资料查看,这里不多赘述。)
于是就有了RNN。
RNN是神经网络的一种,对具有序列特性(符合时间顺序、逻辑顺序或者其他顺序就叫序列特性
比如人类的语言是不是复合某个逻辑或规则的字词拼凑起来的等等)的数据非常有效,它能挖掘数据中的时序信息以及语义信息,可以解决语音识别、语言模型、机器翻译以及时序分析等NLP任务。
2.结构及原理
下图左边是一个简单的循环神经网络:由输入层、隐藏层和一个输出层组成。
U是输入层到隐藏层的权重矩阵,o也是一个向量,它表示输出层的值;V是隐藏层到输出层的权重矩阵。
W是什么?权重矩阵W是隐藏层上一次的值作为这一次的输入的权重。
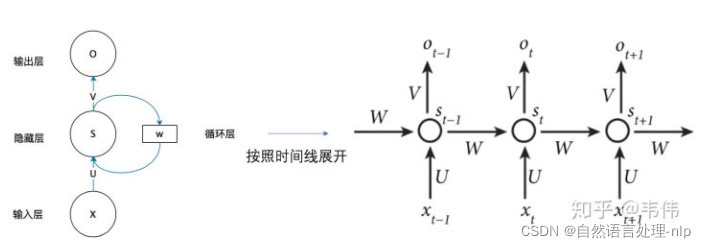
公式:
按照时间线展开为右边的图:
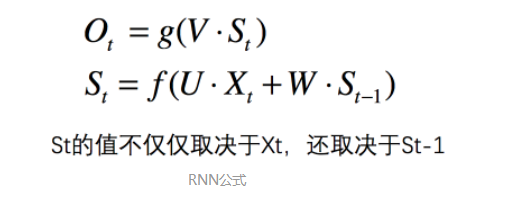
RNN 可以记住每一时刻的信息,每个时刻都会把隐藏层的值存下来,到下一时刻的时候再拿出来用,这样保证每一时刻都含有上一时刻的信息。每一时刻的隐藏层不仅由该时刻的输入层决定, 还由上一时刻的隐藏层决定。
在整个训练过程中,每一时刻所用的都是同样的W。
注意:
1. 这里的W,U,V在每个时刻都是相等的(权重共享).
2. 隐藏状态可以理解为: S=f(现有的输入+过去记忆总结)
3.优缺点
RNN特点:
(1)权值共享;
(2)前面的输出会影响后下的输出;
(3)损失会随着序列的推荐不断积累;
(4)善于进行短期记忆,不擅长长期记忆;
RNN问题及解决方案:
梯度消失和梯度爆炸
原因:当序列很长的时候,所得到的的每一个位置/参数的梯度在累积之后会逐渐趋于0或者逐渐地趋于正无穷,即梯度消失和梯度爆炸。(相对于梯度爆炸,梯度消失的问题更严重一些)
原因:
在BPTT计算w偏导的过程中:有一个连乘项,建模了序列的长度依赖关系。这个连乘项(最好是在1附近)也是导致梯度消失/梯度爆炸的原因。
解决方案:
[针对梯度爆炸]:
梯度截断(给梯度限定一个值)能够在一定程度上解决梯度爆炸的问题,不能解决梯度消失的问题。
[针对梯度消失]:
1.采用Relu作为激活函数
2.选择某些timestep不更新隐状态( dropout)
二、LSTM
1.为什么需要LSTM?
为了解决RNN短时记忆的问题,出现了LSTM。
2.结构及原理
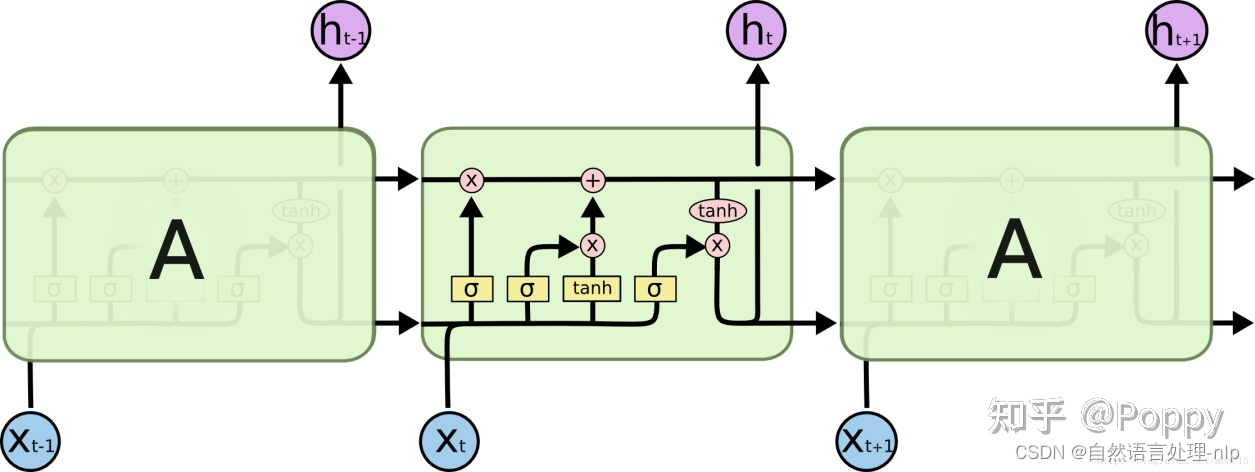
下面是对LSTM单元内各部分的理解:
LSTM的关键是单元状态(cell state),即图中LSTM单元上方从左贯穿到右的水平线,它像是传送带一样,将信息从上一个单元传递到下一个单元,和其他部分只有很少的线性的相互作用。
LSTM通过“门”(gate)来控制丢弃或者增加信息,从而实现遗忘或记忆的功能。“门”是一种使信息选择性通过的结构,由一个sigmoid函数和一个点乘操作组成。sigmoid函数的输出值在[0,1]区间,0代表完全丢弃,1代表完全通过。一个LSTM单元有三个这样的门,分别是遗忘门(forget gate)、输入门(input gate)、输出门(output gate)。
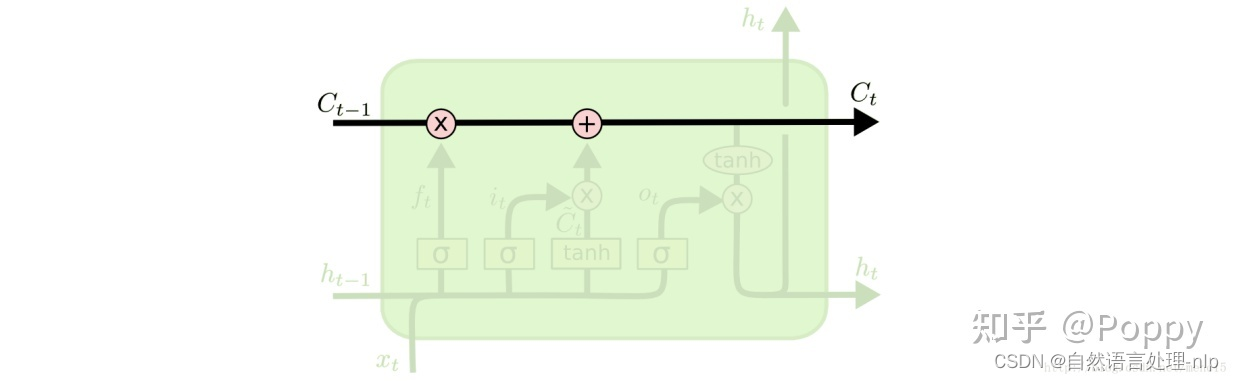
遗忘门(forget gate):遗忘门是以上一单元的输出 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/620cb02158bcd077e82953e6ed8ec971.png) 和本单元的输入Xt为输入的sigmoid函数,为
和本单元的输入Xt为输入的sigmoid函数,为 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/6689ccdc7aca1b4c342a8685b6f8db0e.png) 中的每一项产生一个在[0,1]内的值(可看做概率值),来控制上一单元状态被遗忘的程度。
中的每一项产生一个在[0,1]内的值(可看做概率值),来控制上一单元状态被遗忘的程度。
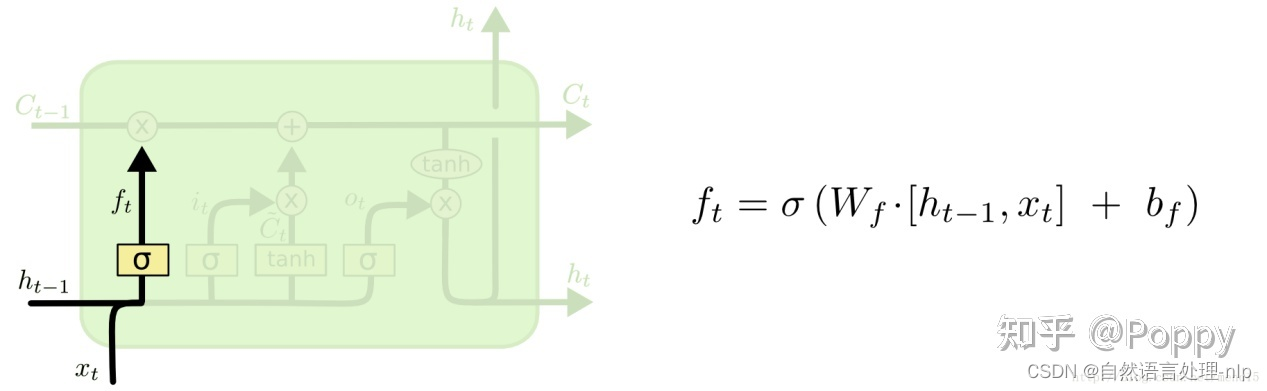
输入门(input gate):输入门和一个tanh函数配合控制有哪些新信息被加入。tanh函数产生一个新的候选向量 ,输入门为 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/bd451e919b97d7a82113f8ac977f5205.png) 中的每一项产生一个在[0,1]内的值,控制新信息被加入的多少。至此,我们已经有了遗忘门的输出
中的每一项产生一个在[0,1]内的值,控制新信息被加入的多少。至此,我们已经有了遗忘门的输出 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/efa8d0abb114d361f5c0c16e90b8e77e.png) ,用来控制上一单元被遗忘的程度,也有了输入门的输出
,用来控制上一单元被遗忘的程度,也有了输入门的输出![[公式]](https://i-blog.csdnimg.cn/blog_migrate/1e3736a4c6d4658d657100fefa3852b8.png) ,用来控制新信息被加入的多少,我们就可以更新本记忆单元的单元状态了。
,用来控制新信息被加入的多少,我们就可以更新本记忆单元的单元状态了。
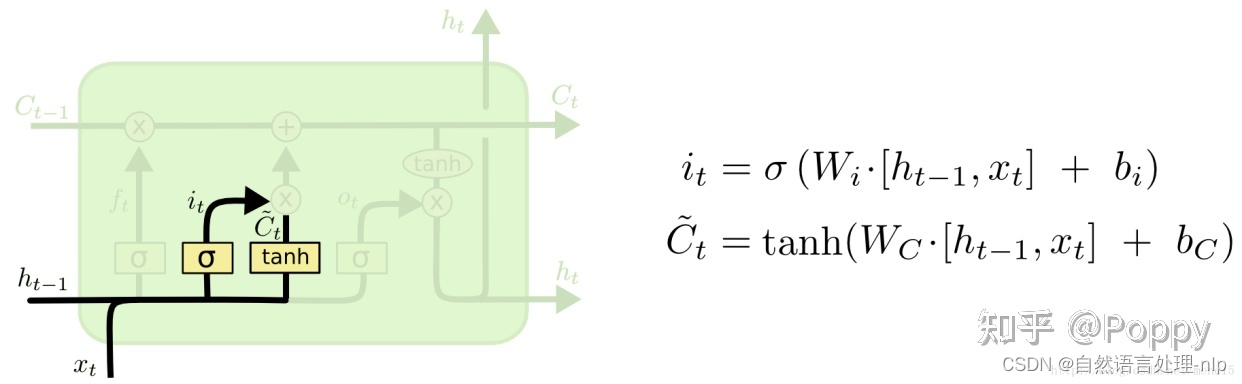
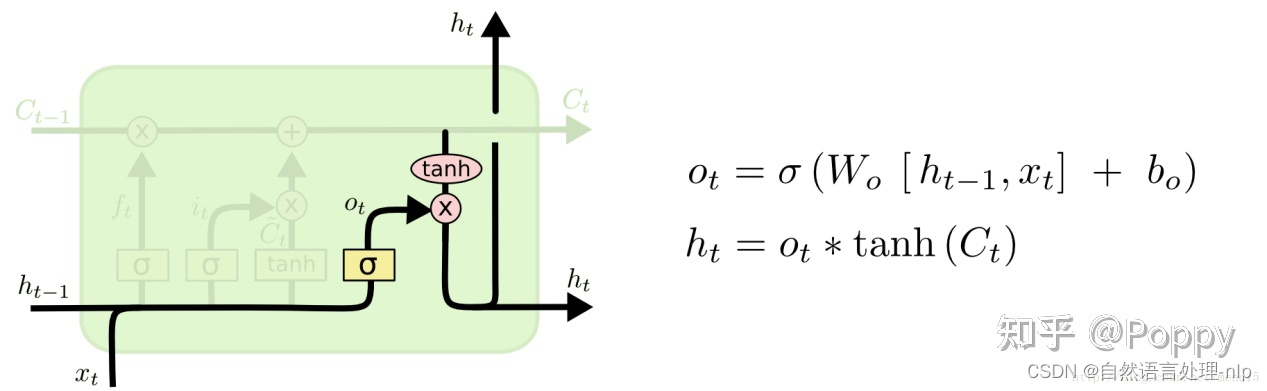
输出门(output gate):输出门用来控制当前的单元状态有多少被过滤掉。先将单元状态激活,输出门为其中每一项产生一个在[0,1]内的值,控制单元状态被过滤的程度。
通俗来说,LSTM的3个门就是通过3个[0,1]之间类似于概率的数值来有选择地过滤旧的信息 、新加入的信息
、新加入的信息
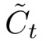 和当前单元状态的全部信息
和当前单元状态的全部信息 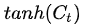 的操作。
的操作。
长期记忆构造细节:
负责基于历史细胞状态和“遗忘门”的情况,计算得到主要内容为长期记忆的向量。
长期记忆模块的结构特点是,只经过遗忘门的一次处理,因此衰减较少、得以保留较多的历史信息——这是LSTM拥有较强的长依赖刻画能力的秘诀。
短期记忆构造细节:
相比RNN,这里增加了一个“输入门”,用来控制对原始短期记忆进行“加工提纯”(一个线性变换,将原始记忆信息向量投射到新的空间里,以便下游模块更容易理解)。
综合长短期记——输出模块:
负责综合考虑长期记忆和短期记忆,得到当前细胞状态,并基于输出门的情况,计算隐藏状态和输出值。在这个模块中,我们构造了第3个门控信号,用来对细胞状态中蕴含的信息进行加权。
3.优缺点
解决了RNN短时记忆的缺点,缓解了RNN的梯度消失,但也因为引入了很多内容,导致参数变多,也使得训练难度加大了很多。因此很多时候我们往往会使用效果和LSTM相当但参数更少的GRU来构建大训练量的模型。
三、GRU
1.为什么需要GRU?
相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
2.结构及原理
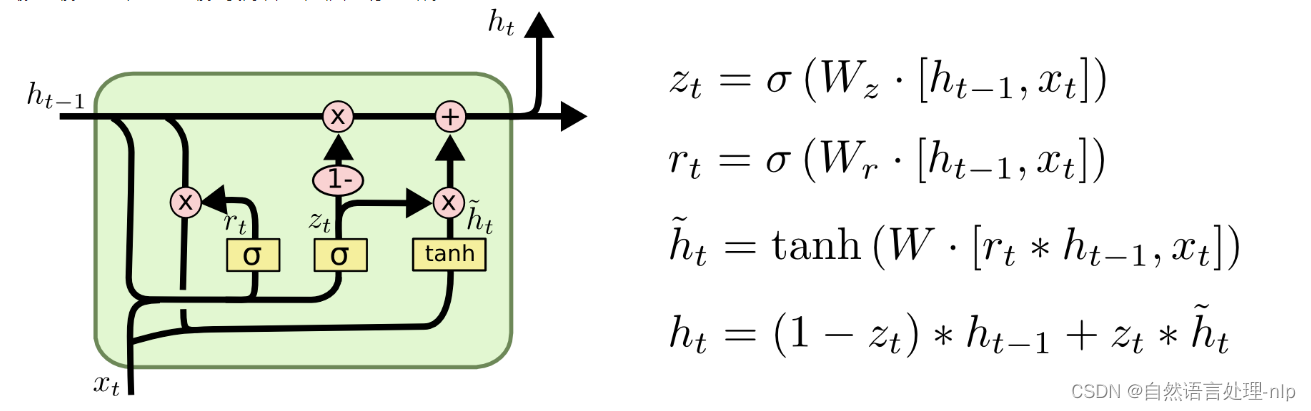
GRU将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的LSTM模型要简单,也是非常流行的变体。
共两个门重置门和更新门。重置门决定了如何将新的输入信息与前面的记忆相结合,更新门定义了前面记忆保存到当前时间步的量。
总结
LSTM与RNNs一样比CNN能更好地处理时间序列的任务;同时LSTM解决了RNN的长期依赖问题,并且缓解了RNN在训练时反向传播带来的“梯度消失”问题。
LSTM本身的模型结构就相对复杂,训练比起CNN来说更加耗时;此外,RNN网络的特性决定了它们不能很好的并行化处理数据;再者,LSTM虽然一定程度上缓解了RNN的长期依赖问题,但对于更长的序列数据,LSTM也是很棘手的。
很多时候我们往往会使用效果和LSTM相当但参数更少的GRU来构建大训练量的模型。
参考:https://zhuanlan.zhihu.com/p/406408470?ivk_sa=1024320u
下一篇:seq2seq-attetion-self attention-transfomer

















 1178
1178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









