




- 近年来循环神经网络在自然语言处理,语音技术,甚至图像方面都有不错的应用。本文主要介绍基础的RNN,RNN所面对的问题,以及RNN的改进版本:LSTM和GRU
RNN(Recurrent Neural Network)
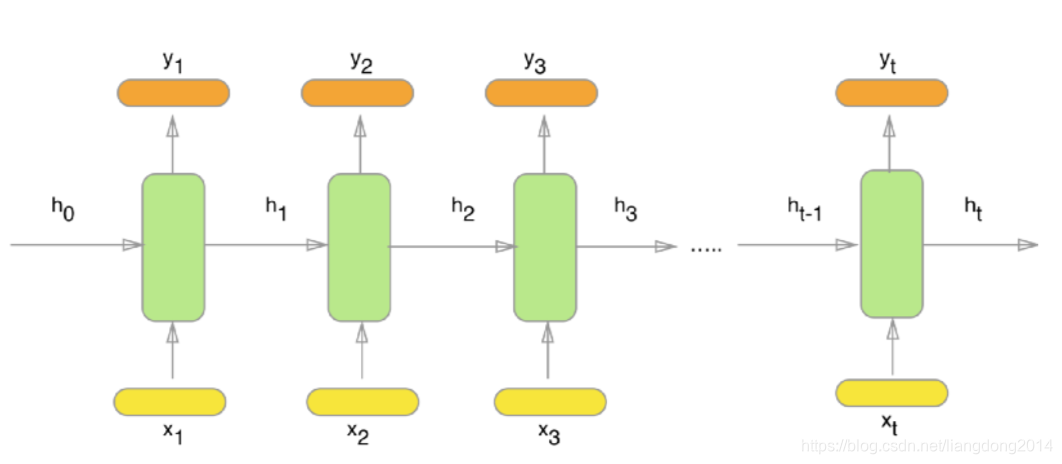
- 我们先放一张RNN的结构图,一般的RNN也遵循这个过程。输入是x1~xt,绿色的方框表示处理单元, h i h_i hi表示的是隐藏单元, y i y_i yi表示的是输出。对于不同的输入 x i , h i x_i,h_i xi,hi,RNN的cell(一个绿色框)都是彼此之间共享参数的。
- 一般来说RNN的计算过程分成下面的步骤:
- 构造数据,形成{x1,x2, …, xt}的sample
- 将 x i x_i xi输入给第 i i i个单元,进行计算,分别得到 y i , h i y_i, h_i yi,hi
- 重复上述第二步,得到 y 0 , . . . , y n y_0,...,y_n y0,...,yn,计算loss
- 反向传播,更新绿色框中的参数
- 重复1~4,直到网络收敛
- 那么绿色框中到底是什么呢?他是怎么做到记录了上一个输入的信息呢?
- Standard RNN Cell
- 标准的RNN cell如下图所示,它里面其实就是封装了一层神经网络和一个非线性处理单元。
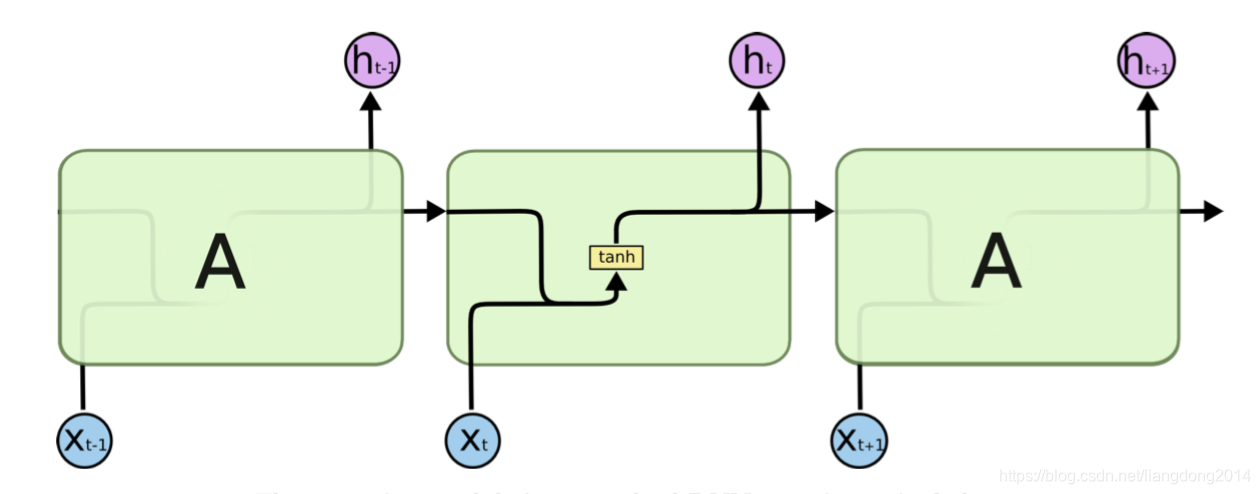
- 公式化如下:
- h i = f ( W h h h i − 1 + W h x x i ) h_i = f(W^{hh}h_{i-1} + W^{hx}x_i) hi=f(Whhhi−1+Whxxi),其中 f f f代表非线性激活函数,例如sigmoid(下面会以其举例说明RNN缺点)。
- y i = s o f t m a x ( W y h i ) y_i = softmax(W^{y}h_i) yi=softmax(Wyhi),其中y是输出。
- 它是怎么记下过去的信息的呢?是通过隐藏状态 h i h_i hi记下的。我的理解是是因为我们通过BP优化的是它,所以赋予了 h i h_i hi这么个意义,至于怎么证明 h i h_i hi就是过去的信息,还有待探索。
- 缺点:如果输入sample里面时刻太长的话,可能会导致梯度消失,从而忘记很早时刻的信息。
- 为了从数学的角度说明上面那一点,我们就先从BP推导起来。
- 假设 E E E表示损失函数,令 s = W y h , y i = s o f t m a x ( s i ) s=W^{y}h, y_i=softmax(s_i) s=Wyh,yi=softmax(si)
- ∂ E ∂ W h h = ∑ i = 1 k ∂ E ∂ y ∗ ∂ y ∂ s ∗ ∂ s ∂ h i ∗ ∂ h i ∂ W h h \frac{\partial E}{\partial W^{hh}}=\sum_{i=1}^k{\frac{\partial E}{\partial y} * \frac{\partial y}{\partial s} * \frac{\partial s}{\partial h_i} * \frac{\partial h_i}{\partial W^{hh}}} ∂Whh∂E=∑i=1k∂y∂E∗∂s∂y∗∂hi∂s∗∂Whh∂hi
- 其中 i i i表示的第i时刻, k k k表示的是一共有 k k k个时刻。
- 我们知道,在计算第 i i i时刻的梯度的时候,它与 i + 1 − > k i+1->k i+1−>k时刻都有关系。并且这种关系表现在梯度上是惩罚的关系。所以我们可以得到下面的等式
- ∂ s ∂ h i = Π j = i + 1 k ∂ h j ∂ h j − 1 = Π j = i + 1 k f ′ ( h j ) \frac{\partial s}{\partial h_i} = \Pi_{j=i+1}^k{\frac{\partial h_j}{\partial h_{j-1}}}=\Pi_{j=i+1}^k{f'(h_j)} ∂hi∂s=Πj=i+1k∂hj−1∂hj=Πj=i+1kf′(hj)
- 正如我们上面所说,f(x) = sigmoid,其导数范围在0~1之间,如果我们有多个小数相乘的话,就会导致梯度为0,从而导致梯度消失。
- 注意,我们这里的梯度消失只是针对比较靠前的输入来说,说明其输入没有起到合适的作用(梯度为0)。但是对于靠后的输入来说梯度还是存在的。因为观察上面的公式我们就可以得到靠后的梯度j~k连乘的次数少。
- 至此,我们说了 W h h W_{hh} Whh在long sequence的传播过程中是如何产生梯度消失问题的。注意 W y W_{y} Wy应该是不会有这个问题的。因为它一般只会更新一次(如果我们只用 y k y_k yk去计算loss的话)。同理 W h x W_{hx} Whx也是会存在这个问题的。
- 如何解决梯度消失问题呢?sigmoid既然梯度为0,那么relu呢?relu可能会导致梯度爆炸问题。因为relu(x) = x,他没有限制x的取值范围。此外relu的导数是一个常数,他不会随着x的变化而变化。sigmoid通过限制输出的大小,从而限制的整个网络的幅度。那么如何结合relu的问题的?可以使用Batch Normalization, 参考这篇博文。
- 请看下面LSTM和GRU的解决方案。
- 标准的RNN cell如下图所示,它里面其实就是封装了一层神经网络和一个非线性处理单元。
LSTM (Long Short-term Memory)
- 正如上面说的普通的RNN会导致梯度消失的问题,那么LSTM是如何解决的呢?
- 我们先放一张LSTM的cell,如下图所示
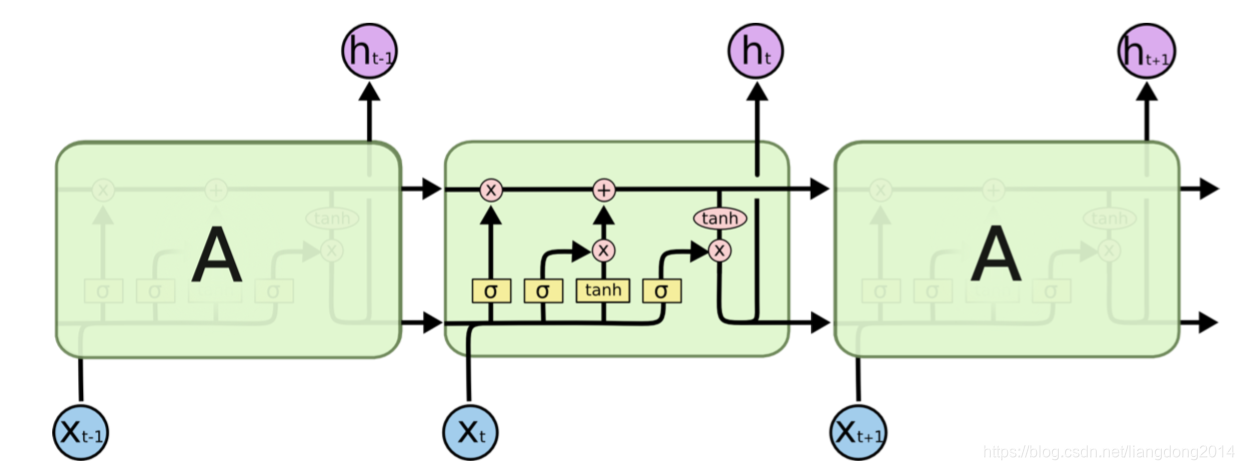
- LSTM Cell里面有如下几个重要的概念(四门一态):
- forget gate
- input gate
- update gate
- output gate
- Cell state
- forget gate:生成一个mask,决定cell state里面哪些信息应该被遗忘,哪些信息应该被保留。forget可以看成是对cell stage的forget。
- 其是由
h
i
,
x
i
,
s
i
g
m
o
i
d
h_i, x_i, sigmoid
hi,xi,sigmoid组成,如下图所示
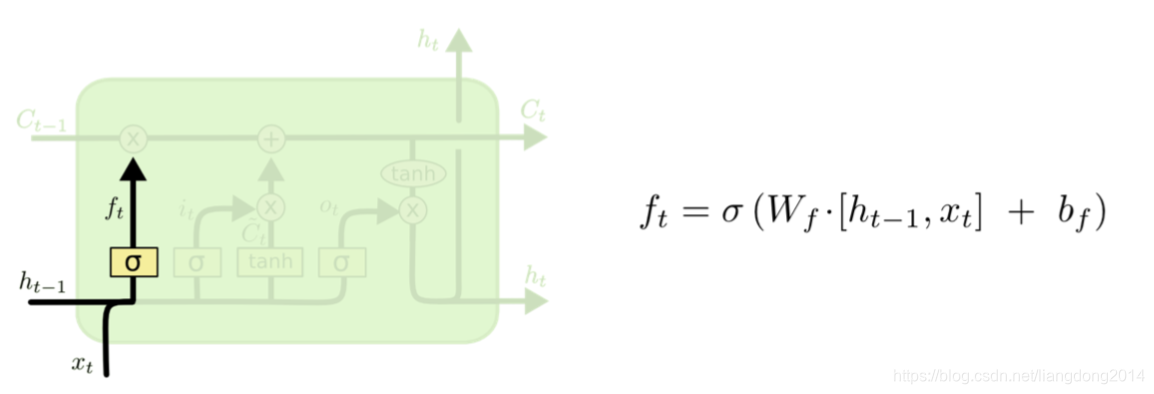
- 其中f_t就代表forget gate的输出,它表示了我们要选择性的遗忘cell state里面的某些值(对应位置的f_t为0或者是低响应区域)。
- 从公式的角度来看: f t = W f h h i − 1 + W f x x i f_t = W_{fh}h_{i-1} + W_{fx}x_i ft=Wfhhi−1+Wfxxi
- 其是由
h
i
,
x
i
,
s
i
g
m
o
i
d
h_i, x_i, sigmoid
hi,xi,sigmoid组成,如下图所示
- input gate:决定新的输入中哪些信息应该被加入的cell state中。所以input可以看成是对cell state的输出。
- 其是由 h i − 1 , x i , s i g m o i d h_{i-1}, x_i, sigmoid hi−1,xi,sigmoid组成,可以看成和forget gate结构一样,但是彼此不共享参数。
- 其结构图如下所示,
C
i
^
\hat{C_i}
Ci^表示一个新的cell state候选值,其和
i
i
i_{i}
ii点乘从而决定哪些信息应该被加入新的cell state中。
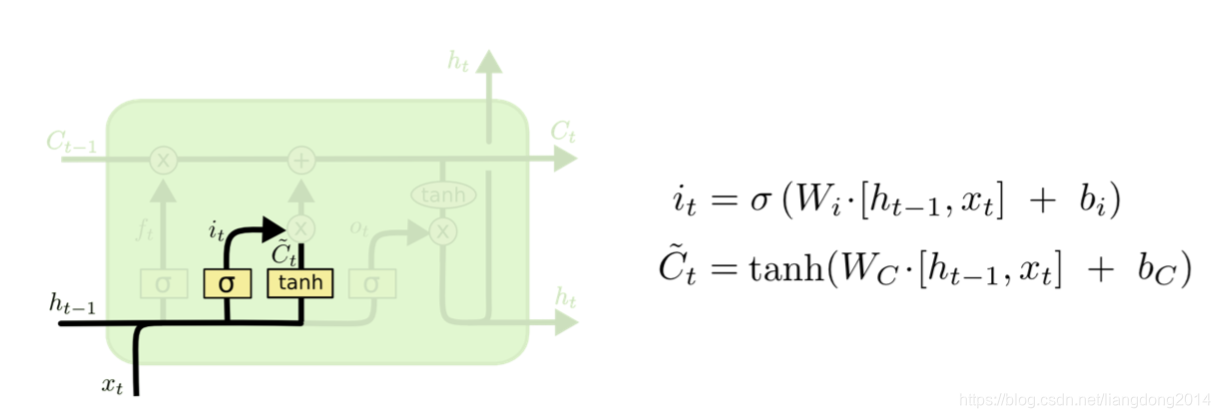
- 数学公式表示: i i = s i g m o i d ( W i h h i − 1 + W i x x i ) , C i ^ = t a n h ( W c h h i − 1 + W c x x i ) i_i=sigmoid(W_{ih}h_{i-1} + W_{ix}x_i), \hat{C_i} = tanh(W_{ch}h_{i-1} + W_{cx}x_i) ii=sigmoid(Wihhi−1+Wixxi),Ci^=tanh(Wchhi−1+Wcxxi)。而这里为什么使用tanh还有待探索。tanh相对于sigmoid是0均值的。
- update gate:更新Cell state
- 其是对f和C作点乘,得到过滤掉信息的C,再对其加上因为本次输入需要添加的信息。
- 结构图如下所示
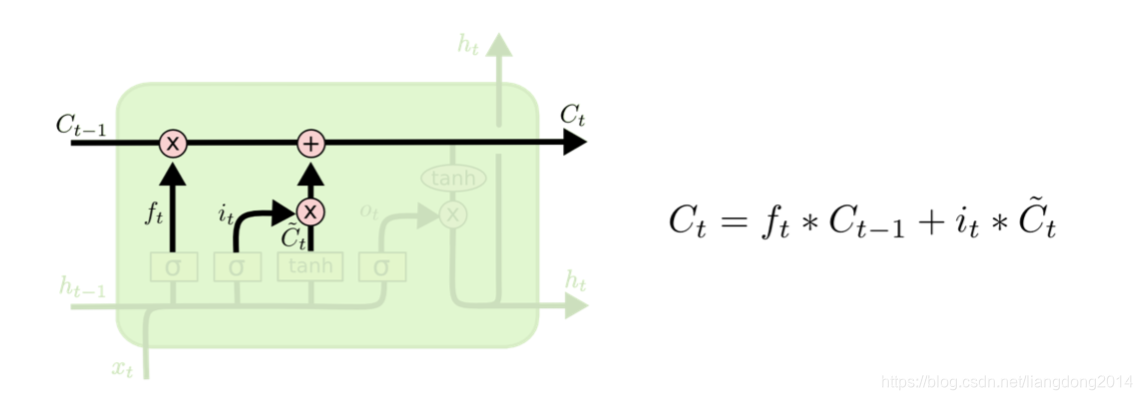
- 数学公式表示: C i = C i − 1 ∗ f i + i i ∗ C ^ i C_i = C_{i-1} * f_i + i_{i} * \hat{C}_i Ci=Ci−1∗fi+ii∗C^i,前者表示删去应该遗忘的信息后保存下来的信息,后者表示应该加上去的信息。
- output gate:生成我们的hidden state
- 其是由h_{i-1}, x_i 和 cell state的非线性映射进行点积运算得到的。
- 其网络结构图如下所示:
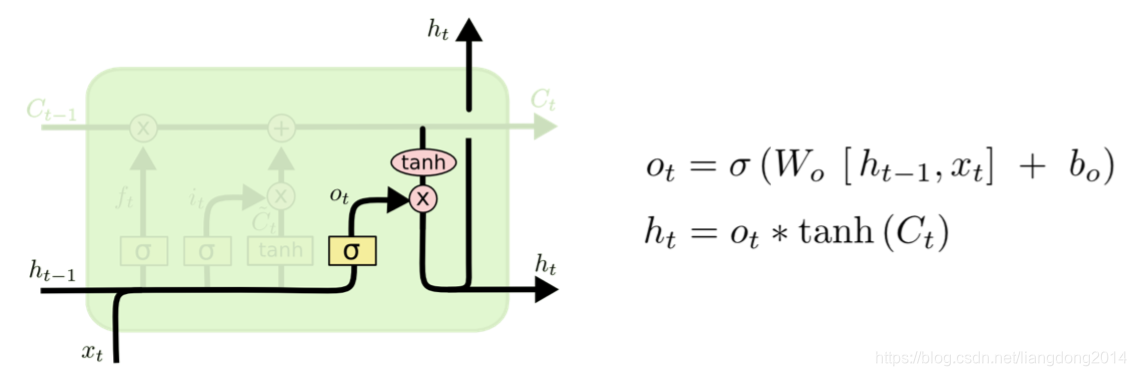
- 数学表示: h i = s i g m o i d ( W o h h t − 1 + W o x x i ) ∗ t a n h ( C i ) h_i = sigmoid(W_{oh}h_{t-1}+W_{ox}x_i)*tanh(C_i) hi=sigmoid(Wohht−1+Woxxi)∗tanh(Ci)
- 其是怎么解决在recurrent过程中出现的梯度消失问题呢?
- 简单来说,在对 W o h , W o x W_{oh},W_{ox} Woh,Wox计算导数的过程中,我们的 W o h , W o x W_{oh}, W_{ox} Woh,Wox计算导数就会有两部分,前者是连城,后者是加分,有一个C在里面,加分从而避免了梯度消失。比如 h i = s i g m o i d ( W o h h i − 1 + W o x x i ) ∗ t a n h ( C i ) = s i g m o i d ( W o h ( s i g m o i d ( W o h h i − 2 + W o x x i − 1 ) ∗ t a n h ( C i − 1 ) ) + W o x x i ) ∗ t a n h ( C i ) h_i=sigmoid(W_{oh}h_{i-1} + W_{ox}x_i)*tanh(C_i) = sigmoid(W_{oh}{(sigmoid(W_{oh}h_{i-2} + W_{ox}x_{i-1})*tanh(C_{i-1}) )} + W_{ox}x_i)*tanh(C_i) hi=sigmoid(Wohhi−1+Woxxi)∗tanh(Ci)=sigmoid(Woh(sigmoid(Wohhi−2+Woxxi−1)∗tanh(Ci−1))+Woxxi)∗tanh(Ci)
- 复杂来讲有待探索。。
- LSTM Cell里面有如下几个重要的概念(四门一态):
GRU (Gated recurrent unite)
- 我们上面讲了LSTM是如何的结构,接下来我们看一下GRU是怎么样的结构。
- 相对于LSTM的cell,GRU相对能简单一些。
- 首先GRU没有cell state的概念,它将信息一直保存在hidden state中。
- 其次,最后GRU的输出也是由两部分组成,一部分是上一层hidden state保存下来的有用信息(第一部分),一部分是这层新的hidden hidden state应该被加入的信息(两者取并集)(第二部分)。
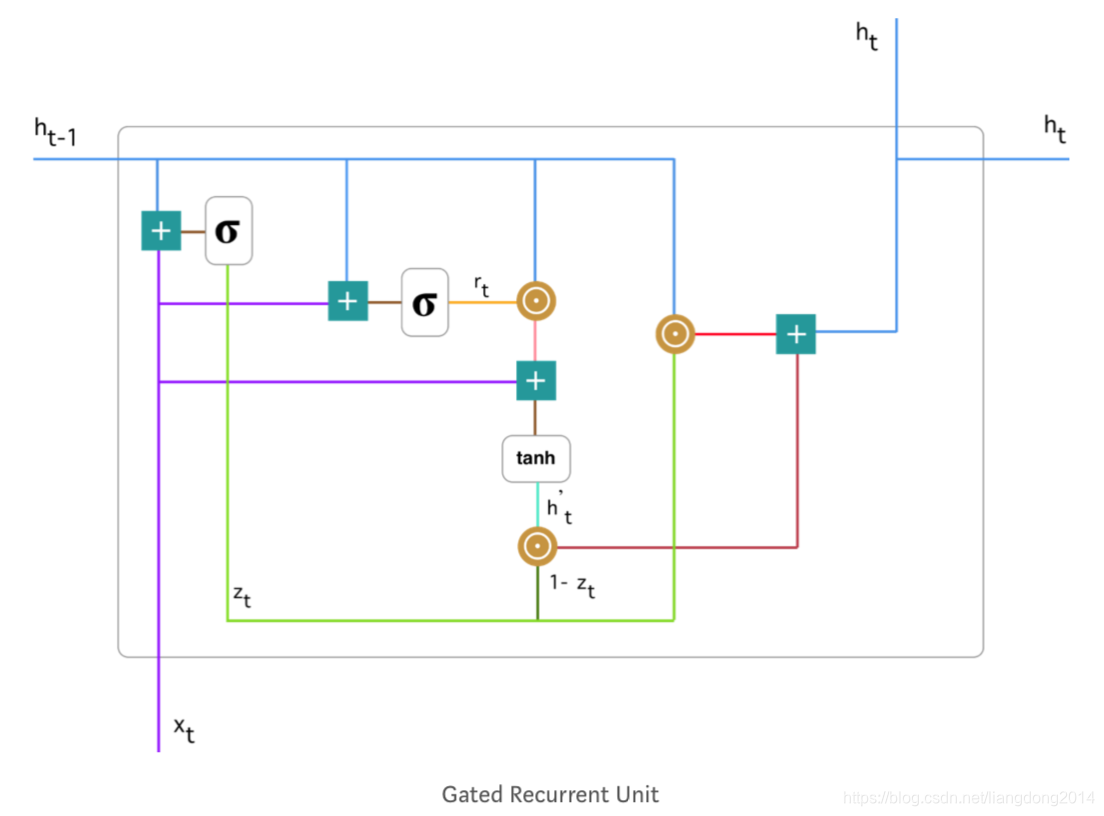
- GRU由update gate,reset gate,current content gate,output gate四部分组成。
- update gate:决定上一个hideen state中哪些信息应该被保留,有点像LSTM中的forget gate
- 其结构图如下所示:
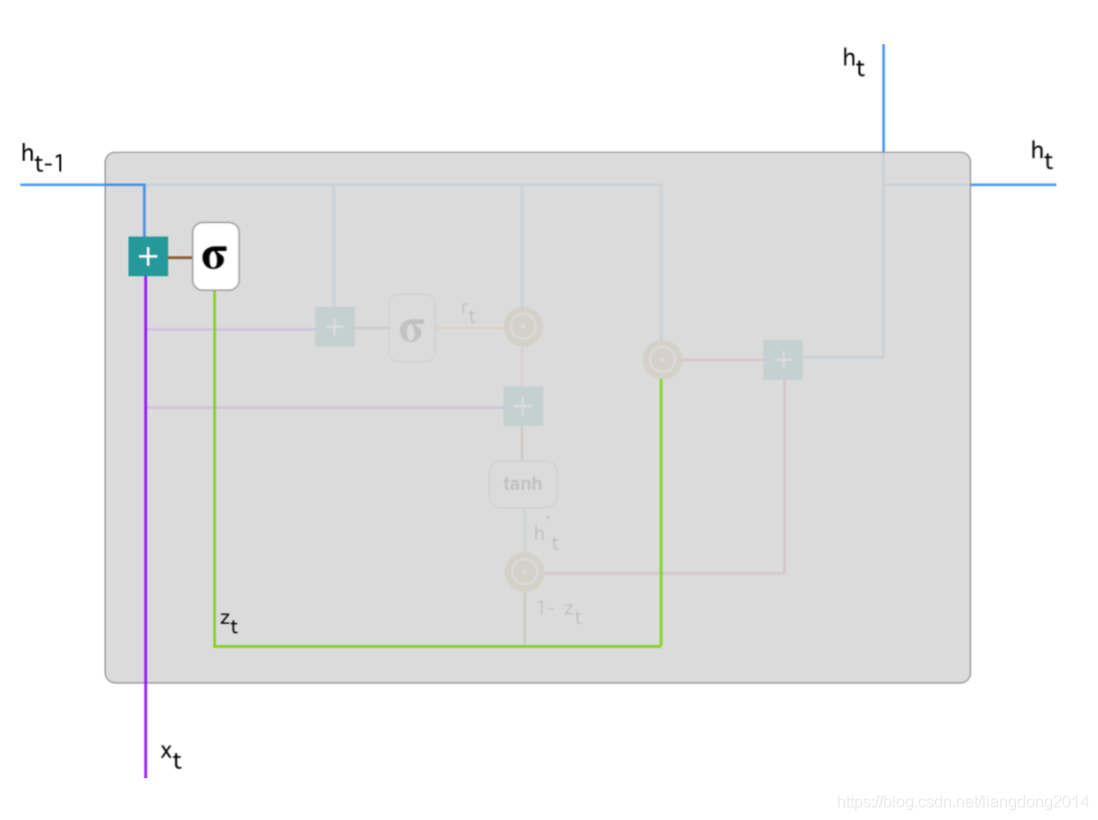
- 公式化: z t = W z h h t − 1 + W z x x t z_t = W_{zh}h_{t-1} + W_{zx}x_t zt=Wzhht−1+Wzxxt
- 其结构图如下所示:
- reset gate:决定上一个state 的哪些信息应该被重置。他与update gate不同的是,update gate主要是用在第一部分。而这里的reset gate主要用在生成第二部分。
- 其网络结构图如下所示:
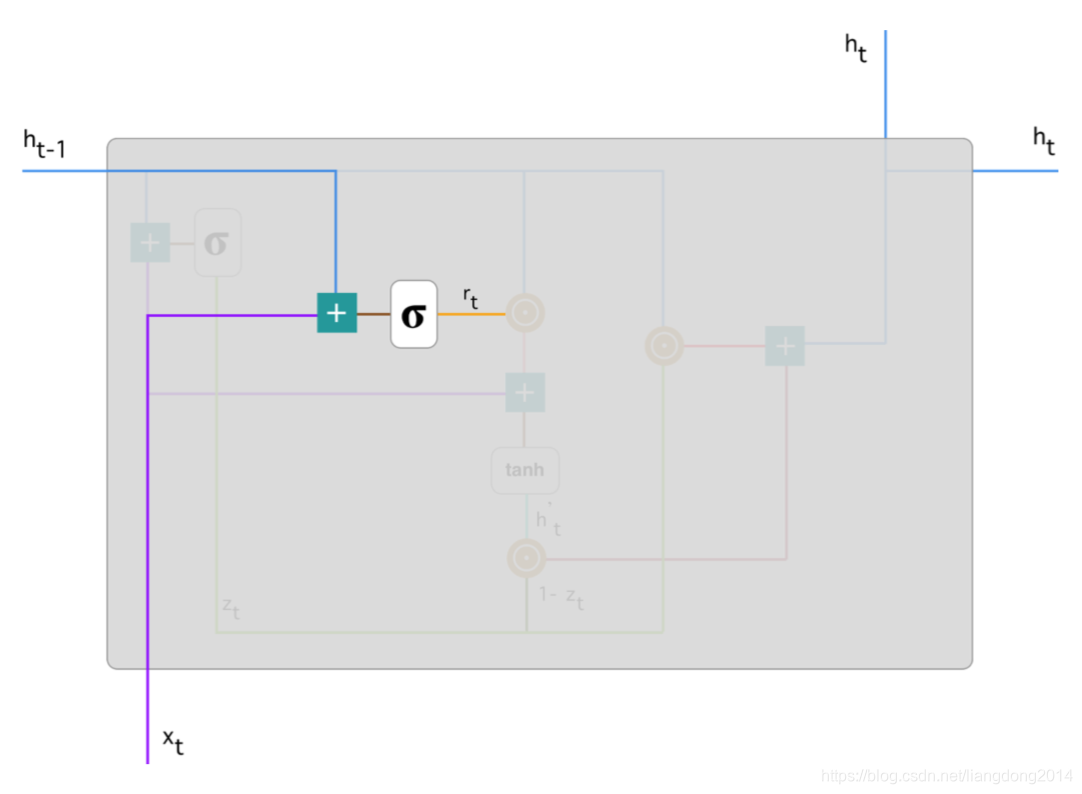
- 其网络结构和update gate基本一致,不共享参数,拥有相同结构。
- 数学公式表达: r t = W r h h t − 1 + W r x x t r_t = W_{rh}h_{t-1} + W_{rx}x_t rt=Wrhht−1+Wrxxt
- 其网络结构图如下所示:
- current content gate: 主要是生成本cell的state(注意和输出的state不同,更“隐蔽“,有点像LSTM 里面的cell state)。
- 其结构如下所示:
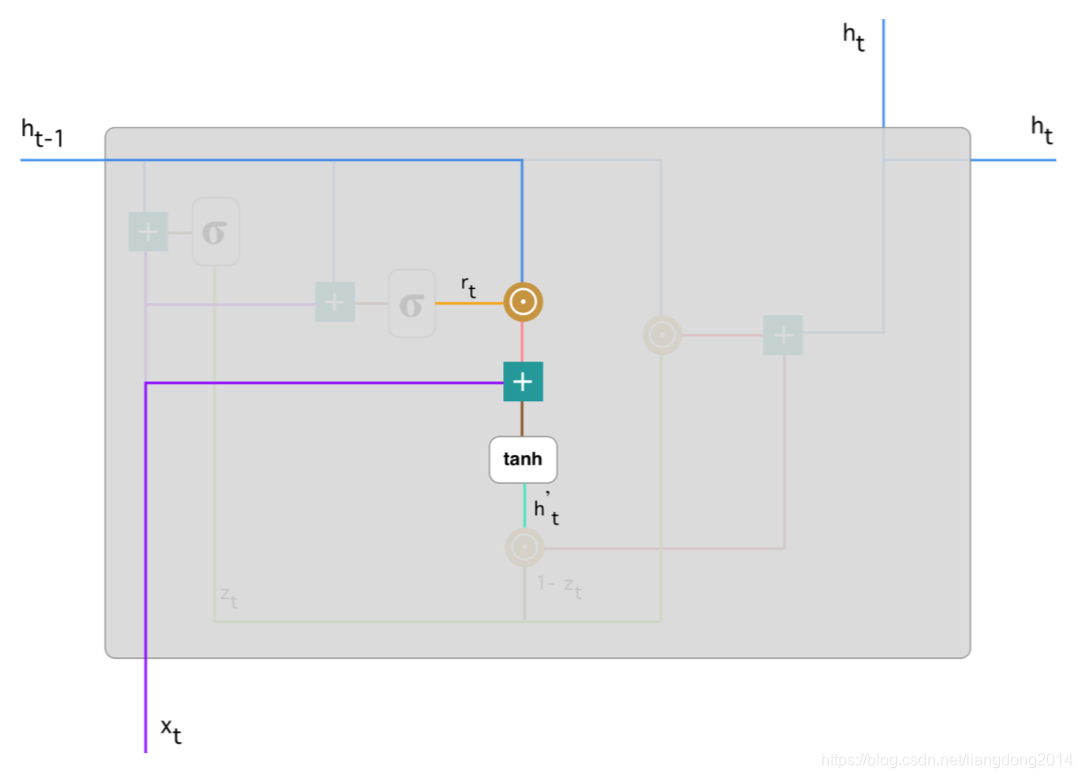
- 使用当前的输x_t, 和经过reset gate处理过的上一cell的state的组合得到本cell的state。
- 公式化如下: h t ′ = t a n h ( W x + r t ∗ h t − 1 ) h'_t = tanh(Wx + r_t * h_{t-1}) ht′=tanh(Wx+rt∗ht−1)
- 其结构如下所示:
- output gate:输出门,将update后的上一个state和本时刻的state相结合。
- 其网路结构如下所示:
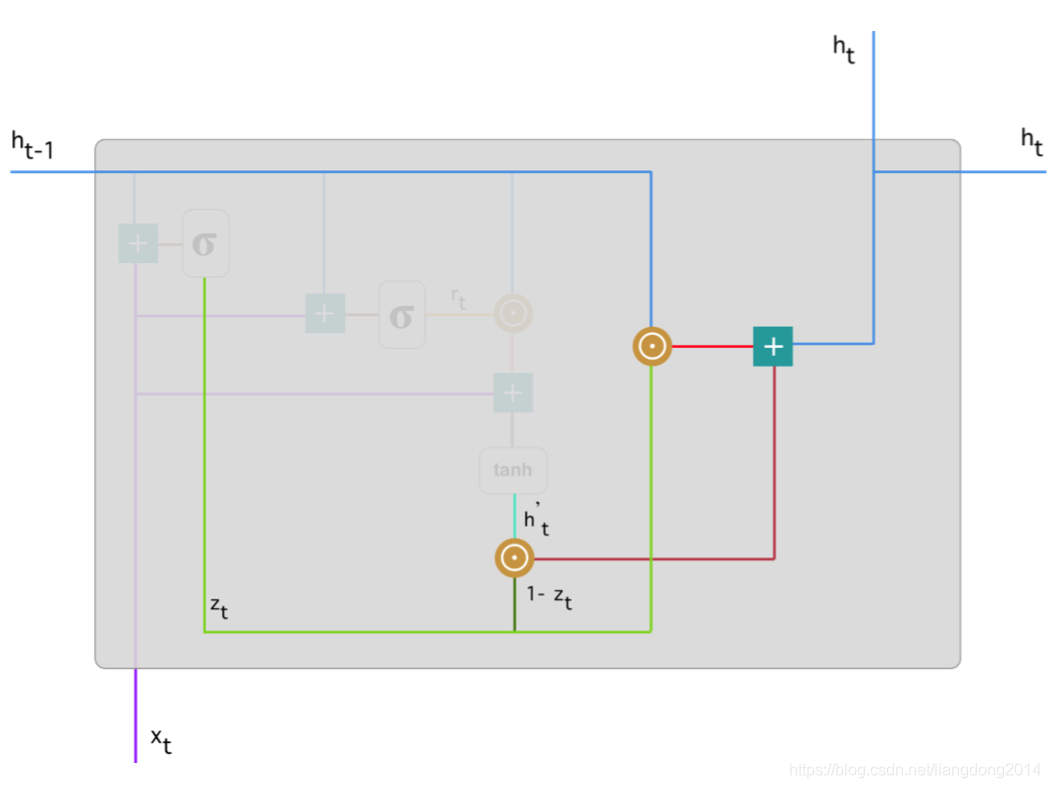
- 注意,我们在这里相当于重用了 z t z_t zt,使用 1 − z t 1-z_t 1−zt就表示要强化update后的上一个时刻没有的信息。
- 公式化表达: h t = z t ∗ h i + ( 1 + z t ) ∗ h i ′ h_t = z_t * h_i + (1+z_t) * h'_i ht=zt∗hi+(1+zt)∗hi′
- 其网路结构如下所示:
对比LSTM和GRU
- 相似点:
- 他们相比于传统的RNN,他们都引入了新的gate。
- 在更新memory content的时候,他们都是原有的content+新生成的content的形式。也就是说他们都会create 一个hidden的hidden new memory content,用这个content和previous content相加,得到最后的content。例如GRU: h t = z t ∗ h i + ( 1 + z t ) ∗ h i ′ h_t = z_t * h_i + (1+z_t) * h'_i ht=zt∗hi+(1+zt)∗hi′;LSTM: C i = C i − 1 ∗ f i + i i ∗ C ^ i C_i = C_{i-1} * f_i + i_{i} * \hat{C}_i Ci=Ci−1∗fi+ii∗C^i
- 不同点:
- 在向下一层传递state的时候,LSTM比GRU多了一个control gate。对比起来GRU:
h
t
=
z
t
∗
h
i
+
(
1
+
z
t
)
∗
h
i
′
h_t = z_t * h_i + (1+z_t) * h'_i
ht=zt∗hi+(1+zt)∗hi′,而LSTM:
h
i
=
s
i
g
m
o
i
d
(
W
o
h
h
t
−
1
+
W
o
x
x
i
)
∗
t
a
n
h
(
C
i
)
h_i = sigmoid(W_{oh}h_{t-1}+W_{ox}x_i)*tanh(C_i)
hi=sigmoid(Wohht−1+Woxxi)∗tanh(Ci),前面的sigmoid就是多出来的control gate。体现在LSTM Cell的结构图是就如下所示:
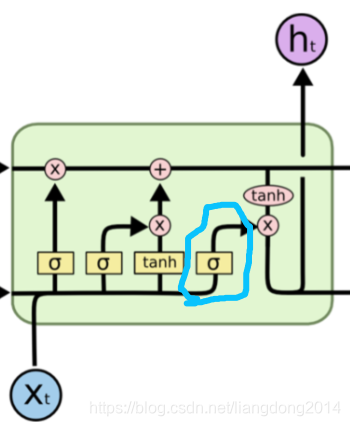
- 第二点不同就是在更新state的时候,针对新生成的memory content,LSTM也比GRU多了一个control gate。用来控制哪些元素应该被用来更新。体现在公式上, GRU:
h
t
′
=
t
a
n
h
(
W
x
+
r
t
∗
h
t
−
1
)
h'_t = tanh(Wx + r_t * h_{t-1})
ht′=tanh(Wx+rt∗ht−1),LSTM:
C
i
=
C
i
−
1
∗
f
i
+
i
i
∗
C
^
i
C_i = C_{i-1} * f_i + i_{i} * \hat{C}_i
Ci=Ci−1∗fi+ii∗C^i。体现在LSTM Cell的结构图上就如下图所示
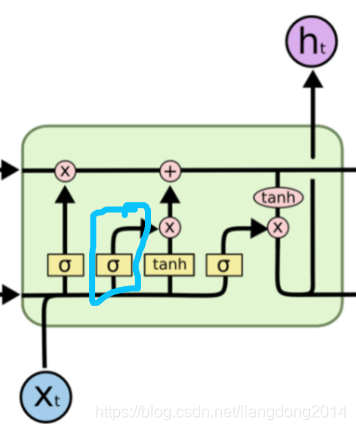
- 在向下一层传递state的时候,LSTM比GRU多了一个control gate。对比起来GRU:
h
t
=
z
t
∗
h
i
+
(
1
+
z
t
)
∗
h
i
′
h_t = z_t * h_i + (1+z_t) * h'_i
ht=zt∗hi+(1+zt)∗hi′,而LSTM:
h
i
=
s
i
g
m
o
i
d
(
W
o
h
h
t
−
1
+
W
o
x
x
i
)
∗
t
a
n
h
(
C
i
)
h_i = sigmoid(W_{oh}h_{t-1}+W_{ox}x_i)*tanh(C_i)
hi=sigmoid(Wohht−1+Woxxi)∗tanh(Ci),前面的sigmoid就是多出来的control gate。体现在LSTM Cell的结构图是就如下所示:

















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









