



 本文详细介绍了如何在PC和移动端抓取APP和小程序的HTTPS请求,包括使用Yakit进行数据劫持、配置双层代理、处理证书信任问题,以及利用wirshark抓取https数据包的技巧和注意事项。
本文详细介绍了如何在PC和移动端抓取APP和小程序的HTTPS请求,包括使用Yakit进行数据劫持、配置双层代理、处理证书信任问题,以及利用wirshark抓取https数据包的技巧和注意事项。
最近有很多朋友问我APP和小程序应该怎么抓包,为什么抓不了https请求包,网上说法很多这里就一篇文章统一解决下大家的问题。
首先我们需要一个抓包神器yakit,实战中这个软件非常强大,数据劫持支持http2.0和国密TLS。有了这么强大的工具我们就可以开始解决APP小程序抓包问题了。

1.PC端小程序抓包
最近接了很多小程序的渗透,那就先来讲讲PC端小程序如何抓包。
PC端抓包我们需要双层代理,这里使用proxifier+yakit的形式
proxifier的配置
proxifier的安装大家可以去参考下别的博主,我这里主要讲解如何使用
首先配置代理服务器,左上角

监听本地8083端口(跟yakit一致)

配置代理规则,监听微信的数据

yakit配置
yakit这边同步开启数据劫持,全局代理数据到8083端口,这样就能抓到小程序的数据包了


这样就能抓到小程序的包了,全是https

出现问题及其解决方案
1.证书不信任
导出yakit证书

这里一定要去访问下载,访问下载后双击证书就可以直接安装(证书的安装大家可以参考其他博主,非常简单)直接下载的格式是pem后续APP安装需要用到

2.访问小程序无响应
关闭代理服务器访问小程序,接收到数据后再打开代理服务器
其他解决办法
使用旧版微信,就正常抓包就能抓包,有一定的封号风险
2.APP和移动端小程序抓包
由于安卓7.0以上版本不再信任用户证书,所以我们需要给手机安装系统证书(必须root!未root的安装手机抓包可以使用httpcanary)
导出yakit证书

这里需要选择下载到本地,这时证书下载下来应该是pem格式
转换证书格式
这里如果是burp或者其他的证书需要将证书转为pem格式
使用openssl(关于openssl的安装建议在Linux环境下安装很方便,如果在windows环境下会遇到perl,openssl,windows三方版本不兼容问题,祝各位好运)
openssl x509 -inform DER -in burp.cer -out cacert.pemyakit的证书因为导出后就是pem格式可以省略第一步,直接查看证书哈希值
openssl x509 -inform PEM -subject_hash_old -in cacert.pem将文件名改为hash值最上方的数字,到这里证书就算制作成功(burp;9a5ba575;yakit:38555061)
将证书名字命名为hash值.0(38555061.0)
导入系统证书
这里需要用到adb,不会adb的朋友可以去学习一下
将证书复制到安卓目录下
adb push C:\Users\2023\Desktop\38555061.0 /sdcard/提权
adb shellsu
mount -o remount -o rw /
mount -o remount -o rw /system上面选一个用就行
如果出现报错则将逍遥模拟器的共享系统盘改为独立系统盘
remount of /system failed: Read-only file system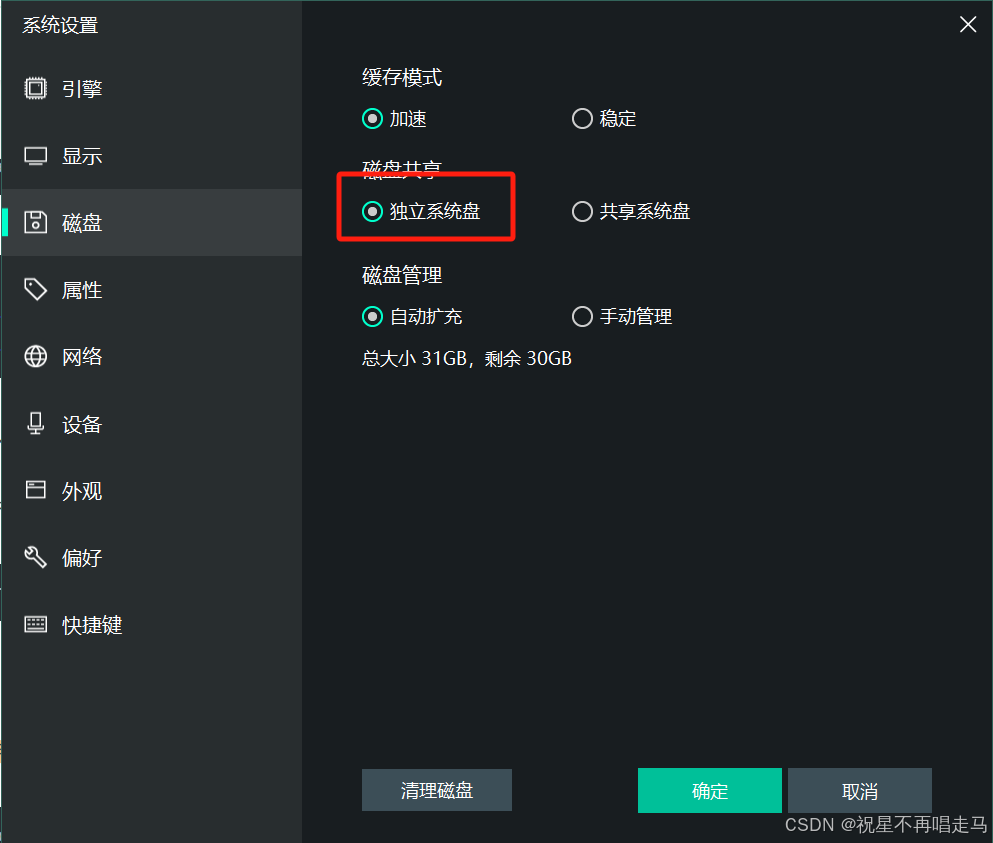
把证书复制到系统证书目录,然后赋权
cp /sdcard/38555061.0 /system/etc/security/cacerts/
chmod 644 /system/etc/security/cacerts/38555061.0
reboot 重启这样就成功把证书导入到安卓系统证书里面了,导入成功可以看到证书

burp

后续将手机的网络代理到yakit的监听端口就行了

问题及解决方案
注意抓取app时yakit需要劫持PC端IP的端口,不能劫持本地端口
如果出现打开APP无响应或者报错的情况大概率采用的SSL双向校验,目前博主没有了解到有方法能够抓包
3.wirshark抓取https数据包
参考:

















 6642
6642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









