




(开发者终于有办法让模型“跑得快、算得少、效果不掉”)
过去一年,我们很少再讨论“模型怎么训练”,更多在谈“模型怎么跑得起”。算力预算不断压缩、应用端延迟要求不断提高、手机和边缘端又开始在容纳 20B~100B 模型,推理成为新的瓶颈。你可能也经历过:模型效果很好,但线上一跑,成本高得离谱;加点批处理可以省算力,但延迟又上不去;想上移动端,但生成速度慢得让用户想打人。
这背后折叠出一个行业事实——大模型推理已经不是单点优化,而是一场体系工程。
Speculative Decoding、Chunk Decoding 与 Hybrid Inference(混合推理)正是这场工程中的三种关键“齿轮”。它们解决的问题类似:如何让模型产生同样的输出,但少算一些算力、少等一些时间。
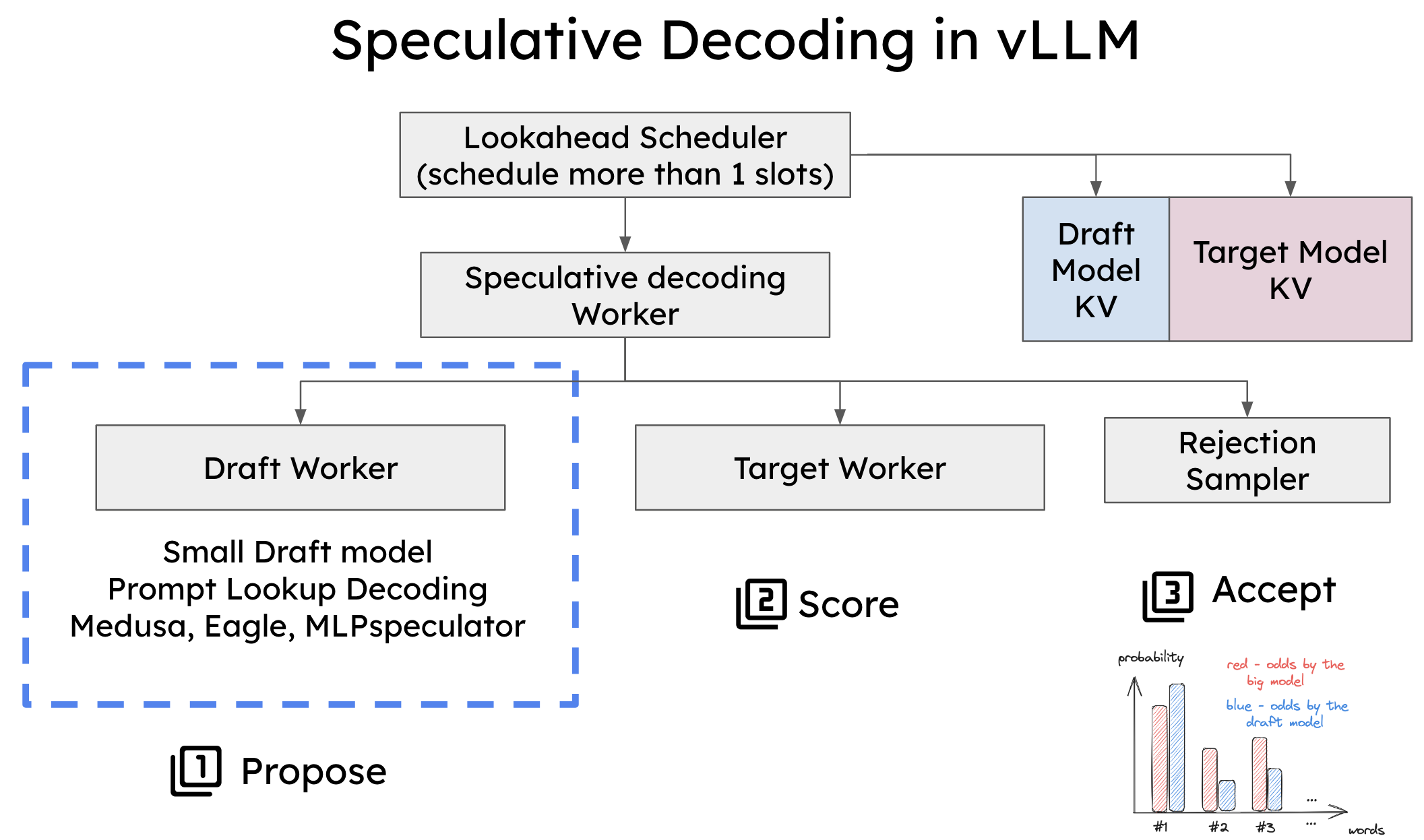
这篇文章,我想和你一起把这三种技术讲“懂”,讲到你能画出脑内图、能立即复现 demo,并能理解为什么它们是未来 LLM 应用工程化的基本能力。
一、为什么“推理成本”难,难在哪?
你可能已经听说过一些简单说法:推理成本=显存 × FLOPs × 时间。但真正让我们吃瘪的不是这三个字母,而是它们之间的耦合。
想象一下,大模型的推理好比一辆需要实时“造轮胎”的汽车。每生成一个 token,它都要重新跑一遍注意力、KV Cache、线性层与激活函数。车轮不是造好一套上去,而是——每跑一米造一个轮子。
这意味着:
-
每个 token 都要严格顺序执行(自回归导致无法并行生成)。
-
每一步都需要完整的 forward(几十到上百层)。
-
模型越大,每个 toke
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7201
7201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









