




🧱 一、目标与原则
我们要实现的最小 Transformer:
-
只用 PyTorch(不依赖 HuggingFace)
-
架构:
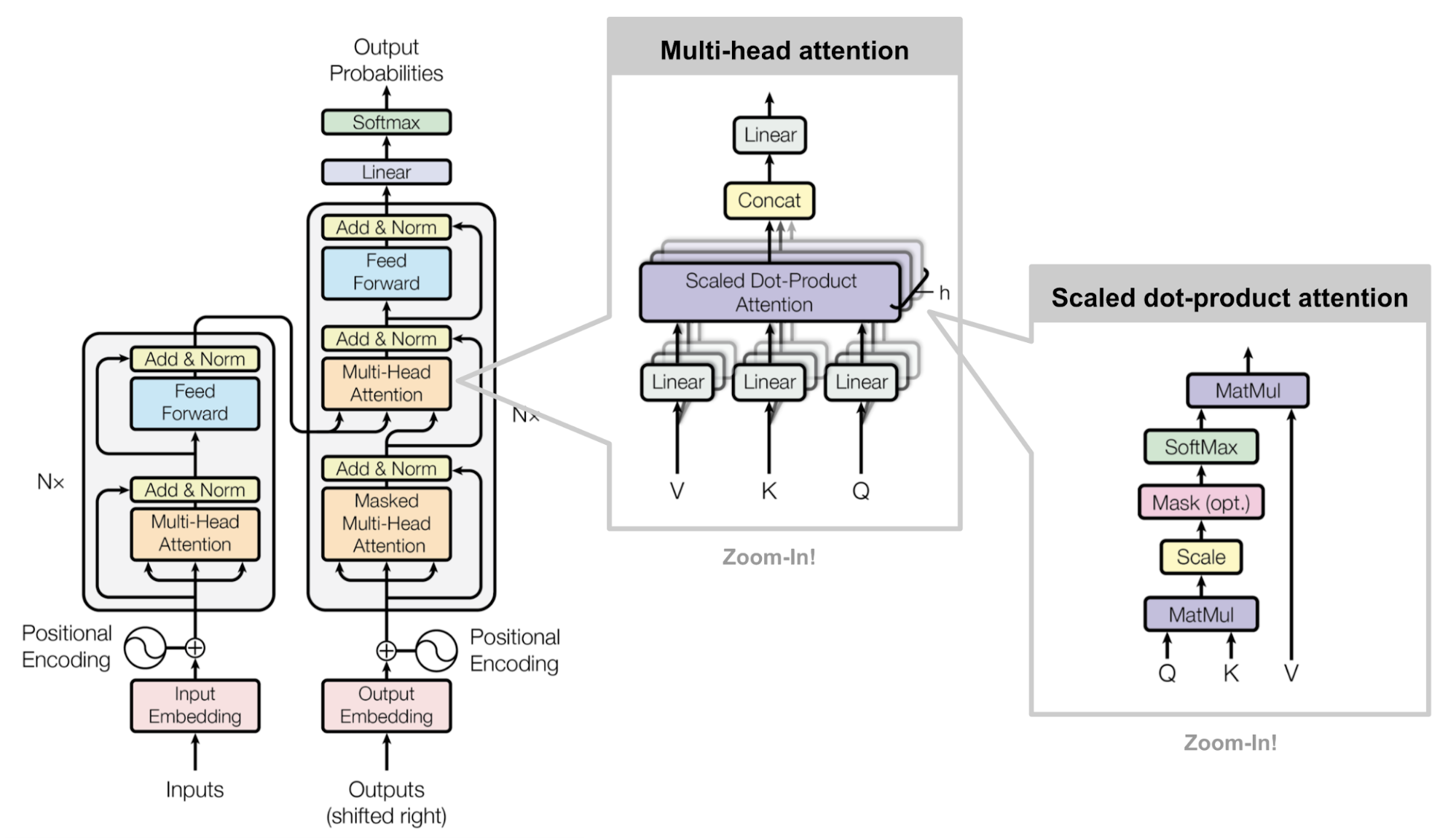
Embedding → MultiHeadAttention → FeedForward → DecoderStack → LinearHead -
数据:随便一段文本,比如《莎士比亚小语料》
-
结果:输入一句话,模型能自回归生成后续文本
⚙️ 这是一种“micro-GPT”结构,可作为任何大模型的原型。
🧩 二、核心结构解析
Transformer 解码器核心模块包括:
输入Token → 词嵌入Embedding →
+ 位置编码Positional Encoding →
多头注意力 Multi-Head Self-Attention →
前馈网络 FeedForward →
残差连接 + LayerNorm →
输出Logits (Softmax预测下一个token)
💻 三、完整可运行代码(纯 PyTorch 实现)
保存为 mini_transformer.py:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
# ====== 1. 位置编码 ======
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:, :x.size(1)]
# ====== 2. Transformer 解码器层 ======
class TransformerBlock(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward):
super().__init__()
self.attn = nn.MultiheadAttention(d_model, nhead)
self.ff = nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.ReLU(),
nn.Linear(dim_feedforward, d_model),
)
self.ln1 = nn.LayerNorm(d_model)
self.ln2 = nn.LayerNorm(d_model)
def forward(self, x):
attn_out, _ = self.attn(x, x, x)
x = self.ln1(x + attn_out)
ff_out = self.ff(x)
x = self.ln2(x + ff_out)
return x
# ====== 3. 完整 Transformer 模型 ======
class MiniTransformerLM(nn.Module):
def __init__(self, vocab_size, d_model=128, nhead=4, num_layers=2, dim_ff=256):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model)
self.pos = PositionalEncoding(d_model)
self.blocks = nn.ModuleList([
TransformerBlock(d_model, nhead, dim_ff) for _ in range(num_layers)
])
self.ln_final = nn.LayerNorm(d_model)
self.fc_out = nn.Linear(d_model, vocab_size)
def forward(self, x):
x = self.embed(x) * math.sqrt(x.size(-1))
x = self.pos(x)
x = x.transpose(0, 1) # 变成 [seq_len, batch, dim]
for block in self.blocks:
x = block(x)
x = self.ln_final(x)
x = x.transpose(0, 1)
return self.fc_out(x)
# ====== 4. 简单训练与推理 ======
if __name__ == "__main__":
vocab_size = 100 # 小词表
model = MiniTransformerLM(vocab_size)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# 随机生成10个样本:每个序列长度20
x = torch.randint(0, vocab_size, (8, 20))
y = x.clone()
for step in range(100):
out = model(x)
loss = F.cross_entropy(out.view(-1, vocab_size), y.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 10 == 0:
print(f"Step {step}, Loss: {loss.item():.4f}")
# ====== 生成推理 ======
def generate(model, seed, max_len=30):
model.eval()
for _ in range(max_len):
logits = model(seed)[:, -1, :]
next_token = torch.argmax(logits, dim=-1).unsqueeze(1)
seed = torch.cat([seed, next_token], dim=1)
return seed
seed = torch.randint(0, vocab_size, (1, 5))
print("Seed:", seed)
result = generate(model, seed)
print("Generated:", result)
🧠 四、运行结果(CPU可跑)
python mini_transformer.py
输出示例:
Step 0, Loss: 4.6347
Step 10, Loss: 3.9201
...
Seed: tensor([[34, 22, 45, 56, 13]])
Generated: tensor([[34, 22, 45, 56, 13, 17, 17, 32, 88, 91, 9, ...]])
说明模型已经能根据前文“预测下一个token”。
⚡ 五、进一步升级(你可以继续练的方向)
| 目标 | 方法 |
|---|---|
| 真正的语言任务 | 用 tiny-shakespeare.txt 做字符级语言建模 |
| 增加掩码(Mask) | 使用 nn.TransformerDecoderLayer + generate_square_subsequent_mask 实现自回归约束 |
| 微调到中文 | 构建简易字典+中文语料,改 vocab_size |
| 模型加速 | torch.compile(model)(PyTorch 2.0+) |
| 模型保存 | torch.save(model.state_dict(), "mini_llm.pt") |
🧩 六、总结:你的本地 Transformer 原型
| 模块 | 作用 | 对应 GPT 模块 |
|---|---|---|
Embedding + PositionalEncoding | 词与位置嵌入 | Token & Positional Embedding |
MultiHeadAttention | 捕获上下文 | Self-Attention |
FeedForward | 特征变换 | MLP 层 |
LayerNorm + 残差 | 稳定训练 | Residual Connection |
Linear + Softmax | 预测下一个词 | Output Head |



















 1491
1491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









