



前言
Transformer 架构自 2017 年在里程碑式论文《Attention is All You Need》(https://arxiv.org/pdf/1706.03762)中提出以来,彻底改变了自然语言处理领域。与传统的序列模型不同,Transformer 采用自注意力机制(self-attention)为核心构建模块,使其能够高效地捕捉数据中的长距离依赖关系。从本质上看,Transformer 可以被视为一种通用的计算基底——一种可编程的逻辑“组织”,它会根据训练数据进行动态重构,并且可以层层堆叠,构建出具有复杂涌现行为的大模型。
每一层中都包含两个核心子层,协同工作:多头自注意力机制和位置前馈网络。多头注意力机制允许模型在处理输入序列时同时关注不同部分,从多个表示视角捕捉 token 之间的多种关系;前馈网络则在每个位置上独立应用,通过引入非线性来增强模型对复杂模式的学习能力。
由于注意力机制可以并行处理所有 token,Transformer 不再像传统 RNN 那样按顺序处理数据,因此需要一种创新的方法来引入顺序信息。这个问题通过位置编码得以解决:模型会在输入层将位置编码(可以是学习得到的 嵌入,也可以是固定的正弦函数)加入到 token 嵌入中。这样,模型就能获得 token 的位置信息,从而在并行处理的同时保留序列结构。
Transformer 的强大之处在于它能够在处理过程中动态评估不同 token 的重要性。比如在句子 “I went to the bank to deposit money.” 中,“bank” 是一个多义词。模型可以强烈关注上下文中的 “deposit” 和 “money”,从而正确地理解 “bank” 在这里指的是金融机构,而不是河岸。这种上下文感知能力,使得 Transformer 在处理需要细致语言理解的任务时表现出色。
此外,Transformer 架构中还引入了层归一化(layer normalization)和残差连接(residual connections)来进一步增强模型性能。层归一化通过在每一层对激活值进行归一化,来稳定训练过程;而残差连接则为梯度提供了快捷路径,有助于缓解深层网络常见的梯度消失问题。这两个机制相互配合,使得即使在模型非常深的情况下,Transformer 也依然能够有效训练。
令人惊讶的是,研究人员发现,当他们通过增加 Transformer 模型的层数、嵌入维度以及训练数据规模来扩大模型时,这类架构展现出了令人瞩目的“涌现能力”(emergent capabilities)。更大的模型具备一些小模型所不具备的能力,例如少样本学习、推理能力,甚至能够初步理解一些它们在训练时并未明确接触过的概念。正是这种“扩展效应”(scaling effect),驱动了近年来人工智能领域的飞速发展。
我们接下来要从零构建的是一种 decoder-only Transformer 架构,它是由多个完全相同的 decoder 块垂直堆叠而成。与最初包含 encoder 和 decoder 的 Transformer 不同,现代语言模型通常只使用 decoder 部分,用于预测下一个 token。这种架构具备极强的可扩展性,目前主流的大模型参数规模已经从几亿增长到数十亿。
我们将逐步实现一个纯 NumPy 版本的 GPT-2 模型,逐个组件地构建。整个实现大约只有 100 行左右的代码,完整源码可以在 GitHub 上查看,https://github.com/sdiehl/gpt2-weights。
在实现过程中,我们会从网上下载一些神经网络权重的数据结构。你只需要知道,它们本质上是由不同维度的数组组成的一组参数。
LinearParams:表示一个线性层,包含用于线性变换的权重和偏置参数。LayerNormParams:表示一个层归一化层,包含归一化所需的放缩因子(gain)和偏置(bias)参数。AttentionParams:表示一个多头注意力层,包含 query、key、value 以及输出投影(output projection)的参数。BlockParams:表示一个 Transformer 块,内部包含注意力和前馈网络的参数。ModelParams:表示整个模型的参数,包括 token 嵌入、位置嵌入、若干 Transformer 块,以及最终的层归一化。HParams:表示模型的超参数(hyperparameters),包括层数、注意力头数、嵌入维度等。
在我们的代码中,会使用如下缩写:
g- Gamma,层归一化的缩放参数b- Beta,偏置参数w- 权重矩阵或数组wte- Word/Token Embeddings,词或 token 的嵌入表示wpe- Word Position Embeddings,字词位置嵌入ln- Layer Normalization,层归一化mlp- Multi-Layer Perceptron,多层感知机fc- Fully Connected layer,全连接层qkv- Query、Key、Value(attention 的三个核心组成部分)attn- Attention,注意力机制proj- Projection,线性变换操作
BPE 分词(BPE Tokenization)
BPE(Byte-Pair Encoding) 是一种分词算法,它通过将词拆分为更小的单元,称为子词(subword)来解决“词表外词”(out-of-vocabulary)的问题。BPE 最初是为数据压缩而设计的,后来被引入到自然语言处理领域,用来将词视作字符序列来处理。BPE 的核心思想是:反复将语料中最频繁的相邻符号对合并成新的子词单位。这个过程从把语料中的每个词拆成单个字符开始,初始词表就是所有唯一字符的集合。
接下来,BPE 进入迭代式的“合并”阶段:在每次迭代中,它会统计语料中所有相邻符号对的频率,找出频率最高的一对进行合并,形成一个新的子词。所有出现该对的地方都会被更新,去除它们之间的间隔,新合并出的子词被加入词表。这个过程会一直进行,直到词表达到预设大小,或者没有高频对可合并为止。训练过程中执行的合并操作序列,是之后分词新文本的关键。
一旦 BPE 分词器训练完成(即已确定合并规则序列),它就可以用于处理新文本。分词时,分词器会先检查整个词(通常带有起始标记)是否在词表中。如果不在,就将其拆成字符,然后按训练时学到的顺序逐步应用合并规则。若某些字符不在初始字符集里,可能会被替换为未知 token(如 <UNK>)。BPE 被广泛应用于现代语言模型,特别适合处理低频词,以及像中文这样词边界不明显的语言,此时分词通常从单个字符起步。
我们不会从零实现 BPE,而是直接加载 GPT-2 官方仓库中已有的分词器。你也可以在网上找到简单的 Python 实现示例。
encoder = get_encoder("", "model")
# encode a string into a list of tokens
tokens = encoder.encode("Hello world")
print(tokens) # [15496, 995]
我们可以看到,分词器将字符串 "Hello world" 编码成了一个 token 序列 [15496, 995],恰好是两个词、两个 token。但如果是 "Barack Obama",编码结果会是 [10374, 441, 2486],两个词却被分成了三个 token。


分词与位置嵌入(Tokenization and Position Embeddings)
从字符串输入开始,我们首先通过分词器将它分成一串 token,然后通过查找 params.wte 矩阵,为每个 token 获取对应的嵌入向量:
x = params.wte[inputs] + params.wpe[range(len(inputs))]
这行代码是 Transformer 模型处理输入序列之前的关键步骤。它将每个 token 的两种信息结合了起来:token 本身的语义表示和该 token 在句子中的位置。模型中有两个关键的嵌入矩阵:token 嵌入矩阵和位置嵌入矩阵。
1. Token 嵌入矩阵(params.wte[inputs])
inputs 是你的 token 序列,是一个整数列表。例如,如果文本 "Hello world" 被编码成 [15496, 995],那么 inputs 就是 [15496, 995]。
params.wte 是 token 嵌入矩阵,本质上是一个查找表,其中每一行代表词表中一个 token 的嵌入向量(比如在 GPT-2 small 中,每个向量维度是 768)。
执行 params.wte[inputs] 的操作就是“查表”。对每个 token ID,取出它在 params.wte 中对应的向量,最终得到一个矩阵,每行就是该 token 的向量表示。所以 [15496, 995] 会被映射成一个 2 行的矩阵,分别表示两个 token 的 embedding。
2. 位置嵌入矩阵(params.wpe[range(len(inputs))])
Transformer 是并行处理所有 token 的,也就是说它不会像 RNN 那样天然“知道” token 的顺序。因此需要引入位置嵌入,给每个 token 加上位置信息。
range(len(inputs)) 生成的是一个位置索引序列,比如对于 [15496, 995] 就是 [0, 1]。
params.wpe 是位置嵌入矩阵,结构类似于 token 嵌入矩阵,但每一行对应的是序列中的一个位置(第 0 个、第 1 个、第 2 个……一直到模型支持的最大序列长度)。这些位置向量是模型在训练中学到的。
执行 params.wpe[range(len(inputs))] 的操作,就是取出输入序列中每个位置对应的嵌入,最终也会得到一个和 token 嵌入同样形状的矩阵。
最终我们将 token 嵌入和位置嵌入相加(逐元素),这一步就构造出了包含位置信息的 token 表示,准备送入后续的 Transformer 模块中进行进一步处理。

加法(+)操作的含义如下:
token 嵌入矩阵(表示每个 token 是什么)和位置嵌入矩阵(表示每个 token 在序列中的位置)会按元素逐一相加。这两个矩阵的形状是相同的,都是“序列长度 × 嵌入维度”。
相加后的结果是一个新的矩阵 x,其中每一行向量同时编码了该 token 的身份信息和它在序列中的位置信息。这种融合后的表示,就是后续要送入 Transformer 模型堆叠结构中进行处理的最终输入。
总之,这一行代码通过查表拿到每个 token 的向量表示,并加上该 token 所在位置对应的向量,从而构造出了输入序列的初始表示。这样一来,Transformer 后续在处理这些 token 时,就不仅知道每个 token 是什么,还能感知它们在序列中的先后顺序。
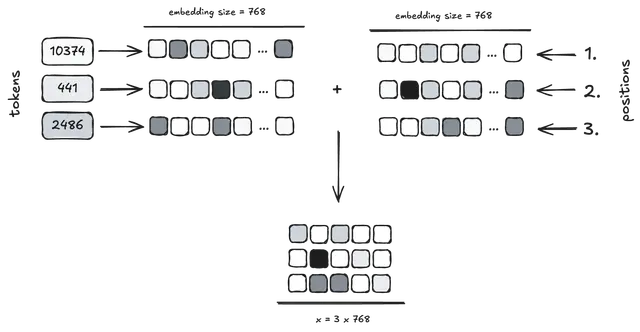
这个矩阵的大小是 [sequence_length, embedding_dimension],其中 sequence_length(序列长度)在代码中通常用 N 表示。
GELU
GELU(Gaussian Error Linear Unit,高斯误差线性单元)是一种激活函数,常用于 Transformer 架构中,尤其是在每个块的前馈网络(FFN)里。它的核心作用是引入非线性能力,从而让模型能够学习更加复杂的数据模式和关联关系。如果没有非线性激活函数,即使堆叠很多层网络,最终也只相当于一个线性变换,模型的表达能力会受到极大限制。GELU 的数学定义如下:

其中 erf 表示高斯误差函数(error function)。实际中我们会使用一个近似公式,用 tanh 函数来代替误差函数,这样就不需要计算积分,效率更高。Python 代码中使用的近似实现如下:
# gelu:
# x : (N, 768)
# out : (N, 768)
def gelu(x: np.ndarray) -> np.ndarray:
return 0.5 * x * (1 + np.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * x**3)))
这是一个对标量进行操作的函数,会对输入张量的每个元素逐个应用该函数。
Softmax
GELU 主要负责前馈网络中的非线性处理,而 Transformer 还需要一种机制把原始分数转换为有意义的概率分布,这就是 Softmax 的作用。Softmax 是 Transformer 架构中非常关键的函数,主要应用在两个地方:一是在注意力机制中,二是在模型的最终输出层。它的作用是把一组原始分数(logits)转换为概率分布。Softmax 会先对每个元素进行指数变换(确保值为正数),然后再除以这些指数值的总和进行归一化。结果是一个所有值都在 0 到 1 之间、并且总和为 1 的向量。

在注意力机制中,Softmax 被用于处理 query 和 key 之间计算出的打分结果(也叫 attention score),把这些原始的相似度分数变成权重,也就是注意力分布,用来表示模型应该关注哪些位置的 value。
在模型的最后一层(即用于生成下一个 token 之前),Softmax 会被应用到最终的投影层输出(logits)上,把模型对词表中每个词的打分变成概率分布,从而可以据此采样生成下一个 token。
Python 中的 Softmax 实现通过先减去每一行的最大值来避免数值不稳定,然后做指数和归一化处理。
# softmax:
# x : (N, 64)
# out : (N, 64)
def softmax(x: np.ndarray) -> np.ndarray:
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
层归一化(Layer Normalization )
除了激活函数和概率变换,神经网络还需要一些机制来稳定训练过程,特别是在像 Transformer 这样很深的网络结构中。层归一化(LayerNorm)就是为此目的设计的。与批量归一化(Batch Normalization)不同,后者是对一个 batch 中所有样本在同一特征维度上的数值做归一化,而层归一化是对单个样本在所有特征维度上做归一化处理。

其中 μ 是该样本在该层所有维度上的均值,σ² 是方差,γ 是可学习的缩放参数(gain),β 是可学习的偏移参数(bias)。
在 Transformer 中,层归一化(LayerNorm)通常在每个 Transformer 块的多头注意力模块和前馈网络模块之前使用,这种结构也被称为 pre-LN。它的工作方式是:对每一个样本的每一层输出,先计算均值和方差,然后进行标准化,再通过 γ 和 β 做缩放和平移调整。这样一方面保持了归一化带来的稳定性,另一方面也保留了模型的表达能力。
层归一化(LayerNorm)能有效缓解梯度消失或爆炸的问题,允许使用更高的学习率,并且降低了模型对参数初始值和尺度的敏感度。通过保证每层的输入数据尺度稳定,层归一化(LayerNorm)可以显著提升模型的训练效果和收敛速度。
# layer_norm:
# x : (N, 768)
# g : (768,)
# b : (768,)
# out : (N, 768)
def layer_norm(
x: np.ndarray, g: np.ndarray, b: np.ndarray, eps: float = 1e-5
) -> np.ndarray:
mean = np.mean(x, axis=-1, keepdims=True)
variance = np.var(x, axis=-1, keepdims=True)
return g * (x - mean) / np.sqrt(variance + eps) + b
线性投影(Linear Projection)
在引入归一化机制以稳定网络训练之后,Transformer 还需要一种方式将表示从一个空间转换到另一个空间,这时线性层就派上用场了。线性层,也叫做全连接层或密集层,是神经网络中最基本的组成部分之一。它对输入数据进行线性变换。
从数学角度来看,线性层的运算公式是: output = input @ weights + bias,其中 @ 表示矩阵乘法。input是传入层的数据,weights是一个可学习的矩阵,bias是一个可学习的向量,会加到计算结果上。权重矩阵有效地将输入向量从原始维度投影到新的维度(由权重矩阵的形状决定),而偏置则用于对输出进行平移。
# linear:
# x : (N, 768)
# w : (768, 3072)
# b : (3072,)
# out : (N, 3072)
def linear(x: np.ndarray, w: np.ndarray, b: np.ndarray) -> np.ndarray:
return x @ w + b
前馈网络(Feed-Forward Network)
在介绍了归一化、激活和线性变换的基本构成后,我们可以来看看这些组件是如何在前馈网络(Feed-Forward Network, FFN)中结合的。前馈网络,有时也称为位置前馈网络,是每个 Transformer 块中的第二个主要子层(位于多头注意力子层之后)。
前馈网络由两个线性变换组成,中间应用了非线性激活函数(之前介绍的 GELU 激活函数)。第一个线性层通常会扩展输入的维度(例如,将 768 扩展到 3072,类似 GPT-2),GELU 激活函数引入非线性,第二个线性层将结果再投影回原始输入维度(例如,将 3072 压缩回 768)。

这个前馈网络(FFN)是独立地应用于序列中的每个位置的。虽然注意力机制使得 token 可以相互作用,前馈网络则是针对每个位置单独处理信息,基于模型学习到的特征转换表示。它为模型增加了显著的表示能力,使得模型能够学习到更复杂的函数,超出仅通过注意力机制能够捕捉到的能力。
# ffn:
# x : (N, 768)
# c_fc_w : (768, 3072)
# c_fc_b : (3072,)
# c_proj_w : (3072, 768)
# c_proj_b : (768,)
# out : (N, 768)
def ffn(
x: np.ndarray,
c_fc_w: np.ndarray,
c_fc_b: np.ndarray,
c_proj_w: np.ndarray,
c_proj_b: np.ndarray,
) -> np.ndarray:
return linear(gelu(linear(x, w=c_fc_w, b=c_fc_b)), w=c_proj_w, b=c_proj_b)
注意力机制(Attention)
注意力机制是 Transformer 架构的核心思想。它受到人类视觉注意力的启发,就像我们在看图像时会专注于某些部分,或在阅读句子时关注特定的词语而忽略其他部分,注意力机制让模型在处理某个元素时能够动态地评估输入数据中不同部分的重要性。
具体来说,在处理像文本这样的序列数据时,当模型处理一个词时,它可以“注意到”序列中的其他相关词语,无论这些词语距离有多远。这种方式使得模型可以更好地理解整个句子的上下文和含义。通过这种选择性的关注方式,模型比传统的序列模型更有效地捕捉到长距离的依赖关系和相互联系。这样不仅提高了对文本的理解能力,也增强了模型处理复杂语言结构的效果。
每次注意力计算的核心是从输入序列中衍生出来的三个关键矩阵:
- Query(Q):表示我们当前正在处理的 token 或位置。可以把它理解为: “我现在要找什么样的特定信息?”
- Key(K):表示序列中所有的 tokens(包括当前的 token)。可以把它理解为每个 token 所包含信息的标签或标识符:“每个 token 提供了什么样的信息?”
- Value(V):同样表示序列中的所有 tokens。可以把它理解为每个 token 所传达的实际内容或表示:“每个 token 传达了什么实际信息?”
整个过程从一个初始投影开始,将输入序列 x 通过三个独立的线性层,生成跨整个输入维度的初始 Q、K、V 矩阵。这些大的矩阵然后沿着它们的嵌入维度被分割成更小的块,为每个注意力“头”创建独立的 Q、K、V 集合。形式上,自注意力计算为:

其中:
Q、K、V分别表示 query、key 和 value 矩阵d_k是 key 向量的维度- Q、K、V 分别表示 query、key 和 value 矩阵
- d_k 是 key 向量的维度
attention 函数实现的是核心的缩放点积注意力机制,这是多头注意力层中每个“头” 的基本构建模块。它的作用是计算在处理某个特定 token(由它的 Query 向量表示)时,模型应该对输入序列中每个 token(由其对应的 Value 向量表示)给予多少关注或“注意力”。
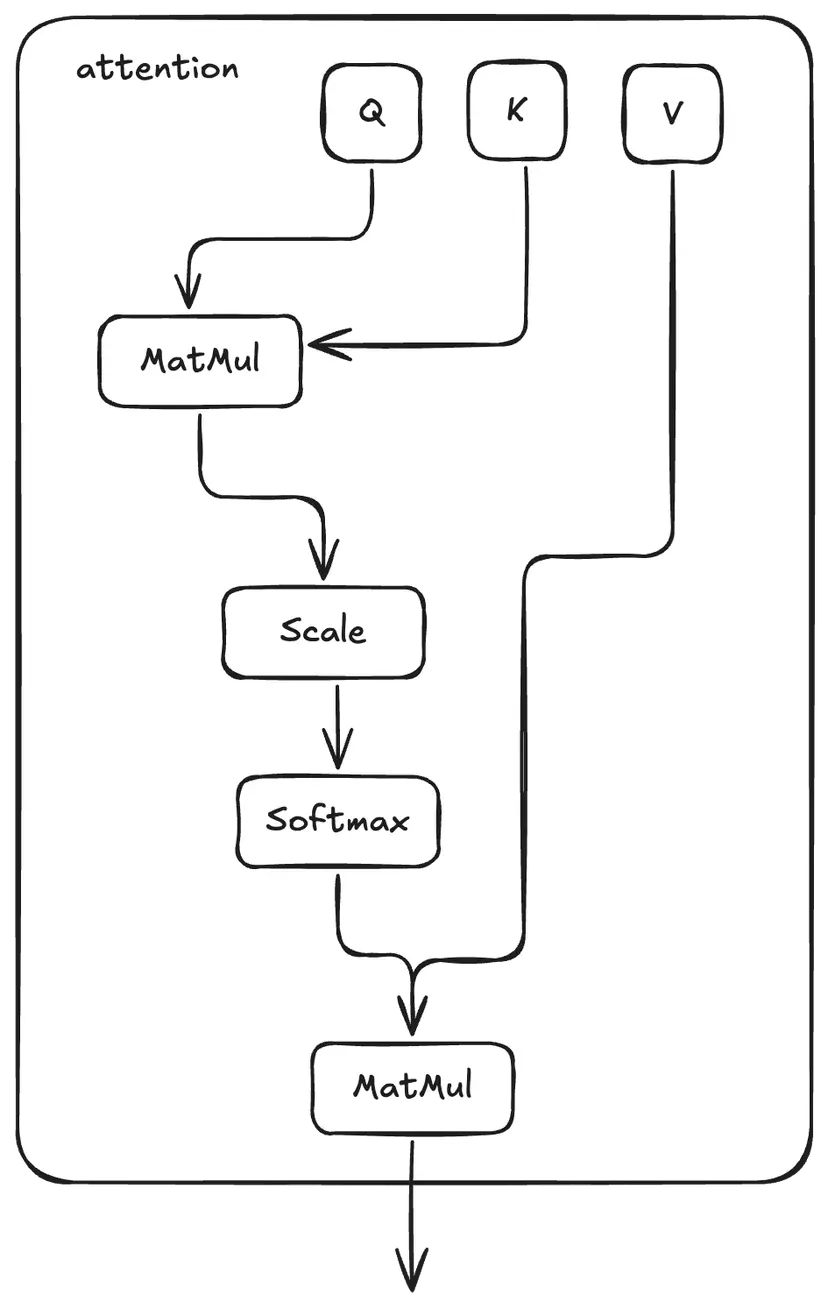
过程开始时,首先计算 Q 矩阵与 K 矩阵转置(q @ k.T)之间的点积。这个步骤衡量了每个 query 与所有 key 之间的原始相似度或兼容性。然后,这些原始得分通过除以 key 向量维度的平方根(np.sqrt(q.shape[-1]))进行缩放。
因果掩码是一种会加到缩放得分(scaled scores)上的掩码,用来阻止当前 token 去关注它后面的 token,确保模型的预测只能基于它之前的 token。这个掩码会对表示未来 token 的位置赋予一个非常大的负数,从而在计算注意力时让它们的权重接近于零。
接下来,会对经过掩码和缩放处理的得分应用 softmax 函数。这个操作会把得分转换成概率分布(即注意力权重),每一个权重值表示某个 key(以及对应的 value)对于当前 query 的相对重要程度。
最后,函数会将注意力权重与 V 矩阵进行矩阵乘法(attention_weights @ v)。这个操作得到的就是注意力机制的输出结果:对 Value 向量的加权求和,其中的权重就是前面计算出的注意力概率。每一个 query 最终得到的向量,其实就是输入序列中各个部分信息的融合,其中最相关的部分会被重点强调,这一切都是由 query 和 key 之间的关系来决定的。
# attention:
# q : (N, 64)
# k : (N, 64)
# v : (N, 64)
# mask : (N, N)
# out : (N, 64)
def attention(
q: np.ndarray, k: np.ndarray, v: np.ndarray, mask: np.ndarray
) -> np.ndarray:
attention_scores = (q @ k.T) / np.sqrt(q.shape[-1]) + mask
attention_weights = softmax(attention_scores)
return attention_weights @ v
我们可以通过可视化每个注意力头的注意力权重,来观察注意力机制的工作方式。比如,对于短语 “The quick brown fox jumps over the lazy dog”,我们可以绘制出 Transformer 堆栈中第一个块的注意力权重图,来看每个注意力头最关注哪些词之间的关系。我们会发现,在第一个注意力头中,“jumps” 和 “fox” 之间的关注度最高。

多头注意力机制(Multi-Head Attention,MHA)
虽然基础的注意力机制已经可以用于捕捉 token 之间的关系,但 Transformer 在此基础上进一步引入了多头注意力,从而使模型能够同时捕捉多种类型的关系,显著提升了其表达能力。多头注意力是 Transformer 的核心组件,它能够让模型在不同的位置上同时关注来自不同表示子空间的信息。与其仅执行一次注意力计算,不如说多头注意力是在输入的不同线性变换版本上并行地执行多次注意力机制(即多个“头”),从而让模型在同一时刻捕捉不同类型的关系(比如句法关系、语义关系等)。
在每个注意力头内部,都会执行一次缩放点积注意力机制。注意力分数是通过当前的 Query(Q)与所有 Key(K)进行点积计算而来,用来衡量当前 token 与其他 token 的关联程度。得到的分数会除以 key 向量维度的平方根进行缩放,然后通过 softmax 函数转化为概率值(即注意力权重)。这些权重表明当前应该对每个 Value(V)关注多少。

每个注意力头的 Query 矩阵的维度(64)是通过将模型的嵌入维度(768)除以注意力头的数量(12)得到的。当所有“头”的输出再次拼接在一起时,我们就恢复了原始的嵌入维度。
768/n_head = 768/12 = 64
注意力权重随后用于对对应的 V 向量进行加权求和,得到该“头”的输出向量,这个向量融合了当前 Query 与最相关的 token 的信息。接着,将所有注意力头的输出向量拼接在一起,形成一个整体向量,并通过一个最终的线性层,输出整个多头注意力模块的结果。这种多头并行的方式让模型能够从多个“视角”同时理解输入序列,从而捕捉更加丰富的上下文信息。
# mha:
# x : (N, 768)
# out : (N, 768)
def mha(
x: np.ndarray, c_attn: LinearParams, c_proj: LinearParams, n_head: int
) -> np.ndarray:
# qkv projection
# [N, 768] -> [N, 3*768]
x = linear(x, w=c_attn.w, b=c_attn.b)
# split into qkv
# [N, 3*768] -> [3, N, 768]
qkv = np.split(x, 3, axis=-1)
# split into heads
# [3, N, 768] -> [3, n_head, N, 64]
qkv_heads = [np.split(x, n_head, axis=-1) for x in qkv]
# apply causal mask to hide future inputs
# [N, N]
causal_mask = (1 - np.tri(x.shape[0], dtype=x.dtype)) * -1e10
# perform attention on each head
# [3, n_head, N, 64] -> [n_head, N, 64]
out_heads = [attention(q, k, v, causal_mask) for q, k, v in zip(*qkv_heads)]
# merge heads
# [n_head, N, 64] -> [N, 768]
x = np.hstack(out_heads)
# out projection
# [N, 768] -> [N, 768]
return linear(x, w=c_proj.w, b=c_proj.b)
Transformer 块
在注意力机制和前馈神经网络结构都定义清楚之后,我们就可以看到这些组件是如何被整合进完整的 Transformer 块中的。Transformer 块是 GPT-2 架构中的基本重复单元,它将多头注意力机制、前馈网络、归一化操作以及残差连接结合在一起,构成了一个可以反复堆叠的计算单元。
每个块都会接收一个输入向量序列,并通过两个主要的子层进行处理,在每个子层周围都加入了残差连接和层归一化操作。这种结构创造了一个平衡的信息流,既能通过残差连接保留原始输入,也能将其转化为新的表示形式。

第一个子层是我们刚刚探讨的多头注意力机制(MHA)。在输入进入多头注意力机制之前,它会先进行层归一化处理。多头注意力机制的输出随后会加回到原始输入(残差连接),将由注意力机制得到的上下文与原始的位置信息结合起来。这个和的结果会传递给第二个子层。
第二个子层是之前描述的前馈网络(FFN)。与第一个子层类似,输入(即第一个残差连接的输出)首先通过层归一化处理。归一化后的输出会被前馈网络处理。前馈网络的输出会再次通过残差连接加回到输入。最终的输出就是这个和的结果,接着作为输入传递给堆叠中下一个相同的 Transformer 块。
# transformer_block:
# x : (N, 768)
# out : (N, 768)
def transformer_block(
x: np.ndarray,
mlp: MLPParams,
attn: AttentionParams,
ln_1: LayerNormParams,
ln_2: LayerNormParams,
n_head: int
) -> np.ndarray:
# First sub-block: Layer norm -> Attention -> Residual
a = layer_norm(x, g=ln_1.g, b=ln_1.b)
a = mha(a, c_attn=attn.c_attn, c_proj=attn.c_proj, n_head=n_head)
x = x + a
# Second sub-block: Layer norm -> FFN -> Residual
m = layer_norm(x, g=ln_2.g, b=ln_2.b)
m = ffn(
m,
c_fc_w=mlp.c_fc.w,
c_fc_b=mlp.c_fc.b,
c_proj_w=mlp.c_proj.w,
c_proj_b=mlp.c_proj.b,
)
x = x + m
return x
完整模型(Full Model)
现在我们已经了解了各个组件和 Transformer 块的结构,接下来可以将这些内容组合成一个完整的模型。这些块会被堆叠多次(例如,最小的 GPT-2 模型堆叠了 12 次),从而构建一个能够进行复杂语言理解和生成的深度网络。注意力机制、前馈网络、层归一化和残差连接的结合,形成了一种能够有效处理顺序信息、捕捉复杂依赖关系,并且在深度网络中依然能够稳定训练的架构。
gpt2 函数表示 GPT-2 模型的完整前向传播过程,它处理给定输入 token ID 序列的数据流,经过先前定义的所有组件,将原始的 token ID 转换为上下文表示,并最终预测下一个 token。

旅程从对输入 token 进行嵌入开始。这是通过将 token 嵌入(在 params.wte 中查找)和位置嵌入(在 params.wpe 中查找)相加来实现的,对于输入序列中的每个 token,都会进行这样的处理。这种初始的组合嵌入同时捕捉了每个 token 的语义意义和它在序列中的位置,为后续所有处理提供了基础。
接下来,这个嵌入序列会流经 Transformer 块的堆叠,每个块通过其注意力机制和前馈机制逐步优化表示,逐渐构建更复杂的上下文理解。代码明确实现了这一堆叠过程,对于一个 12 层的模型来说,一个块的输出成为下一个块的输入。随着每一层的推进,模型能够捕捉到数据中越来越复杂的模式和关系。
def gpt2(inputs: list[int], params: ModelParams, n_head: int) -> np.ndarray:
# Get token embeddings and position embeddings
x = params.wte[inputs] + params.wpe[range(len(inputs))]
# Apply transformer block stack ( 12 blocks total )
for i in range(12):
x = transformer_block(
x,
n_head=n_head,
mlp=params.blocks[i].mlp,
attn=params.blocks[i].attn,
ln_1=params.blocks[i].ln_1,
ln_2=params.blocks[i].ln_2,
)
# Apply final layer norm and project to vocabulary
x = layer_norm(x, g=params.ln_f.g, b=params.ln_f.b)
logits = x @ params.wte.T # Project to vocabulary
return logits
在通过所有 Transformer 块的处理之后,得到的序列会再经过一次最终的层归一化,用于稳定数值范围。这个归一化后的输出,其形状为 (N, 768)(以 GPT-2 小型模型为例),表示序列中每个 token 对应的最终上下文嵌入。为了将这些表示转换为对词表中下一个 token 的预测,模型会利用转置后的 token 嵌入矩阵(params.wte.T)进行一次投影操作。这种巧妙的权重共享技巧(即输入嵌入和输出投影共用同一个嵌入矩阵)能够有效减少模型的总参数量。
最终的结果是一个形状为(N, 50257)的 logits 张量(以 GPT-2 为例),其中 50,257 是模型的词表大小。这个 logits 张量表示的是每个位置上所有可能下一个 token 的未归一化预测得分。词表中的每一个 token 都会获得一个分数,这些分数可以排序,用于判断在当前上下文中哪些 token 最有可能被预测出来。某个位置上生成的 logits 可能类似如下:
array([-114.83902718, -111.23177705, -116.58203861, ..., -118.4023539 ,
-118.92616557, -113.37047973], shape=(50257,))
对于自回归生成任务,我们通常只关心在当前序列末尾预测下一个 token。通过选取 logits 中对应最后一个位置的得分,并使用如 argmax 这样的操作,我们就可以找出最有可能出现的下一个 token:
next_token = np.argmax(logits[-1, :])
然后,我们可以将这个 token ID 添加到序列中,并重复这一过程,逐个生成文本。但为了使这种方法有效,我们需要从预训练的权重中加载正确初始化的模型参数,这也引出了我们的下一个话题。
Safetensors 和模型参数
要使用像 GPT-2 这样的预训练模型,我们需要有效地加载和组织它们的参数。本文将解释如何使用 safetensors 格式来结构化和加载这些参数,这是一种安全高效的存储模型权重的方法。为此,我们从 HuggingFace 加载它们,这些权重存储在 model.safetensors 文件中。
Safetensors 是一种快速且安全的格式(即它不使用 Pickle,Pickle 需要执行任意代码),用于存储张量。该格式采用简单的 key/value 结构,其中 key 是表示张量名称的 UTF-8 编码字符串(例如 model.layers.0.attention.weight),value 是包含形状和数据类型信息的固定头部的二进制张量数据,文件开头的元数据部分包含所有张量及其偏移量的索引。
在内部,GPT-2 的模型参数以以下 key/value 格式存储:
{
"wpe.weight": np.array([1024, 768]),
"wte.weight": np.array([50257, 768]),
...
"h.0.attn.bias": np.array([1, 1, 1024, 1024]),
"h.0.attn.c_attn.bias": np.array([2304]),
"h.0.attn.c_attn.weight": np.array([768, 2304]),
"h.0.attn.c_proj.bias": np.array([768]),
"h.0.attn.c_proj.weight": np.array([768, 768]),
"h.0.ln_1.bias": np.array([768]),
"h.0.ln_1.weight": np.array([768]),
"h.0.ln_2.bias": np.array([768]),
"h.0.ln_2.weight": np.array([768]),
"h.0.mlp.c_fc.bias": np.array([3072]),
"h.0.mlp.c_fc.weight": np.array([768, 3072]),
"h.0.mlp.c_proj.bias": np.array([768]),
"h.0.mlp.c_proj.weight": np.array([3072, 768]),
...
"ln_f.bias": np.array([768]),
"ln_f.weight": np.array([768])
}
这些都是带有形状(shape)和数据类型(dtype)的张量,表示模型中各个组件的已学习参数,是模型训练过程的最终结果。
LayerNormParams 这个数据类表示的是层归一化(Layer Normalization)的参数,包括每一层的缩放因子(g)和偏置项(b)。
@dataclass
class LayerNormParams:
g: np.ndarray # Gamma (scale)
b: np.ndarray # Beta (bias)
LinearParams 数据类表示线性映射的参数,包括一个权重矩阵(w)和一个偏置向量(b)。
@dataclass
class LinearParams:
w: np.ndarray # Weight matrix
b: np.ndarray # Bias vector
MLPParams 数据类表示前馈网络的参数,包括两个线性层:第一个线性层(c_fc)和第二个线性层(c_proj)。
@dataclass
class MLPParams:
c_fc: LinearParams # First linear layer
c_proj: LinearParams # Second linear layer
AttentionParams 数据类表示注意力机制的参数,包括 query-key-value 映射(c_attn)和输出映射(c_proj)。
@dataclass
class AttentionParams:
c_attn: LinearParams # QKV projection
c_proj: LinearParams # Output projection
TransformerBlockParams 数据类表示一个单独的 Transformer 块,包括一个层归一化(ln_1)、一个前馈网络(mlp)、一个注意力机制(attn)和第二个层归一化(ln_2)。
@dataclass
class TransformerBlockParams:
ln_1: LayerNormParams # First layer norm
ln_2: LayerNormParams # Second layer norm
mlp: MLPParams # MLP block
attn: AttentionParams # Attention block
ModelParams 数据类表示完整的模型参数,包括一个词嵌入矩阵(wte)、一个位置嵌入矩阵(wpe)、一系列 Transformer 块(blocks)以及最终的层归一化(ln_f)。
@dataclass
class ModelParams:
wte: np.ndarray # Token embeddings
wpe: np.ndarray # Position embeddings
blocks: List[TransformerBlockParams] # Transformer blocks
ln_f: LayerNormParams # Final layer norm
HParams 数据类表示模型的超参数,包括 Transformer 层的数量(n_layer)、注意力头的数量(n_head)和上下文长度(n_ctx)。
@dataclass
class HParams:
n_layer: int # Number of transformer layers
n_head: int # Number of attention heads
n_ctx: int # Context length
我们可以使用 safe_open 函数从 model.safetensors 文件加载模型参数。这个文件可以从 Hugging Face 模型库下载,https://huggingface.co/openai-community/gpt2 。
tensors = {}
with safe_open(weights_path, framework="numpy") as f:
for key in f.keys():
tensors[key] = f.get_tensor(key)
# Build transformer blocks
blocks = []
for i in range(config["n_layer"]):
prefix = f"h.{i}"
block = TransformerBlockParams(
ln_1=LayerNormParams(
g=tensors[f"{prefix}.ln_1.weight"], b=tensors[f"{prefix}.ln_1.bias"]
),
ln_2=LayerNormParams(
g=tensors[f"{prefix}.ln_2.weight"], b=tensors[f"{prefix}.ln_2.bias"]
),
mlp=MLPParams(
c_fc=LinearParams(
w=tensors[f"{prefix}.mlp.c_fc.weight"],
b=tensors[f"{prefix}.mlp.c_fc.bias"],
),
c_proj=LinearParams(
w=tensors[f"{prefix}.mlp.c_proj.weight"],
b=tensors[f"{prefix}.mlp.c_proj.bias"],
),
),
attn=AttentionParams(
c_attn=LinearParams(
w=tensors[f"{prefix}.attn.c_attn.weight"],
b=tensors[f"{prefix}.attn.c_attn.bias"],
),
c_proj=LinearParams(
w=tensors[f"{prefix}.attn.c_proj.weight"],
b=tensors[f"{prefix}.attn.c_proj.bias"],
),
),
)
blocks.append(block)
# Build final model params
params = ModelParams(
wte=tensors["wte.weight"],
wpe=tensors["wpe.weight"],
blocks=blocks,
ln_f=LayerNormParams(g=tensors["ln_f.weight"], b=tensors["ln_f.bias"]),
)
贪婪解码(Greedy Decoding)
模型架构已定义且参数加载完成,现在我们可以将所有内容整合在一起,开始生成文本。最简单的文本生成方法是贪婪解码,在每一步,我们只需选择模型预测的概率最高的 token。
下面的 generate 函数封装了整个文本生成过程,从编码初始提示语到迭代生成新 tokens。这个函数展示了我们所探讨的所有组件——分词、嵌入、Transformer 块和词汇投影——是如何协同工作以创建一个功能完整的语言模型的。
def generate(prompt: str, n_tokens_to_generate: int = 40) -> str:
encoder = get_encoder("", "model")
params, hparams = load_gpt2_weights()
input_ids = encoder.encode(prompt)
generated_token_ids: list[int] = []
print(prompt, end="", flush=True)
current_ids = list(input_ids)
for _ in range(n_tokens_to_generate):
logits = gpt2(current_ids, params, n_head=hparams.n_head)
next_id = np.argmax(logits[-1, :])
next_id_int = int(next_id)
current_ids.append(next_id_int)
generated_token_ids.append(next_id_int)
token_text = encoder.decode([next_id_int])
print(token_text, end="", flush=True)
print()
return encoder.decode(generated_token_ids)
生成过程从使用我们的 BPE 分词器将用户的提示编码为 token ID 开始。我们初始化一个空列表,用来跟踪我们将要生成的 token。然后,我们进入一个循环,在每次迭代中,我们:
- 将当前的 token ID 序列(包括原始提示和所有已生成的 token)输入到 GPT-2 模型中;
- 提取最后一个 token 位置的 logits,这些 logits 代表模型对接下来会出现的内容的预测;
- 对这些 logits 取 argmax,选择最有可能的下一个 token;
- 将这个新 token 添加到我们的生成 token 列表中,并更新当前序列;
- 解码并打印新 token,实时显示生成过程。
生成所请求的 token 数量后,我们将生成的 token 序列解码回文本并返回。这样就完成了实现一个简单版本 GPT-2 模型的全部过程。我们只需要实现大约六个“核心”操作(softmax、gelu、layer_norm、linear、add、matmul、var、mean),其余部分只是一些用于处理数据结构的管理工作。
但正如你所注意到的,这个模型非常慢且低效,在现代 CPU 上的生成速度大约为每秒 2-3 个 token。通过将其降级为 MLIR 和 PTX,我们可以通过融合和并行化来提高效率,接下来的部分我们将会深入探讨这些优化方法。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 8223
8223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









